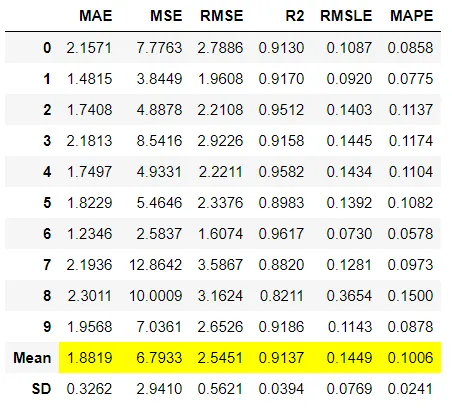
1、集成模型
组装训练好的模型就像编写ensemble_model一样简单。它仅采用一个强制性参数,即经过训练的模型对象。此函数返回一个表,该表具有k倍的通用评估指标的交叉验证分数以及训练有素的模型对象。使用的评估指标是:
分类:准确性,AUC,召回率,精度,F1,Kappa,MCC
回归:MAE,MSE,RMSE,R2,RMSLE,MAPE
可以使用ensemble_model函数中的fold参数定义折叠次数。默认情况下,折叠倍数设置为10。默认情况下,所有指标均四舍五入到4位小数,可以使用round参数进行更改。有两种可用于合奏的方法,可以使用ensemble_model函数中的method参数设置。这两种方法都需要对数据进行重新采样并拟合多个估计量,因此可以使用n_estimators参数来控制估计量的数量。默认情况下,n_estimators设置为10。
该函数仅在pycaret.classification和pycaret.regression模块中可用。
Bagging:Bagging,也称为Bootstrap聚合,是一种机器学习集成元算法,旨在提高统计分类和回归中使用的机器学习算法的稳定性和准确性。 它还可以减少差异并有助于避免过度拟合。 尽管它通常应用于决策树方法,但可以与任何类型的方法一起使用。 套袋是模型平均方法的特例。
Boosting:Boosting是一种集成元算法,主要用于减少监督学习中的偏见和差异。 提升属于机器学习算法家族,可将弱学习者转化为强学习者。 弱学习者被定义为仅与真实分类略相关的分类器(它可以比随机猜测更好地标记示例)。 相反,学习能力强的分类器是与真实分类任意相关的分类器。
分类例子:
from pycaret.datasets import get_data diabetes = get_data('diabetes') # Importing module and initializing setup from pycaret.classification import * clf1 = setup(data = diabetes, target = 'Class variable') # train a decision tree model dt = create_model('dt') # train a bagging classifier on dt bagged_dt = ensemble_model(dt, method = 'Bagging') # train a adaboost classifier on dt with 100 estimators boosted_dt = ensemble_model(dt, method = 'Boosting', n_estimators = 100)
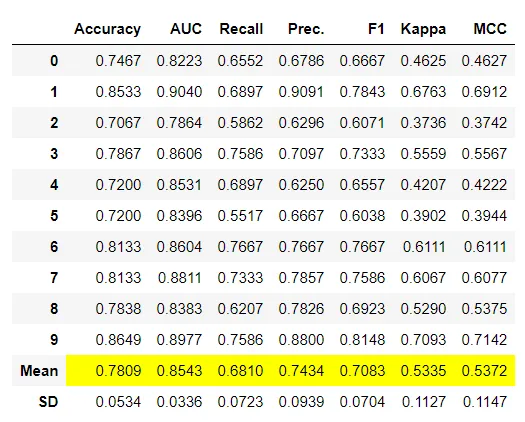
回归例子:
from pycaret.datasets import get_data boston = get_data('boston') # Importing module and initializing setup from pycaret.regression import * reg1 = setup(data = boston, target = 'medv') # train a decision tree model dt = create_model('dt') # train a bagging classifier on dt bagged_dt = ensemble_model(dt, method = 'Bagging') # train a adaboost classifier on dt with 100 estimators boosted_dt = ensemble_model(dt, method = 'Boosting', n_estimators = 100)
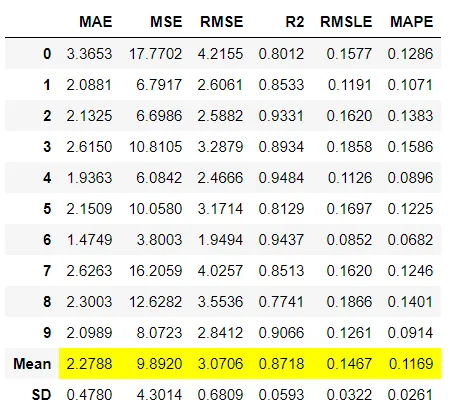
2、混合模型
混合模型是一种集合方法,它使用估算器之间的共识来生成最终预测。融合的思想是结合不同的机器学习算法,并在分类的情况下使用多数投票或平均预测概率来预测最终结果。在PyCaret中混合模型就像编写blend_models一样简单。此函数可用于混合可以使用blend_models中的estimator_list参数传递的特定训练模型,或者如果未传递列表,它将使用模型库中的所有模型。在分类的情况下,方法参数可用于定义“软”或“硬”,其中软使用预测的概率进行投票,而硬使用预测的标签。此函数返回一个表,该表具有k倍的通用评估指标的交叉验证分数以及训练有素的模型对象。使用的评估指标是:
分类:准确性,AUC,召回率,精度,F1,Kappa,MCC
回归:MAE,MSE,RMSE,R2,RMSLE,MAPE
可以使用blend_models函数中的fold参数定义折叠次数。默认情况下,折叠倍数设置为10。默认情况下,所有指标均四舍五入到4位小数,可以使用blend_models中的round参数进行更改。
该函数仅在pycaret.classification和pycaret.regression模块中可用。
分类例子:
# Importing dataset from pycaret.datasets import get_data diabetes = get_data('diabetes') # Importing module and initializing setup from pycaret.classification import * clf1 = setup(data = diabetes, target = 'Class variable') # train a votingclassifier on all models in library blender = blend_models() # train a voting classifier on specific models dt = create_model('dt') rf = create_model('rf') adaboost = create_model('ada') blender_specific = blend_models(estimator_list = [dt,rf,adaboost], method = 'soft') # train a voting classifier dynamically blender_specific = blend_models(estimator_list = compare_models(n_select = 5), method = 'hard')
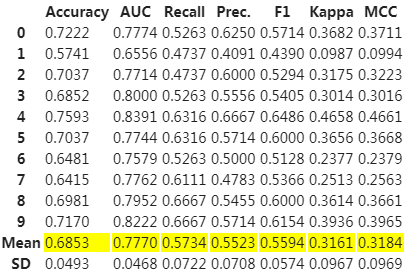
回归例子:
# Importing dataset from pycaret.datasets import get_data boston = get_data('boston') # Importing module and initializing setup from pycaret.regression import * reg1 = setup(data = boston, target = 'medv') # train a voting regressor on all models in library blender = blend_models() # train a voting regressoron specific models dt = create_model('dt') rf = create_model('rf') adaboost = create_model('ada') blender_specific = blend_models(estimator_list = [dt,rf,adaboost]) # train a voting regressor dynamically blender_specific = blend_models(estimator_list = compare_models(n_select = 5))
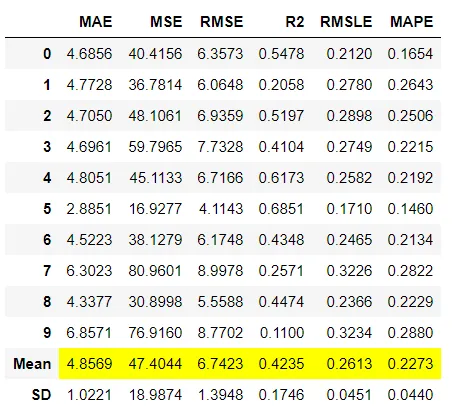
3、堆叠模型
堆叠模型是使用元学习的整合方法。堆叠背后的想法是建立一个元模型,该模型使用多个基本估计量的预测来生成最终预测。在PyCaret中堆叠模型就像编写stack_models一样简单。此函数使用estimator_list参数获取训练模型的列表。所有这些模型构成了堆栈的基础层,它们的预测用作元模型的输入,可以使用meta_model参数传递该元模型。如果未传递任何元模型,则默认情况下使用线性模型。在分类的情况下,方法参数可用于定义“软”或“硬”,其中软使用预测的概率进行投票,而硬使用预测的标签。该函数返回一个表,该表具有经过共同验证的指标的k倍交叉验证得分以及训练有素的模型对象。使用的评估指标是:
分类:准确性,AUC,召回率,精度,F1,Kappa,MCC
回归:MAE,MSE,RMSE,R2,RMSLE,MAPE
可以使用stack_models函数中的fold参数定义折叠次数。默认情况下,折叠倍数设置为10。默认情况下,所有指标均四舍五入到4位小数,可以使用stack_models中的round参数进行更改。 restack参数控制将原始数据公开给元模型的能力。默认情况下,它设置为True。当更改为False时,元模型将仅使用基本模型的预测来生成最终预测。
多层堆叠
基本模型可以在单层或多层中,在这种情况下,来自每个先前层的预测将作为输入传递到下一层,直到到达元模型,其中将包括基本层在内的所有层的预测用作输入 产生最终的预测。 要多层堆叠模型,create_stacknet函数接受estimator_list参数作为列表中的列表。 所有其他参数都相同。 请参见以下使用create_stacknet函数的回归示例。
该函数仅在pycaret.classification和pycaret.regression模块中可用。
警告:在以后的PyCaret 2.x发行版中将不建议使用此功能。
分类例子:
# Importing dataset from pycaret.datasets import get_data diabetes = get_data('diabetes') # Importing module and initializing setup from pycaret.classification import * clf1 = setup(data = diabetes, target = 'Class variable') # create individual models for stacking ridge = create_model('ridge') lda = create_model('lda') gbc = create_model('gbc') xgboost = create_model('xgboost') # stacking models stacker = stack_models(estimator_list = [ridge,lda,gbc], meta_model = xgboost) # stack models dynamically top5 = compare_models(n_select = 5) stacker = stack_models(estimator_list = top5[1:], meta_model = top5[0])
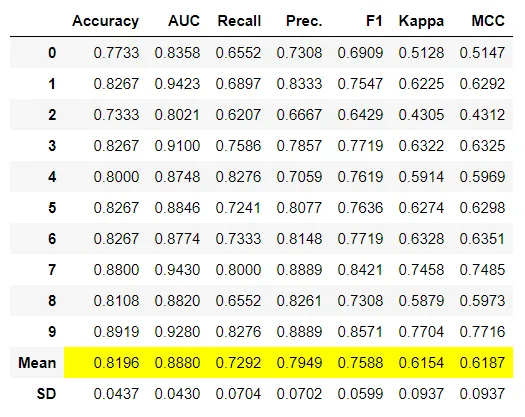
回归例子:
# Importing dataset from pycaret.datasets import get_data boston = get_data('boston') # Importing module and initializing setup from pycaret.regression import * reg1 = setup(data = boston, target = 'medv') # creating multiple models for multiple layer stacking catboost = create_model('catboost') et = create_model('et') lightgbm = create_model('lightgbm') xgboost = create_model('xgboost') ada = create_model('ada') rf = create_model('rf') gbr = create_model('gbr') # creating multiple layer stacking from specific models stacknet = create_stacknet([[lightgbm, xgboost, ada], [et, gbr, catboost, rf]])