1.项目简介
本项目实现人脸识别系统。
项目基本思路如下:对于输入的图片,首先通过MTCNN网络进行人脸检测,获取到人脸图片;并使用MTCNN网络检测到的人脸关键点信息通过仿射变换进行人脸对齐;然后使用insightface进行人脸特征提取,比较数据库中的数据,识别出人脸。项目结构如图所示:
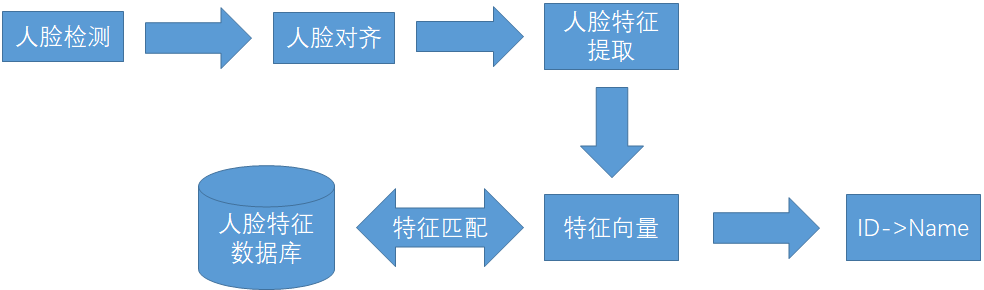
图1 人脸识别系统结构
首先需要训练mtcnn网络,识别人脸检测。MTCNN网络的训练在《基于MTCNN算法的人脸检测》中已经实现,这里直接使用训练好的模型即可。对于insightface在《insightface》中已经对其进行理解,
这里需要对insightface进行训练。
本项目使用的环境为:ubuntu16.04+RTX2070SUPER。
2.项目实现流程
2.1数据处理
2.1.1训练数据处理
项目中使用CASIA-Webface数据,下载后的数据有如下文件:
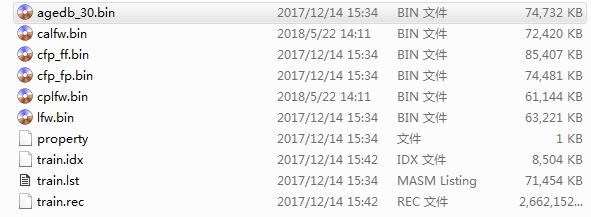
其中,train.idx以及train.rec是用于训练的数据,其余的bin文件都是测试数据集。
首先,创建utils文件夹,里面存放的都是项目使用的公共组件,其中全局的配置在config.py文件中,代码如下:


1 import os 2 3 4 # prepare_data parameters 5 mxdata_dir = "./data" 6 tfrecord_dir = "./data/CASIA.tfrecords" 7 lfw_dir = './data/lfw' 8 lfw_save_dir = './data/lfw_face' 9 eval_dir = './data/lfw_face.db' 10 eval_datasets_self = ['./data/lfw_face.db'] 11 eval_datasets = ["./data/lfw.bin", "./data/agedb_30.bin", "./data/calfw.bin", 12 "./data/cfp_ff.bin", "./data/cfp_fp.bin", "./data/cplfw.bin", './data/lfw_face.db'] 13 14 15 # model parameters 16 model_params = {"backbone_type": "resnet_v2_m_50", 17 "out_type": "E", 18 "bn_decay": 0.9, 19 "weight_decay": 0.0005, 20 "keep_prob": 0.4, 21 "embd_size": 512} 22 23 24 # training parameters 25 s = 64.0 26 m = 0.5 27 class_num = 85742 28 lr_steps = [40000, 60000, 80000] 29 lr_values = [0.004, 0.002, 0.0012, 0.0004] 30 momentum = 0.9 31 addrt = "./data/CASIA.tfrecords" 32 model_patht = "./model/Arcface_model" 33 img_size = 112 34 batch_size = 128 35 addr = "../data/CASIA.tfrecords" 36 model_name = "Arcface" 37 train_step = 1000001 38 model_path = "../model/Arcface_model" 39 gpu_num = 2 40 model_save_gap = 30000 41 42 43 # evaluation parameters 44 eval_dropout_flag = False 45 eval_bn_flag = False 46 47 48 # face database parameters 49 custom_dir = '../data/custom' 50 arc_model_name = 'Arcface-330000' 51 arc_model_path = './model/Arcface_model/Arcface-330000' 52 53 base_dir = './model/MTCNN_model' 54 mtcnn_model_path = [os.path.join(base_dir, "Pnet_model/Pnet_model.ckpt-20000"), 55 os.path.join(base_dir, "Rnet_model/Rnet_model.ckpt-40000"), 56 os.path.join(base_dir, "Onet_model/Onet_model.ckpt-40000")] 57 embds_save_dir = "../data/face_db"
因为数据是以mxnet格式存储的,因此首先需要将数据转换成TFrecord格式,在项目根目录下创建gen_tfrecord_mxdata.py文件,代码如下:
1 import tensorflow as tf 2 import mxnet as mx 3 import os 4 import io 5 import numpy as np 6 import cv2 7 import time 8 from scipy import misc 9 import argparse 10 from utils import config 11 12 13 def arg_parse(): 14 15 parser = argparse.ArgumentParser() 16 parser.add_argument("--read_dir", default=config.mxdata_dir, type=str, help='directory to read data') 17 parser.add_argument("--save_dir", default=config.tfrecord_dir, type=str, help='path to save TFRecord file') 18 19 return parser.parse_args() 20 21 22 def main(): 23 24 with tf.python_io.TFRecordWriter(save_dir) as writer: 25 idx_path = os.path.join(read_dir, 'train.idx') 26 bin_path = os.path.join(read_dir, 'train.rec') 27 imgrec = mx.recordio.MXIndexedRecordIO(idx_path, bin_path, 'r') 28 s = imgrec.read_idx(0) 29 header, _ = mx.recordio.unpack(s) 30 imgidx = list(range(1, int(header.label[0]))) 31 labels = [] 32 for i in imgidx: 33 img_info = imgrec.read_idx(i) 34 header, img = mx.recordio.unpack(img_info) 35 label = int(header.label) 36 labels.append(label) 37 img = io.BytesIO(img) 38 img = misc.imread(img).astype(np.uint8) 39 img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) 40 img_raw = img.tobytes() 41 42 example = tf.train.Example(features=tf.train.Features(feature={ 43 "img": tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw])), 44 "label": tf.train.Feature(int64_list=tf.train.Int64List(value=[label])), 45 })) 46 47 writer.write(example.SerializeToString()) 48 49 if i % 10000 == 0: 50 print('%d pics processed' % i, "time: ", time.time()-begin) 51 52 53 if __name__ == "__main__": 54 55 parser = arg_parse() 56 57 save_dir = parser.save_dir 58 read_dir = parser.read_dir 59 60 begin = time.time() 61 62 main()
通过以上代码,将mxnet格式的训练数据转换成TFRecord格式的数据,过程如下图所示:

训练数据通过将上述数据输入人脸检测网络(这里使用MTCNN,其中,MTCNN网络的训练参照《MTCNN算法理解及实现》一节),获取人脸图片数据,代码如下:
import sys sys.path.append("../") from core.MTCNN.mtcnn_detector import MTCNN_Detector from core.MTCNN.MTCNN_model import Pnet_model, Rnet_model, Onet_model import numpy as np import os from collections import namedtuple from easydict import EasyDict as edict from scipy import misc import cv2 from collections import namedtuple from core import config import argparse from core.tool import preprocess def arg_parse(): parser = argparse.ArgumentParser() parser.add_argument("--input_dir", default=config.lfw_dir, type=str, help='directory to read lfw data') parser.add_argument("--output_dir", default=config.lfw_save_dir, type=str, help='path to save lfw_face data') parser.add_argument("--image_size", default="112,112", type=str, help='image size') return parser.parse_args() def get_DataSet(input_dir, min_images=1): ret = [] label = 0 person_names = [] for person_name in os.listdir(input_dir): person_names.append(person_name) person_names = sorted(person_names) for person_name in person_names: _subdir = os.path.join(input_dir, person_name) if not os.path.isdir(_subdir): continue _ret = [] for img in os.listdir(_subdir): fimage = edict() fimage.id = os.path.join(person_name, img) fimage.classname = str(label) fimage.image_path = os.path.join(_subdir, img) fimage.bbox = None fimage.landmark = None _ret.append(fimage) if len(_ret)>=min_images: ret += _ret label+=1 return ret def main(args): dataset = get_DataSet(args.input_dir) print('dataset size', 'lfw', len(dataset)) print('Creating networks and loading parameters') if(model_name in ["Pnet","Rnet","Onet"]): model[0]=Pnet_model if(model_name in ["Rnet","Onet"]): model[1]=Rnet_model if(model_name=="Onet"): model[2]=Onet_model detector=MTCNN_Detector(model,model_path,batch_size,factor,min_face_size,threshold) if not os.path.exists(args.output_dir): os.makedirs(args.output_dir) output_filename = os.path.join(args.output_dir, 'lfw_list') print('begin to generate') with open(output_filename, "w") as text_file: nrof_images_total = 0 nrof = np.zeros( (2,), dtype=np.int32) for fimage in dataset: if nrof_images_total%100==0: print("Processing %d, (%s)" % (nrof_images_total, nrof)) nrof_images_total += 1 image_path = fimage.image_path if not os.path.exists(image_path): print('image not found (%s)'%image_path) continue try: img = cv2.imread(image_path) except (IOError, ValueError, IndexError) as e: errorMessage = '{}: {}'.format(image_path, e) print(errorMessage) else: _paths = fimage.image_path.split('/') a,b = _paths[-2], _paths[-1] target_dir = os.path.join(args.output_dir, a) if not os.path.exists(target_dir): os.makedirs(target_dir) target_file = os.path.join(target_dir, b) _bbox = None _landmark = None bounding_boxes, points = detector.detect_single_face(img,False) nrof_faces = np.shape(bounding_boxes)[0] if nrof_faces>0: det = bounding_boxes[:,0:4] img_size = np.asarray(img.shape)[0:2] bindex = 0 if nrof_faces>1: #select the center face according to the characterize of lfw bounding_box_size = (det[:,2]-det[:,0])*(det[:,3]-det[:,1]) img_center = img_size / 2 offsets = np.vstack([ (det[:,0]+det[:,2])/2-img_center[1], (det[:,1]+det[:,3])/2-img_center[0] ]) offset_dist_squared = np.sum(np.power(offsets,2.0),0) bindex = np.argmax(bounding_box_size-offset_dist_squared*2.0) # some extra weight on the centering _bbox = bounding_boxes[bindex, 0:4] _landmark = points[bindex, :] nrof[0]+=1 else: nrof[1]+=1 warped = preprocess(img, bbox=_bbox, landmark = _landmark, image_size=args.image_size) cv2.imwrite(target_file, warped) oline = '%d %s %d ' % (1,target_file, int(fimage.classname)) text_file.write(oline) print('end to generate') if __name__=="__main__": model=[None,None,None] #原文参数 factor=0.79 threshold=[0.8,0.8,0.6] min_face_size=20 #原文参数 batch_size=1 model_name="Onet" base_dir="." model_path=[os.path.join(base_dir,"/home/sxj/DL/insightface/Insightface-tensorflow/model/MTCNN_model/Pnet_model/Pnet_model.ckpt-20000"), os.path.join(base_dir,"/home/sxj/DL/insightface/Insightface-tensorflow/model/MTCNN_model/Rnet_model/Rnet_model.ckpt-40000"), os.path.join(base_dir,"/home/sxj/DL/insightface/Insightface-tensorflow/model/MTCNN_model/Onet_model/Onet_model.ckpt-40000")] args=arg_parse() main(args)
执行代码,得到训练数据文件:

这里已经使用preprocessiong操作对检测出的人脸进行人脸关键点进行人脸对齐。
通过上述获得的图像数据,训练arcface网络。
arcface网络的结构是:输入的图像数据通过基础CNN网络(这里使用的是Resnet网络),然后连接Arc loss,得到的结果通过one_hot预测结果,然后和label值进行比较,得到loss,然后进行网络训练。
这里为了防止过拟合,增加了正则化。
训练代码如下,这里使用RTX2070SPUER显卡,其中batch_size设置为32:
# -*- coding: utf-8 -*- """ @author: friedhelm """ import sys sys.path.append("../") import tensorflow as tf from train_tool import arcface_loss,read_single_tfrecord from core import Arcface_model,config import time import os def train(image,label,train_phase_dropout,train_phase_bn): train_images,train_labels=read_single_tfrecord(addr,batch_size,img_size) train_images = tf.identity(train_images, 'input_images') train_labels = tf.identity(train_labels, 'labels') net, end_points = Arcface_model.get_embd(image, train_phase_dropout, train_phase_bn,config.model_params) logit=arcface_loss(net,label,config.s,config.m) arc_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits = logit , labels = label)) # arc_loss = tf.reduce_mean(tf.losses.sparse_softmax_cross_entropy(logits=logit, labels=label)) L2_loss=tf.reduce_sum(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)) with tf.name_scope('loss'): train_loss=arc_loss+L2_loss tf.summary.scalar('train_loss',train_loss) global_step = tf.Variable(name='global_step', initial_value=0, trainable=False) inc_op = tf.assign_add(global_step, 1, name='increment_global_step') scale = int(128.0/batch_size) lr_steps = [scale*s for s in config.lr_steps] lr_values = [v/scale for v in config.lr_values] lr = tf.train.piecewise_constant(global_step, boundaries=lr_steps, values=lr_values, name='lr_schedule') update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) with tf.control_dependencies(update_ops): train_op = tf.train.MomentumOptimizer(learning_rate=lr, momentum=config.momentum).minimize(train_loss) with tf.name_scope('accuracy'): labela = tf.one_hot(label, config.class_num) train_accuracy=tf.reduce_mean(tf.cast(tf.equal(tf.to_int32(tf.argmax(tf.nn.softmax(logit), axis=1)), label),tf.float32)) tf.summary.scalar('train_accuracy',train_accuracy) saver=tf.train.Saver(max_to_keep=5) merged=tf.summary.merge_all() with tf.Session() as sess: sess.run((tf.global_variables_initializer(), tf.local_variables_initializer())) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess,coord=coord) writer_train=tf.summary.FileWriter("../model/%s"%(model_name),sess.graph) try: for i in range(1,train_step): image_batch,label_batch=sess.run([train_images,train_labels]) sess.run([train_op,inc_op],feed_dict={image:image_batch,label:label_batch,train_phase_dropout:True,train_phase_bn:True}) if(i%100==0): summary=sess.run(merged,feed_dict={image:image_batch,label:label_batch,train_phase_dropout:True,train_phase_bn:True}) writer_train.add_summary(summary,i) if(i%1000==0): print('次数',i) print('train_accuracy',sess.run(train_accuracy,feed_dict={image:image_batch,label:label_batch,train_phase_dropout:True,train_phase_bn:True})) print('train_loss',sess.run(train_loss,{image:image_batch,label:label_batch,train_phase_dropout:True,train_phase_bn:True})) print('time',time.time()-begin) if(i%10000==0): saver.save(sess,os.path.join(model_path,model_name),global_step=i) except tf.errors.OutOfRangeError: print("finished") finally: coord.request_stop() writer_train.close() coord.join(threads) def main(): with tf.name_scope('input'): image=tf.placeholder(tf.float32,[batch_size,img_size,img_size,3],name='image') label=tf.placeholder(tf.int32,[batch_size],name='label') train_phase_dropout = tf.placeholder(dtype=tf.bool, shape=None, name='train_phase_dropout') train_phase_bn = tf.placeholder(dtype=tf.bool, shape=None, name='train_phase_bn') train(image,label,train_phase_dropout,train_phase_bn) if __name__ == "__main__": img_size=config.img_size batch_size=config.batch_size addr=config.addr model_name=config.model_name train_step=config.train_step model_path=config.model_path begin=time.time() main()
训练过程如下:

训练完成之后,需要使用训练完成的网络获取数据的人脸数据库。即将图像数据输入网络,获取arcface网络输出的人脸特征emded。
代码如下:
import sys sys.path.append("../") import os import cv2 import numpy as np from recognizer.arcface_recognizer import Arcface_recognizer import pymysql import argparse from core import config from collections import namedtuple def arg_parse(): parser=argparse.ArgumentParser() parser.add_argument("--input_dir", default=config.custom_dir, type=str, help='directory to read lfw data') parser.add_argument("--output_dir", default=config.embds_save_dir, type=str, help='directory to save embds') parser.add_argument("--arc_model_name", default=config.arc_model_name, type=str, help='arcface model name') parser.add_argument("--arc_model_path", default=config.arc_model_path, type=str, help='directory to read arcface model') parser.add_argument("--mtcnn_model_path", default=config.mtcnn_model_path, type=str, help='directory to read MTCNN model') return parser.parse_args() def main(args): recognizer = Arcface_recognizer(args.arc_model_name, args.arc_model_path, args.mtcnn_model_path) label = 0 input_lists = os.listdir(args.input_dir) print(input_lists) embds = np.zeros((len(input_lists), 1, 512)) l2_embds = np.zeros((len(input_lists), 1, 512)) for idx, person_name in enumerate(input_lists): _subdir = os.path.join(args.input_dir, person_name) _subdir = args.input_dir # if not os.path.isdir(_subdir): # print(_subdir) # continue num = 0.0 print(person_name) embd_tp_save = np.zeros((1,512)) for img_name in os.listdir(_subdir): image_path = os.path.join(_subdir, img_name) img = cv2.imread(image_path) embd, bounding_boxes = recognizer.get_embd(img) if embd is None: continue nrof_faces = np.shape(bounding_boxes)[0] if nrof_faces>1: #select the center face according to the characterize of lfw det = bounding_boxes[:,0:4] img_size = np.asarray(img.shape)[0:2] bounding_box_size = (det[:,2]-det[:,0])*(det[:,3]-det[:,1]) img_center = img_size / 2 offsets = np.vstack([ (det[:,0]+det[:,2])/2-img_center[1], (det[:,1]+det[:,3])/2-img_center[0] ]) offset_dist_squared = np.sum(np.power(offsets,2.0),0) bindex = np.argmax(bounding_box_size-offset_dist_squared*2.0) # some extra weight on the centering embd = embd[bindex] num += 1 embd_tp_save += embd embd_tp_save /= num if (embd_tp_save == np.zeros((1,512))).all(): print(person_name+"has no face to detect") continue embds[idx,:] = embd_tp_save l2_embds[idx,:] = embd_tp_save/np.linalg.norm(embd_tp_save, axis=1, keepdims=True) # num represents numbers of embd,label represents the column number sql = "INSERT INTO face_data(FaceName,EmbdNums, ColumnNum) VALUES ('%s', %.4f, %d)"%(person_name, num, label) try: cursor.execute(sql) db.commit() except: db.rollback() raise Exception('''mysql "INSERT" action error in label %d"'''%(label)) label += 1 np.save(args.output_dir+"/l2_embds.npy", l2_embds) np.save(args.output_dir+"/embds.npy", embds) if __name__ == "__main__": db = pymysql.connect(host="localhost", user="sxj", password="1234", port=3306, charset="utf8") cursor = db.cursor() cursor.execute("DROP DATABASE IF EXISTS face_db") cursor.execute("CREATE DATABASE IF NOT EXISTS face_db") cursor.execute("use face_db;") cursor.execute("alter database face_db character set gbk;") cursor.execute("CREATE TABLE IF NOT EXISTS face_data(FaceName VARCHAR(50), EmbdNums INT, ColumnNum INT);") #User = namedtuple('User', ['input_dir', 'arc_model_name', 'arc_model_path', 'mtcnn_model_path', "output_dir"]) #args = User(input_dir=config.custom_dir, arc_model_name=config.arc_model_name, arc_model_path=config.arc_model_path, mtcnn_model_path=config.mtcnn_model_path, output_dir=config.embds_save_dir) args = arg_parse() main(args) cursor.close()
执行脚本得到人脸特征:
最终通过摄像头实时获取图像,进行人脸识别:
将获取得到的图片进行MTCNN网络得到人脸图像,然后输入arcface网络,得到特征,与数据库保存的emded进行比较得到欧式距离误差,如果误差小于设定的阈值,则获取图片中的人物,否则不识别。
最终实验结果如下:

1、为什么使用此结构实现人脸识别:
mtcnn结构比较简单,对于显卡要求比较低,但是其功能很强大,能够很准确地进行人脸检测。而arcface loss能够很好的计算两组人脸特征之间的距离(高的类间距离和低的类内距离)。
仅供学习使用,如有侵权,请联系删除,谢谢!