1、解释模型
解释复杂模型在机器学习中至关重要。 模型可解释性通过分析模型真正认为的重要内容来帮助调试模型。 在PyCaret中解释模型就像编写interpret_model一样简单。 该函数将训练有素的模型对象和图的类型作为字符串。 解释是基于SHAP(SHapley Additive exPlanations)实现的,并且仅适用于基于树的模型。
该函数仅在pycaret.classification和pycaret.regression模块中可用。
from pycaret.datasets import get_data diabetes = get_data('diabetes') # Importing module and initializing setup from pycaret.classification import * clf1 = setup(data = diabetes, target = 'Class variable') # creating a model xgboost = create_model('xgboost') # interpreting model interpret_model(xgboost)

interpret_model(xgboost, plot = 'correlation')
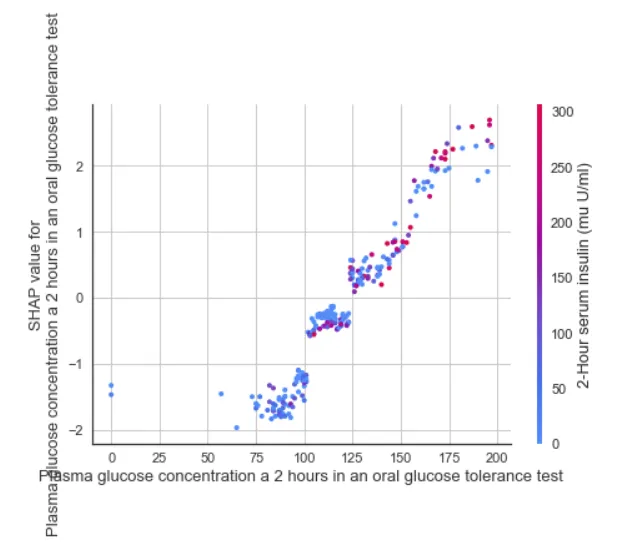
interpret_model(xgboost, plot = 'reason', observation = 10)

2、分配模型
在执行无监督实验(例如聚类,异常检测或自然语言处理)时,您通常会对模型生成的标签感兴趣,例如 数据点所属的群集标识是“群集”实验中的标签。 同样,哪个观察值是异常值,是“异常检测”实验中的二进制标记,而哪个主题文档属于自然语言处理实验中的标记。 这可以在PyCaret中使用assign_model函数实现,该函数将训练有素的模型对象作为单个参数。
此功能仅在pycaret.clustering,pycaret.anomaly和pycaret.nlp模块中可用。
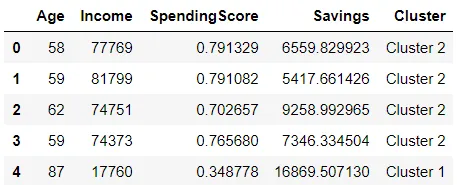
# Importing dataset from pycaret.datasets import get_data jewellery = get_data('jewellery') # Importing module and initializing setup from pycaret.clustering import * clu1 = setup(data = jewellery) # create a model kmeans = create_model('kmeans') # Assign label kmeans_results = assign_model(kmeans)
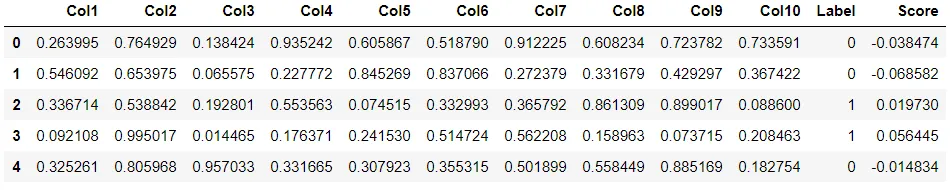
# Importing dataset from pycaret.datasets import get_data anomalies = get_data('anomalies') # Importing module and initializing setup from pycaret.anomaly import * ano1 = setup(data = anomalies) # create a model iforest = create_model('iforest') # Assign label iforest_results = assign_model(iforest)
# Importing dataset from pycaret.datasets import get_data kiva = get_data('kiva') # Importing module and initializing setup from pycaret.nlp import * nlp1 = setup(data = kiva, target = 'en') # create a model lda = create_model('lda') # Assign label lda_results = assign_model(lda)
3、校准模型
在进行分类实验时,您通常不仅希望预测类别标签,而且还希望获得预测的可能性。这种可能性使您充满信心。某些模型可能会使您对类概率的估计不佳。校准良好的分类器是概率分类器,其概率输出可以直接解释为置信度。在PyCaret中校准分类模型就像编写calibrate_model一样简单。这些功能采用经过训练的模型对象和通过方法参数进行校准的方法。方法可以是对应于Platt方法的“ Sigmoid”,也可以是非参数方法的“等渗”。不建议将等渗校准用于校准样品太少(<< 1000),因为它倾向于过拟合。此函数返回一个表格,其中包含经过分类验证指标(准确性,AUC,召回率,精度,F1和Kappa)的k倍交叉验证得分以及受过训练的模型对象。
可以使用calibrate_model函数中的fold参数定义折叠次数。默认情况下,折叠倍数设置为10。默认情况下,所有指标均四舍五入到4位小数,可以使用calibrate_model中的round参数进行更改。
此功能仅在pycaret.classification模块中可用。
# Importing dataset from pycaret.datasets import get_data diabetes = get_data('diabetes') # Importing module and initializing setup from pycaret.classification import * clf1 = setup(data = diabetes, target = 'Class variable') # create a model dt = create_model('dt') # calibrate a model calibrated_dt = calibrate_model(dt)

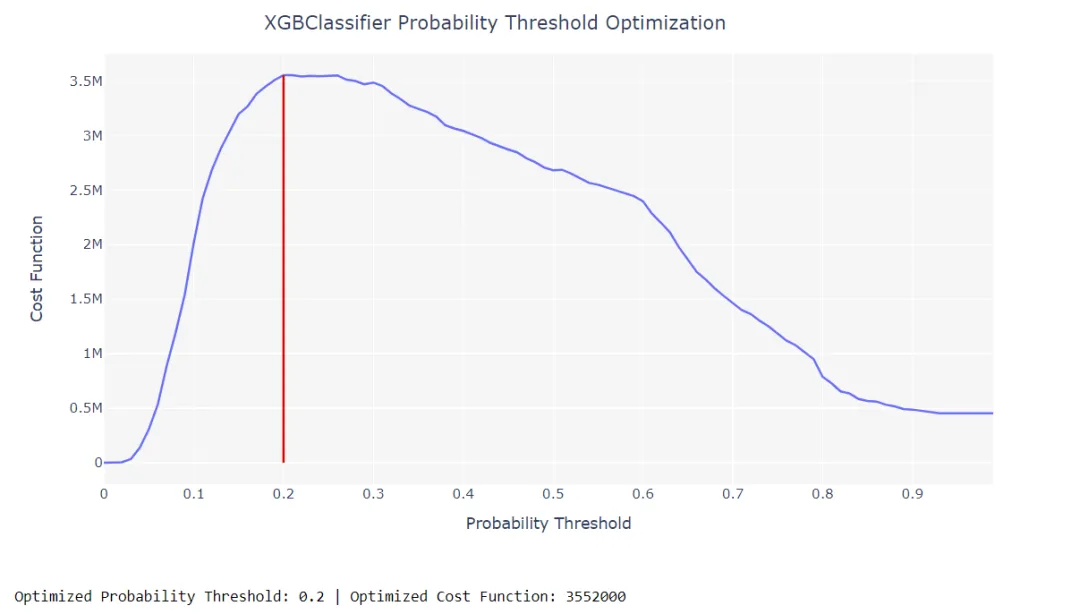
4、优化阈值
在分类问题中,false positives 几乎永远不会与false negatives相同。这样,如果您正在优化类型1和类型2错误产生不同影响的业务问题,则可以通过分别定义 true positives, true negatives, false positives and false negatives损失 来优化分类器的概率阈值,以优化自定义损失函数。在PyCaret中优化阈值就像编写optimize_threshold一样简单。它需要一个训练有素的模型对象(一个分类器),并且损失函数仅由真阳性,真阴性,假阳性和假阴性表示。此函数返回一个交互图,其中损失函数(y轴)表示为x轴上不同概率阈值的函数。然后显示一条垂直线,代表该特定分类器的概率阈值的最佳值。然后,可以将使用optimize_threshold优化的概率阈值用于predict_model函数,以使用自定义概率阈值生成标签。通常,所有分类器都经过训练可以预测50%的阳性分类。
此功能仅在pycaret.classification模块中可用。
# Importing dataset from pycaret.datasets import get_data credit = get_data('credit') # Importing module and initializing setup from pycaret.classification import * clf1 = setup(data = credit, target = 'default') # create a model xgboost = create_model('xgboost') # optimize threshold for trained model optimize_threshold(xgboost, true_negative = 1500, false_negative = -5000)