双向链表结构图:
就是他包含上一个节点的内存地址。并且还包含下一个节点的内存地址。
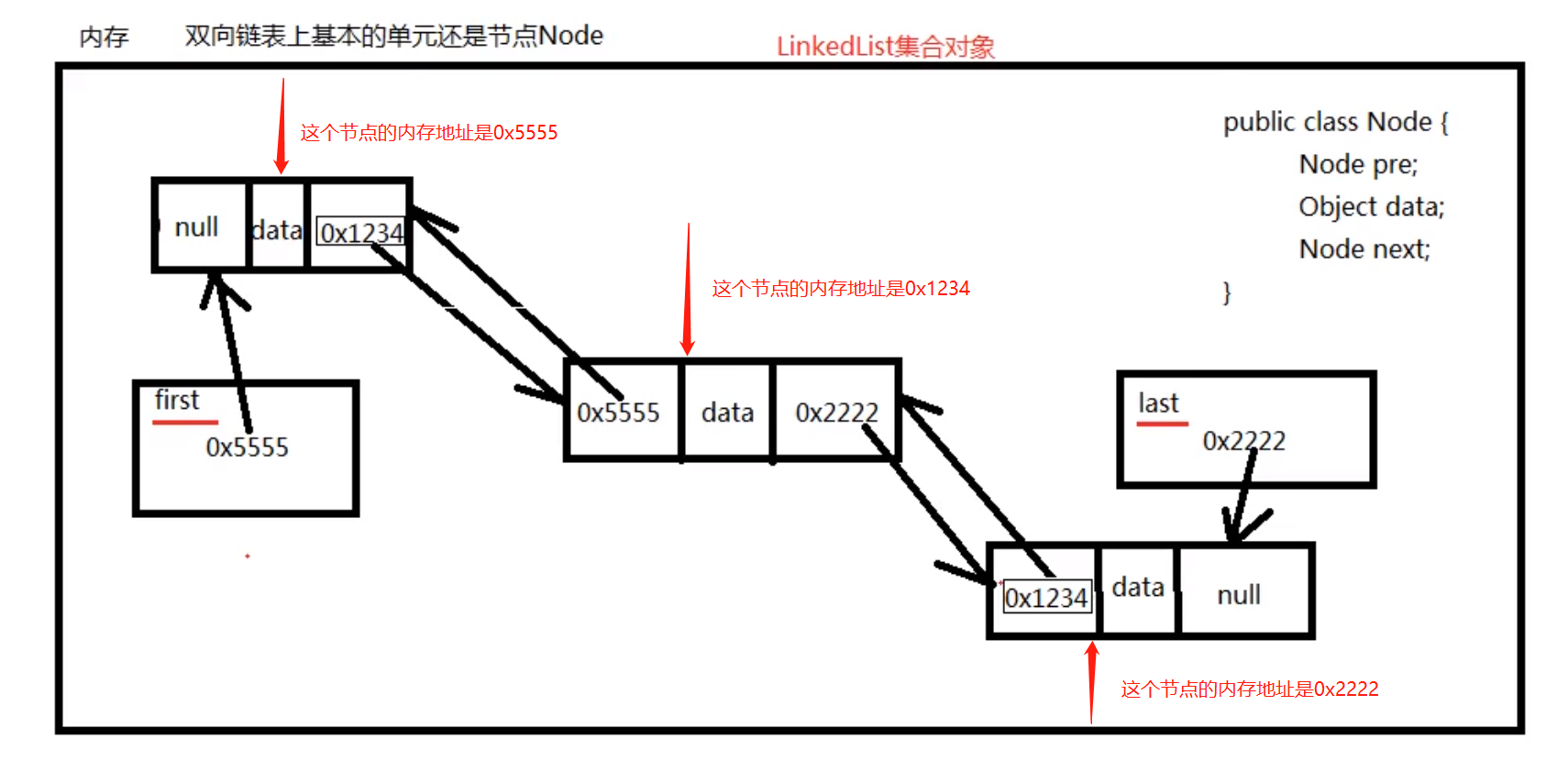
案例:
package com.javaSe.List; import java.util.ArrayList; import java.util.LinkedList; import java.util.List; /* 链表的优点: 由于链表上的元素在空间存储上内存地址不连续。 所以随机增删元素的时候不会有大量元素位移,因此随机增删效率较高。 在以后的开发中,如果遇到随机增删集合的业务较多时,建议使用LinkedList。 链表的缺点: 不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头节点开始遍历,直到找到为止。所以LinkedList集合检索/查找的效率较低。 ArrayList: 把检索发挥到极致。(末尾添加元素,效率是很高的。) LinkedList: 把随机增删发挥到极致。 加元素都是往末尾添加,所以ArrayList用的比LinkedList多。 */ public class LinkedListTest01 { public static void main(String[] args) { // LinkedList集合底层也是有下标的。 // 注意:ArrayList之所以检索效率高,不是单纯因为下标的原因。是因为底层数组发挥的作用。 // LinkedList集合照样有下标,但是检索/查找某个元素的时候效率比较低,因为只能从头结点开始一个一个遍历。 List list = new LinkedList(); list.add("a"); list.add("b"); list.add("c"); for (int i = 0; i < list.size(); i++) { Object obj = list.get(i); System.out.println(obj); } // LinkedList集合有初始化容量吗?没有。 // 最初这个链表中没有任何元素。first和last引用都是null。 // 不管是linked还是ArrayList,以后写代码时不需要关心具体是哪个集合。 // 因为我们要面相接口编程,调用的方法都是接口中的方法。 // List list1 = new ArrayList(); // 这样写表示底层用了数组。 List list1 = new LinkedList(); // 这样写表示底层用了双向链表。 // 以下这些代码你面向的都是接口编程。 list1.add("123"); list1.add("456"); list1.add("789"); for (int i = 0; i < list1.size(); i++) { System.out.println(list1.get(i)); } } }