这是摘自《More Effective C++ 2007》
条款27:要求或禁止在堆中产生对象
要求在堆中建立对象
让我们先从必须在堆中建立对象开始说起。为了执行这种限制,你必须找到一种方法禁止以调用"new"以外的其它手段建立对象。这很容易做到。非堆对象(non-heap object)在定义它的地方被自动构造,在生存时间结束时自动被释放,所以只要禁止使用隐式的构造函数和析构函数,就可以实现这种限制。
把这些调用变得不合法的一种最直接的方法是把构造函数和析构函数声明为 private。这样做副作用太大。没有理由让这两个函数都是 private。最好让析构函数成为 private,让构造函数成为 public。处理过程与条款 26 相似,你可以引进一个专用的伪析构函数,用来访问真正的析构函数。客户端调用伪析构函数释放他们建立的对象。(WQ 加注:注意,异常处理体系要求所有在栈中的对象的析构函数必须申明为公有!)
例如,如果我们想仅仅在堆中建立代表 unlimited precision numbers(无限精确度数字)的对象,可以这样做:
public:
UPNumber();
UPNumber(int initValue);
UPNumber(double initValue);
UPNumber(const UPNumber& rhs);
// 伪析构函数 (一个 const 成员函数, 因为即使是 const 对象也能被释放。)
void destroy() const { delete this; }
...
private:
~UPNumber();
};
然后客户端这样进行程序设计:
UPNumber *p = new UPNumber;//正确
...
delete p;// 错误! 试图调用private 析构函数
p->destroy();// 正确
另一种方法是把全部的构造函数都声明为 private。这种方法的缺点是一个类经常有许多构造函数,类的作者必须记住把它们都声明为 private。否则如果这些函数就会由编译器生成,构造函数包括拷贝构造函数,也包括缺省构造函数;编译器生成的函数总是 public。因此仅仅声明析构函数为 private 是很简单的,因为每个类只有一个析构函数。
通过限制访问一个类的析构函数或它的构造函数来阻止建立非堆对象,但是在条款 26已经说过,这种方法也禁止了继承和包容(containment):
class NonNegativeUPNumber:
public UPNumber { ... };// 错误! 析构函数或构造函数不能编译
class Asset {
private:
UPNumber value;
... // 错误! 析构函数或构造函数不能编译
};
这些困难不是不能克服的。通过把UPNumber的析构函数声明为protected(同时它的构造函数还保持public)就可以解决继承的问题,需要包含UPNumber对象的类可以修改为包含指向UPNumber的指针:
class NonNegativeUPNumber:
public UPNumber { ... };// 现在正确了; 派生类能够访问protected 成员
class Asset {
public:
Asset(int initValue);
~Asset();
...
private:
UPNumber *value;
};
Asset::Asset(int initValue)
: value(new UPNumber(initValue))// 正确
{ ... }
Asset::~Asset()
{ value->destroy(); }// 也正确
判断一个对象是否在堆中
如果我们采取这种方法,我们必须重新审视一下"在堆中"这句话的含义。上述粗略的类定义表明一个非堆的NonNegativeUPNumber对象是合法的:
那么现在NonNegativeUPNumber对象n中的UPNumber部分也不在堆中,这样说对么?答案要依据类的设计和实现的细节而定,但是让我们假设这样说是不对的,所有UPNumber对象 —即使是做为其它派生类的基类—也必须在堆中。我们如何能强制执行这种约束呢?
没有简单的办法。UPNumber的构造函数不可能判断出它是否做为堆对象的基类而被调用。也就是说对于UPNumber的构造函数来说没有办法侦测到下面两种环境的区别:
NonNegativeUPNumber n2;//不在堆中
不过你可能不相信我。也许你想你能够在 new 操作符、operator new 和 new 操作符调用的构造函数的相互作用中玩些小把戏。可能你认为你比他们都聪明,可以这样修改 UPNumber,如下所示:
public:
// 如果建立一个非堆对象,抛出一个异常
class HeapConstraintViolation {};
static void * operator new(size_t size);
UPNumber();
...
private:
static bool onTheHeap;//在构造函数内,指示对象是否被构造在堆上
...
};
// obligatory definition of class static
bool UPNumber::onTheHeap = false;
void *UPNumber::operator new(size_t size)
{
onTheHeap = true;
return ::operator new(size);
}
UPNumber::UPNumber()
{
if (!onTheHeap) {
throw HeapConstraintViolation();
}
proceed with normal construction here;
onTheHeap = false;// 为下一个对象清除标记
}
如果不再深入研究下去,就不会发现什么错误。这种方法利用了这样一个事实:"当在堆上分配对象时,会调用operator new来分配raw memory",operator new设置onTheHeap为true,每个构造函数都会检测onTheHeap,看对象的raw memory是否被operator new所分配。如果没有,一个类型HeapConstraintViolation的异常将被抛出。否则构造函数如通常那样继续运行,当构造函数结束时,onTheHeap被设置为false,然后为构造下一个对象而重置到缺省值。
这是一个非常好的方法,但是不能运行。请考虑一下这种可能的客户端代码:
第一个问题是为数组分配内存的是 operator new[],而不是 operator new,不过(倘若你的编译器支持它)你能象编写 operator new 一样容易地编写 operator new[]函数。更大的问题是numberArray 有 100 个元素,所以会调用 100 次构造函数。但是只有一次分配内存的调用,所以 100 个构造函数中只有第一次调用构造函数前把 onTheHeap 设置为 true。当调用第二个构造函数时,会抛出一个异常,你真倒霉。即使不用数组,bit-setting 操作也会失败。考虑这条语句:
这里我们在堆中建立两个 UPNumber,让 pn 指向其中一个对象;这个对象用另一个对象的值进行初始化。这个代码有一个内存泄漏,我们先忽略这个泄漏,这有利于下面对这条表达式的测试,执行它时会发生什么事情:
它包含 new 操作符的两次调用,因此要调用两次 operator new 和调用两次 UPNumber构造函数。程序员一般期望这些函数以如下顺序执行:
调用第一个对象的 operator new
调用第一个对象的构造函数
调用第二个对象的 operator new
调用第二个对象的构造函数
但是 C++语言没有保证这就是它调用的顺序。一些编译器以如下这种顺序生成函数调用:
调用第一个对象的 operator new
调用第二个对象的 operator new
调用第一个对象的构造函数
调用第二个对象的构造函数
编译器生成这种代码丝毫没有错,但是在 operator new 中 set-a-bit 的技巧无法与这种编译器一起使用。因为在第一步和第二步设置的 bit,第三步中被清除,那么在第四步调用对象的构造函数时,就会认为对象不再堆中,即使它确实在。
这些困难没有否定让每个构造函数检测*this 指针是否在堆中这个方法的核心思想,它们只是表明检测在 operator new(或 operator new[])里的 bit set 不是一个可靠的判断方法。我们需要更好的方法进行判断。
如果你陷入了极度绝望当中,你可能会沦落进不可移植的领域里。例如你决定利用一个在很多系统上存在的事实,程序的地址空间被做为线性地址管理,程序的栈从地址空间的顶部向下扩展,堆则从底部向上扩展:

在以这种方法管理程序内存的系统里(很多系统都是,但是也有很多不是这样),你可能会想能够使用下面这个函数来判断某个特定的地址是否在堆中:
bool onHeap(const void *address)
{
char onTheStack;// 局部栈变量
return address < &onTheStack;
}
这个函数背后的思想很有趣。在 onHeap 函数中 onTheSatck 是一个局部变量。因此它在堆栈上。当调用 onHeap 时,它的栈框架(stack frame)(也就是它的 activation record)被放在程序栈的顶端,因为栈在结构上是向下扩展的(趋向低地址),onTheStack 的地址肯定比任何栈中的变量或对象的地址小。如果参数 address 的地址小于 onTheStack 的地址,它就不会在栈上,而是肯定在堆上。
到目前为止,这种逻辑很正确,但是不够深入。最根本的问题是对象可以被分配在三个地方,而不是两个。是的,栈和堆能够容纳对象,但是我们忘了静态对象。静态对象是那些在程序运行时仅能初始化一次的对象。静态对象不仅仅包括显示地声明为 static 的对象,也包括在全局和命名空间里的对象。这些对象肯定位于某些地方,而这些地方既不是栈也不是堆。
它们的位置是依据系统而定的,但是在很多栈和堆相向扩展的系统里,它们位于堆的底端。先前内存管理的图片到讲述的是事实,而且是很多系统都具有的事实,但是没有告诉我们这些系统全部的事实,加上静态变量后,这幅图片如下所示:
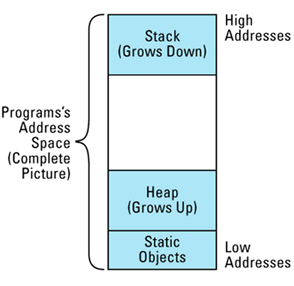
onHeap 不能工作的原因立刻变得很清楚了,不能辨别堆对象与静态对象的区别:
{
char *pc = new char;// 堆对象: onHeap(pc) 将返回 true
char c;// 栈对象: onHeap(&c) 将返回 false
static char sc;// 静态对象: onHeap(&sc) 将返回 true
...
}
现在你可能不顾一切地寻找区分堆对象与栈对象的方法,在走头无路时你想在可移植性上打主意,但是你会这么孤注一掷地进行一个不能获得正确结果的交易么?绝对不会。我知道你会拒绝使用这种虽然诱人但是不可靠的"地址比对"技巧。
令人伤心的是不仅没有一种可移植的方法来判断对象是否在堆上,而且连能在多数时间正常工作的"准可移植"的方法也没有。如果你实在非得必须判断一个地址是否在堆上,你必须使用完全不可移植的方法,其实现依赖于系统调用,只能这样做了。因此你最好重新设计你的软件,以便你可以不需要判断对象是否在堆中。
如果你发现自己实在为对象是否在堆中这个问题所困扰,一个可能的原因是你想知道对象是否能在其上安全调用 delete。这种删除经常采用"delete this"这种声明狼籍的形式。不过知道"是否能安全删除一个指针"与"只简单地知道一个指针是否指向堆中的事物"不一样,因为不是所有在堆中的事物都能被安全地 delete。再考虑包含 UPNumber 对象的 Asset对象:
private:
UPNumber value;
...
};
Asset *pa = new Asset;
很明显*pa(包括它的成员 value)在堆上。同样很明显在指向 pa->value 上调用 delete是不安全的,因为该指针不是被 new 返回的。
幸运的是"判断是否能够删除一个指针"比"判断一个指针指向的事物是否在堆上"要容易。因为对于前者我们只需要一个 operator new 返回的地址集合。因为我们能自己编写operator new 函数,所以构建这样一个集合很容易。如下所示,我们这样解决这个问题:
{
void *p = getMemory(size);//调用一些函数来分配内存,处理内存不够的情况
把 p 加入到一个被分配地址的集合;
return p;
}
void operator delete(void *ptr)
{
releaseMemory(ptr);// return memory to free store
从被分配地址的集合中移去 ptr;
}
bool isSafeToDelete(const void *address)
{
返回 address 是否在被分配地址的集合中;
}
这很简单,operator new 在地址分配集合里加入一个元素,operator delete 从集合中移去项目,isSafeToDelete 在集合中查找并确定某个地址是否在集合中。如果 operator new和 operator delete 函数在全局作用域中,它就能适用于所有的类型,甚至是内建类型。
在实际当中,有三种因素制约着对这种设计方式的使用。第一是我们极不愿意在全局域定义任何东西,特别是那些已经具有某种含义的函数, operator new 和 operator delete。象正如我们所知,只有一个全局域,只有一种具有正常特征形式(也就是参数类型)的operator new 和 operator delete。这样做会使得我们的软件与其它也实现全局版本的operator new 和 operator delete 的软件(例如许多面向对象数据库系统)不兼容。
我们考虑的第二个因素是效率:如果我们不需要这些,为什么还要为跟踪返回的地址而负担额外的开销呢?
最后一点可能有些平常,但是很重要。实现 isSafeToDelete 让它总能够正常工作是不可能的。难点是多继承下来的类或继承自虚基类的类有多个地址,所以无法保证传给isSafeToDelete 的地址与operator new 返回的地址相同,即使对象在堆中建立。
我们希望这些函数提供这些功能时能够不污染全局命名空间,没有额外的开销,没有正确性问题。幸运的是 C++使用一种抽象 mixin 基类满足了我们的需要。
抽象基类是不能被实例化的基类,也就是至少具有一个纯虚函数的基类。mixin( mix in"")类提供某一特定的功能,并可以与其继承类提供的其它功能相兼容。这种类几乎都是抽象类。因此我们能够使用抽象混合(mixin)基类给派生类提供判断指针指向的内存是否由 operator new 分配的能力。该类如下所示:
public: // 从 operator new 返回的 ptr
class MissingAddress{};// 异常类,见下面代码
virtual ~HeapTracked() = 0;
static void *operator new(size_t size);
static void operator delete(void *ptr);
bool isOnHeap() const;
private:
typedef const void* RawAddress;
static list<RawAddress> addresses;
};
这个类使用了 list(链表)数据结构跟踪从 operator new 返回的所有指针,list 是标。operator new 函数分配内准 C++库的一部分存并把地址加入到 list 中;operator delete 用来释放内存并从 list 中移去地址元素。isOnHeap 判断一个对象的地址是否在 list 中。
HeapTracked 类的实现很简单,调用全局的 operator new 和 operator delete 函数来完成内存的分配与释放,list 类里的函数进行插入操作和删除操作,并进行单语句的查找操作。以下是HeapTracked 的全部实现:
list<RawAddress> HeapTracked::addresses;
// HeapTracked 的析构函数是纯虚函数,使得该类变为抽象类。
// (参见 Effective C++条款 14). 然而析构函数必须被定义,
//所以我们做了一个空定义。.
HeapTracked::~HeapTracked() {}
void * HeapTracked::operator new(size_t size)
{
void *memPtr = ::operator new(size); // 获得内存
addresses.push_front(memPtr);// 把地址放到 list 的前端
return memPtr;
}
void HeapTracked::operator delete(void *ptr)
{
//得到一个 "iterator",用来识别 list 元素包含的 ptr;
//有关细节参见条款 35
list<RawAddress>::iterator it =
find(addresses.begin(), addresses.end(), ptr);
if (it != addresses.end()) {// 如果发现一个元素
addresses.erase(it);//则删除该元素
::operator delete(ptr);// 释放内存
} else {// 否则
throw MissingAddress();// ptr 就不是用 operator new
} // 分配的,所以抛出一个异常
}
bool HeapTracked::isOnHeap() const
{
// 得到一个指针,指向*this 占据的内存空间的起始处,
// 有关细节参见下面的讨论
const void *rawAddress = dynamic_cast<const void*>(this);
// 在 operator new 返回的地址 list 中查到指针
list<RawAddress>::iterator it =
find(addresses.begin(), addresses.end(), rawAddress);
return it != addresses.end();// 返回 it 是否被找到
}
尽管你可能对 list 类和标准 C++库的其它部分不很熟悉,代码还是很一目了然。条款M35 将解释这里的每件东西,不过代码里的注释已经能够解释这个例子是如何运行的。只有一个地方可能让你感到困惑,就是这个语句(在 isOnHeap 函数中)
我前面说过带有多继承或虚基类的对象会有几个地址,这导致编写全局函数isSafeToDelete 会很复杂。这个问题在 isOnHeap 中仍然会遇到,但是因为 isOnHeap 仅仅用于 HeapTracked 对象中,我们能使用 dynamic_cast 操作符的一种特殊的特性来消除这个问题。只需简单地放入dynamic_cast,把一个指针 dynamic_cast 成 void*类型(或 const void*或 volatilevoid* 。。。。。),生成的指针将指向"原指针指向对象内存"的开始处。但是 dynamic_cast 只能用于"指向至少具有一个虚拟函数的对象"的指针上。我们该死的 isSafeToDelete 函数可以用于指向任何类型的指针,所以dynamic_cast也不能帮助它。isOnHeap 更具有选择性(它只能测试指向 HeapTracked 对象的指针),所以能把 this 指针 dynamic_cast 成 const void*,变成一个指向当前对象起始地址的指针。如果 HeapTracked::operator new 为 当 前 对 象 分 配 内 存 , 这 个 指 针 就 是HeapTracked::operator new 返回的指针。如果你的编译器支持 dynamic_cast 操作符,这个技巧是完全可移植的。
使用这个类,即使是最初级的程序员也可以在类中加入跟踪堆中指针的功能。他们所需要做的就是让他们的类从 HeapTracked 继承下来。例如我们想判断 Assert 对象指针指向的是否是堆对象:
private:
UPNumber value;
...
};
我们能够这样查询 Assert*指针,如下所示:
{
if (ap->isOnHeap()) {
ap is a heap-based asset — inventory it as such;
}
else {
ap is a non-heap-based asset — record it that way;
}
}
象 HeapTracked 这样的混合类有一个缺点,它不能用于内建类型,因为象 int 和 char这样的类型不能继承自其它类型。不过使用象 HeapTracked 的原因一般都是要判断是否可以调用"delete this",你不可能在内建类型上调用它,因为内建类型没有 this 指针。
禁止堆对象
判断对象是否在堆中的测试到现在就结束了。与此相反的领域是"禁止在堆中建立对象"。通常对象的建立这样三种情况:对象被直接实例化;对象做为派生类的基类被实例化;对象被嵌入到其它对象内。我们将按顺序地讨论它们。
禁止用户直接实例化对象很简单,因为总是调用 new 来建立这种对象,你能够禁止用户调用 new。你不能影响 new 操作符的可用性(这是内嵌于语言的),但是你能够利用 new 操作符总是调用 operator new 函数这点,来达到目的。你可以自己声明这个函数,而且你可以把它声明为 private。例如,如果你想不想让用户在堆中建立 UPNumber对象,你可以这样编写:
private:
static void *operator new(size_t size);
static void operator delete(void *ptr);
...
};
现在用户仅仅可以做允许它们做的事情:
static UPNumber n2;// also okay
UPNumber *p = new UPNumber;// error! attempt to call private operator new
把 operator new 声明为 private 就足够了,但是把 operator new 声明为 private,而把 iperator delete 声明为 public,这样做有些怪异,所以除非有绝对需要的原因,否则不要把它们分开声明,最好在类的一个部分里声明它们。如果你也想禁止 UPNumber 堆对象数组,可以把 operator new[]和 operator delete[](参见条款 M8)也声明为 private。(operator new 和operator delete 之间的联系比大多数人所想象的要强得多。有关它们之间关系的鲜为人知的一面,可以参见我的文章 counting objects 里的 sidebar 部分。)
有趣的是,把 operator new 声明为 private 经常会阻碍 UPNumber 对象做为一个位于堆中的派生类对象的基类被实例化。因为 operator new 和 operator delete 是自动继承的,如果operator new 和 operator delete 没有在派生类中被声明为 public(进行改写,overwrite),它们就会继承基类中 private 的版本,如下所示:
class NonNegativeUPNumber://假设这个类没有声明 operator new
public UPNumber {
...
};
NonNegativeUPNumber n1;// 正确
static NonNegativeUPNumber n2;// 也正确
NonNegativeUPNumber *p =new NonNegativeUPNumber; // 错误! 试图调用private operator new
如果派生类声明它自己的 operator new,当在堆中分配派生对象时,就会调用这个函数,于是得另找一种不同的方法来防止 UPNumber 基类的分配问题。UPNumber 的 operator new是 private 这一点,不会对包含 UPNumber 成员对象的对象的分配产生任何影响:
public:
Asset(int initValue);
...
private:
UPNumber value;
};
Asset *pa = new Asset(100);// 正确, 调用 Asset::operator new 或 ::operator new, 不是 UPNumber::operator new
实际上,我们又回到了这个问题上来,即"如果 UPNumber 对象没有被构造在堆中,我们想抛出一个异常"。当然这次的问题是"如果对象在堆中,我们想抛出异常"。正像没有可移植的方法来判断地址是否在堆中一样,也没有可移植的方法判断地址是否不在堆中,所以我们很不走运,不过这也丝毫不奇怪,毕竟如果我们能辨别出某个地址在堆上,我们也就能辨别出某个地址不在堆上。但是我们什么都不能辨别出来。