参杂着原文翻译和自己的话。。感谢有道翻译。
全文注释:
- log请求=logging request=日志请求,指代logger.info、logger.debug之类的调用。
- 祖先的意思根据语境变化,有时候也包含父母,大多数时候只指爷爷辈以上。
Logback's architecture
logback被分成三个模块:logback-core, logback-classic和logback-access,其中core模块是其它两个模块的基础。classic模块是core模块的扩展,它对应着log4j的一个显著改进版本。logback-classic实现了SLF4J API,这让你可以在各种日志系统(JUL、log4j等)和logback间无压力地切换。第三个名为access的模块与Servlet容器集成,以提供HTTP访问日志功能。文档的剩余部分,主要讲述logback-classic相关的内容。
Logger, Appenders and Layouts
Logback建立在三种主要类的基础上:Logger, Appender以及Layout。
Logger类属于logback-classic模块,另外两个接口属于logback-core模块,作为一个通用模块,在logback-core模块中并没有logger的概念。
Logger context
任何日志API优于普通System.out.println的第一个也是最重要的优势在于:日志API能够禁用特定的log语句,同时允许其他log语句不受阻碍地打印。这暗示着log语句按照开发人员制定的标准分成若干类。在logback-classic中,这种分类是logger的固有部分。所有logger都共同隶属于一个LoggerContext,后者负责制造logger以及将它们排列在树状层次结构中。
logger都是有名字的实体。它们的名字是大小写敏感,并且遵循分层命名规则。例如说,名为“com.mycompany”的logger被称作名为“com.mycompany.xxx”的logger的父母(直接关系!)。类似地,“com”被称为“com.mycompany.xxx”的祖先(隔代关系)。
root logger位于logger的树状层次结构的顶端(根部)。它的特殊之处在于它是任何logger树状层次结构的一部分。像其它Logger一样,可以通过名字拿到它:
Logger rootLogger = LoggerFactory.getLogger(org.slf4j.Logger.ROOT_LOGGER_NAME);
rootLogger.debug("大家好!我是root logger");
Effective Level(有效等级)又名Level Inheritance
logger可以被赋予等级,可以分配的等级有:TRACE, DEBUG, INFO, WARN和ERROR。Level类是final的,不能有子类!文档上的言下之意貌似是有更灵活的方式来改变Level类。如果,一个logger没有被赋予等级,则它的有效等级与和它最近的被赋予等级的祖先logger一样。言下之意就是,所有logger虽然不一定都有赋予等级,但是都是具有“有效等级”的(继承自祖先)。参考图:

强调:子logger继承的是最近祖先的assigned level,而不是effective level!
Printing methods and the basic selection rule
形如logger.info("xxxxxxxx...")是一个等级为info的log请求。只有在log请求的等级高于或者等于它的logger的有效等级时才是“启用(enabled )”的,否则称该请求被禁用(disabled)。

这个规则是logback的核心。它设定的级别(logger有效等级,log请求等级)顺序如下:TRACE < DEBUG < INFO < WARN < ERROR。
basic selection rule例子程序:
package org.sample.logback; import org.junit.Test; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class LogbackTest { @Test public void testLogback() { // root logger的默认赋予等级,也就是有效等级为DEBUG Logger rootLogger = LoggerFactory.getLogger(org.slf4j.Logger.ROOT_LOGGER_NAME); // This request is disabled, because TRACE < DEBUG. rootLogger.trace("trace:大家好!我是root logger"); // This request is enabled, because DEBUG >= DEBUG rootLogger.debug("debug:大家好!我是root logger"); // This request is enabled, because INFO >= DEBUG rootLogger.info("info:大家好!我是root logger"); // This request is enabled, because WARN >= DEBUG rootLogger.warn("warn:大家好!我是root logger"); /* output= 14:28:37.443 [main] DEBUG ROOT - debug:大家好!我是root logger 14:28:37.448 [main] INFO ROOT - info:大家好!我是root logger 14:28:37.448 [main] WARN ROOT - warn:大家好!我是root logger PS. 唯独不见trace */ } }
Retrieving Loggers - - 检索logger
名字相同的logger就是同一个logger,给定logger的名字可以在应用程序中的任何地方拿到这个logger。
按照生物学的观点,老子总是得先于孩子的。但是logback有那么点不同,它允许儿子先初始化、老子之后初始化,不过两个logger的父子关系在老子初始化后也会自动关联上去,让我们来看一个例子:
package org.sample.logback; import ch.qos.logback.classic.Level; import org.junit.Test; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class LogbackTest { @Test public void testLogback() { Logger son = LoggerFactory.getLogger("father.son"); // 儿子先进行初始化 // son默认继承root logger的赋予等级,也就是son的有效等级是DEBUG son.trace("help!"); // 这个log请求未被启用,因为 TRACE < DEBUG // Level类被定义在ch.qos.logback.classic里。所以必须用ch.qos.logback.classic.Logger才能设置它的level ch.qos.logback.classic.Logger father = (ch.qos.logback.classic.Logger) LoggerFactory.getLogger("father"); // 这个时候,初始化儿子他爹,将自动进行关联 father.setLevel(Level.TRACE); // 这样儿子的有效等级也变成TRACE了 son.trace("help!"); // 结果就是上一句不打印,这一句打印 } }
当然,在通常情况下,logger的配置在程序初始化的时候就完成了(通过读取配置文件)。用类全名来命名logger仍然是目前已知的最好的策略。
Appenders and Layouts
允许选择性地启用和禁用log请求只是logback功能的一部分。Logback还允许将log请求打印到多个目的地。用logback里的术语来讲,日志的“输出目的地”被称为appender。一个logger可以有多个appender。
可以通过addAppender方法把一个appender添加到logger上。对于给定logger的每个enable的log请求都将被转发给该logger中的所有appender,以及层次结构中更高所有appender(祖先、父母辈的appender)。换句话说,appender具有可加性。儿子能够共享老子(以及祖先,前提是老子没有setAdditive(false);)的所有appender。举个例子,在这里忽略root logger的存在,假设老子logger有且仅有一个输出到文件的appender,而儿子logger有且仅有一个输出到控制台的appender,那么老子就只能打印到文件,而儿子既打印到控制台也打印到文件,如果有一天儿子不想再打印到文件了,只要setAdditive(false);就可以了,并且孙子(儿子的儿子)也不会打印到文件(等于儿子全家都和老子断绝关系了。)
用户通常并不满足于决定“输出目的地”,还希望能够随意操控打印格式。要做到这一点很简单,只需把layout和相应的appender关联起来就ok了。layout负责按照用户的期望格式化log请求。PatternLayout是标准logback发行版的一部分,它允许用户根据类似于C语言printf函数的转换模式指定输出格式。
Parameterized logging参数化log请求
不用这样写:
if(logger.isDebugEnabled()) { logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i])); }
这样写就可以了↓
Object entry = new SomeObject(); logger.debug("The entry is {}.", entry);
以下两行将产生完全相同的输出。但是,如果log请求被禁用,那么第二个变体的性能要比第一个变体好至少30倍:
logger.debug("The new entry is "+entry+".");
logger.debug("The new entry is {}.", entry);
多个参数也是支持的。如下:
package org.sample.logback; import org.junit.Test; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class LogbackTest { @Test public void testLogback() { Logger logger = LoggerFactory.getLogger(LogbackTest.class); logger.debug("Hello {} , how are {}", "xkfx", "you"); // => 15:57:16.196 [main] DEBUG org.sample.logback.LogbackTest - Hello xkfx , how are you logger.debug("Hello {} , how are {}, what is your {}", "xkfx", "you", "name"); // =>15:58:03.783 [main] DEBUG org.sample.logback.LogbackTest - Hello xkfx , how are you, what is your name // 还可以这样↓ Object[] paramArray = {"xkfx", "you", "name"}; logger.debug("Hello {} , how are {}, what is your {}", paramArray); // 输出同上 } }
A peek under the hood在引擎盖下面偷看一下。。
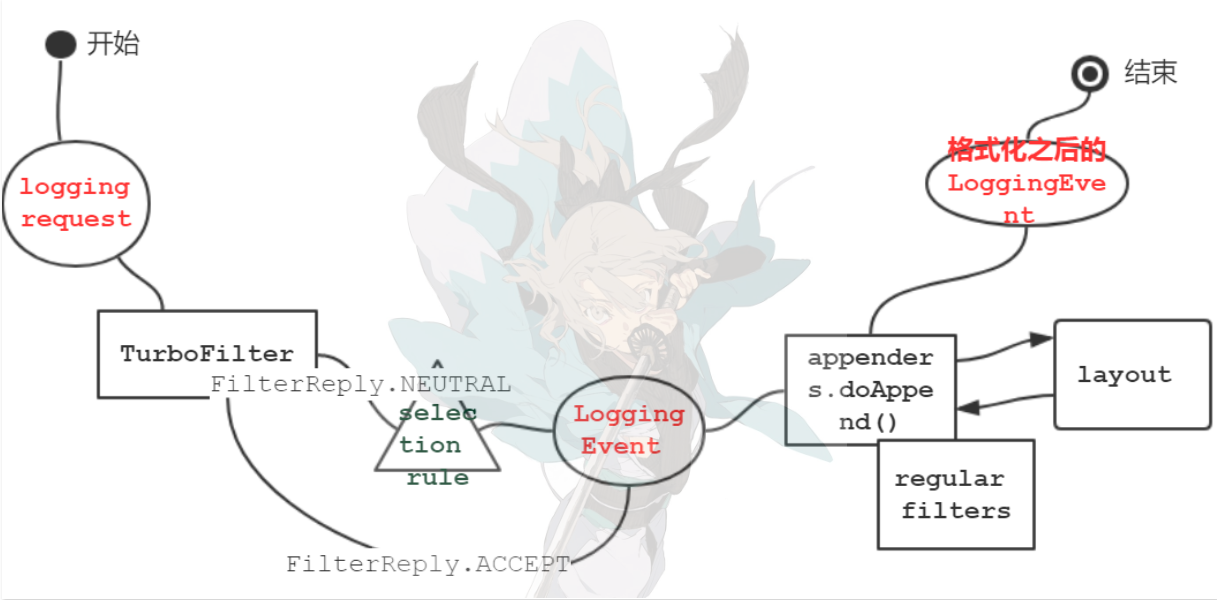
介绍完了logback的几个基本组件,我们已经可以描述logback框架在用户发起log请求时所采取的步骤。现在让我们分析一下当用户调用名为com.wombat的logger的info()方法时,logback所采取的步骤。接下来用单步调试跟踪一下logger.info("Hello World");
1. Get the filter chain decision
首先step into进入logger.info方法:

出现一个看到名字想不出来具体含义的方法,继续step into进入filterAndLog_0_Or3Plus方法:
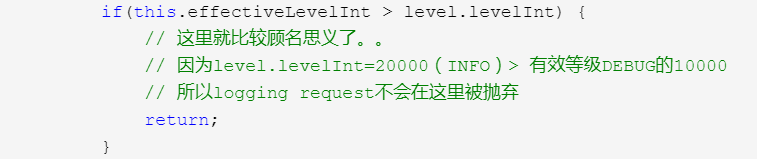
private void filterAndLog_0_Or3Plus(String localFQCN, Marker marker, Level level, String msg, Object[] params, Throwable t) { /* 如果filter chain存在,则TurboFilter链将被调用 1、Turbo过滤器可以设置上下文范围的阈值, 2、或者根据特定的信息(Marker、Level、Logger、message以及与每个log请求关联的Throwable等) 过滤掉某些事件。 (PS. 硬翻,可能有错) */ FilterReply decision = this.loggerContext.getTurboFilterChainDecision_0_3OrMore(marker, this, level, msg, params, t); if(decision == FilterReply.NEUTRAL) { if(this.effectiveLevelInt > level.levelInt) { // 这里就比较顾名思义了。。 // 因为level.levelInt=20000(INFO)> 有效等级DEBUG的10000 // 所以logging request不会在这里被抛弃 return; } } else if(decision == FilterReply.DENY) { return; } this.buildLoggingEventAndAppend(localFQCN, marker, level, msg, params, t); }
=> 补充turbo filter的相关资料:在Logback-classic中提供两个类型的filters , 一种是regular filters,另一种是turbo filter。regular filters是与appender 绑定的,而turbo filter是与与logger context(logger上下文绑定的,区别就是,turbo filter过滤所有logging request(log请求),而regular filter只过滤某个appender的logging request。(作者:巫巫巫政霖,原文:https://blog.csdn.net/Doraemon_wu/article/details/52072360 )
2. Apply the basic selection rule
就是指上面代码中的这一段:
如果decision == FilterReply.ACCEPT的话,就没有这个步骤了。
3. Create a LoggingEvent object
step into进入buildLoggingEventAndAppend(localFQCN, marker, level, msg, params, t);
参数情况:
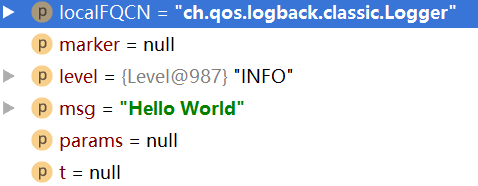
我们将用这些参数,以及当前时间、当前线程、各种类的相关数据、MDC等构造一个LoggingEvent对象。
private void buildLoggingEventAndAppend(String localFQCN, Marker marker, Level level, String msg, Object[] params, Throwable t) { LoggingEvent le = new LoggingEvent(localFQCN, this, level, msg, t, params); le.setMarker(marker); this.callAppenders(le); }
请注意,其中一些字段是惰性初始化的,只有在实际需要时才初始化。MDC用于附加上下文信息来修饰logging request。MDC在后面的一章中讨论。
4. Invoking appenders
在创建LoggingEvent对象之后,logback将调用所有当前logger可用的appender(就是自己的、老子的、祖先的)的doAppend()方法。step into进入callAppenders(ILogginEvent event);↓
public void callAppenders(ILoggingEvent event) { int writes = 0; for(Logger l = this; l != null; l = l.parent) { writes += l.appendLoopOnAppenders(event); if(!l.additive) { break; } } if(writes == 0) { this.loggerContext.noAppenderDefinedWarning(this); } }
这个for循环写得也是非常酷炫。。首先检查com.wombat的AppenderAttachableImpl,发现没有,再找com的aai,发现也没有,最后找root logger的aai,终于找到了,于是对这个aai(应该是和logger的特定appender共同存亡的一个对象)调用AppenderAttachableImpl类的appendLoopOnAppenders(event)方法,如下所示,外围的appendLoopOnAppenders方法是属于ch.qos.logback.classic.Logger类的:
private int appendLoopOnAppenders(ILoggingEvent event) { return this.aai != null?this.aai.appendLoopOnAppenders(event):0; }
在appendLoopOnAppenders的方法体里拿到对应appender的引用,调用doAppend方法(传入logginevent对象作为参数)。所有logback发行版里的appender都继承自抽象类AppenderBase,这个抽象类在synchronized块里实现了doAppend方法,从而确保了线程安全。doAppend方法体中同样会调用appender所关联的过滤器,同样是会拿到一个FilterReply来决定要不要放弃掉这个logging request。
但是我却进入了一个叫做UnsynchronizedAppenderBase的doAppend方法里,并没有看到synchronized块:


public void doAppend(E eventObject) { if(!Boolean.TRUE.equals(this.guard.get())) { try { this.guard.set(Boolean.TRUE); if(this.started) { if(this.getFilterChainDecision(eventObject) == FilterReply.DENY) { return; } this.append(eventObject); return; } if(this.statusRepeatCount++ < 3) { this.addStatus(new WarnStatus("Attempted to append to non started appender [" + this.name + "].", this)); } } catch (Exception var6) { if(this.exceptionCount++ < 3) { this.addError("Appender [" + this.name + "] failed to append.", var6); } return; } finally { this.guard.set(Boolean.FALSE); } } }
5. Formatting the output
6. Sending out the LoggingEvent
logging event完全格式化后,由每个appender发送到其目的地。
贴张自己做的图:
Performance
详细参考原文末尾。