数据集下载地址:
链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw
提取码:2xq4
创建数据集:https://www.cnblogs.com/xiximayou/p/12398285.html
读取数据集:https://www.cnblogs.com/xiximayou/p/12422827.html
进行训练:https://www.cnblogs.com/xiximayou/p/12448300.html
保存模型并继续进行训练:https://www.cnblogs.com/xiximayou/p/12452624.html
加载保存的模型并测试:https://www.cnblogs.com/xiximayou/p/12459499.html
划分验证集并边训练边验证:https://www.cnblogs.com/xiximayou/p/12464738.html
使用学习率衰减策略并边训练边测试:https://www.cnblogs.com/xiximayou/p/12468010.html
利用tensorboard可视化训练和测试过程:https://www.cnblogs.com/xiximayou/p/12482573.html
从命令行接收参数:https://www.cnblogs.com/xiximayou/p/12488662.html
使用top1和top5准确率来衡量模型:https://www.cnblogs.com/xiximayou/p/12489069.html
使用预训练的resnet18模型:https://www.cnblogs.com/xiximayou/p/12504579.html
计算数据集的平均值和方差:https://www.cnblogs.com/xiximayou/p/12507149.html
epoch、batchsize、step之间的关系:https://www.cnblogs.com/xiximayou/p/12405485.html
pytorch读取数据集有两种方式,本节介绍第二种方式。
存储数据集的目录结构是:

首先,我们需要将图片的路径和标签存储到txt文件中,在utils下新建一个Img_to_txt.py文件
import os from glob import glob root="/content/drive/My Drive/colab notebooks/data/dogcat/" train_path=root+"train" val_path=root+"val" test_path=root+"test" def img_to_txt(path): tmp=path.strip().split("/")[-1] filename=tmp+".txt" with open(filename,'a',encoding="utf-8") as fp: i=0 for f in sorted(os.listdir(path)): for image in glob(path+"/"+str(f)+"/*.jpg"): fp.write(image+" "+str(i)+" ") i+=1 img_to_txt(train_path) #img_to_txt(val_path)#img_to_txt(test_path)
其中os.listdir()用于获取路径下的文件夹列表,['cat','dog']。glob()用于获取目录下的所有匹配的文件。为了能够按顺序对类别进行数字标记,需要对目录列表进行排序。然后我们将cat标记为0,dog标记为1。并将图片对应的路径和标签加入到txt中。
运行之后得到类似的结果:
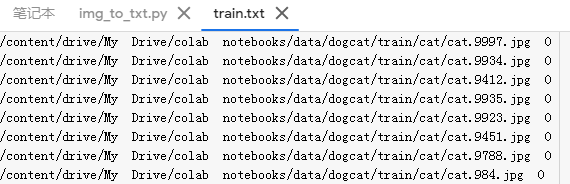
然后我们要实现自己定义的数据集类,需要继承Dataset类,并重写__getitem__()和__len__()方法 :在utils下新建一个read_from_txt.py文件
from torch.utils.data import Dataset from PIL import Image class Dogcat(Dataset): def __init__(self,txt_path,transform=None,target_transform=None): super(Dogcat,self).__init__() self.txt_path=txt_path self.transform=transform self.target_transform=target_transform fp=open(txt_path,'r') imgs=[] for line in fp: line=line.strip().split() #print(line) img=line[0]+" "+line[1]+" "+line[2] #['/content/drive/My', 'Drive/colab', 'notebooks/data/dogcat/train/cat/cat.9997.jpg', '0'] #imgs.append((line[0],int(line[-1]))) imgs.append((img,int(line[-1]))) self.imgs=imgs def __getitem__(self,index): image,label=self.imgs[index] image=Image.open(image).convert('RGB') if self.transform is not None: image=self.transform(image) return image,label def __len__(self): return len(self.imgs)
由于我们的路径中含有空格,在截取图像的路径和标签时需要注意。
之后在rdata.py中
from torch.utils.data import DataLoader import torchvision import torchvision.transforms as transforms import torch from utils import read_from_txt def load_dataset_from_dataset(batch_size): #预处理 print(batch_size) train_transform = transforms.Compose([transforms.RandomResizedCrop(224),transforms.ToTensor()]) val_transform = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor()]) test_transform = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor()]) root="/content/drive/My Drive/colab notebooks/utils/" train_loader = DataLoader(read_from_txt.Dogcat(root+"train.txt",train_transform), batch_size=batch_size, shuffle=True, num_workers=6) val_loader = DataLoader(read_from_txt.Dogcat(root+"val.txt",val_transform), batch_size=batch_size, shuffle=True, num_workers=6) test_loader = DataLoader(read_from_txt.Dogcat(root+"test.txt",test_transform), batch_size=batch_size, shuffle=True, num_workers=6) return train_loader,val_loader,test_loader
然后在main.py中就可以使用了。
train_loader,val_loader,test_loader=rdata.load_dataset_from_dataset(batch_size)
报错了查看下train.txt发现有重复命名的文件,将这些重复的文件进行删除。

最后运行:

最后到这报错了:

图像地址都还没读取完毕就加入到DataLoader中了?线程不安全?还未找到解决方法。不过总体上创建数据集的过程就是这样的。