re模块
1、匹配: findall search match
import re
# 操作的对象是字符串
#1、 匹配
# 1.1 findall 重要
ret = re.findall('d+','19874ashfk01248')
print(ret) # 传参格式:'正则表达式','字符串' 返回值类型:列表 返回值内容:所有匹配上的项
ret1 = re.findall('s+','19874ashfk01248')
print(ret1) #如果匹配不上返回的是空列表

# 1.2 search 重要
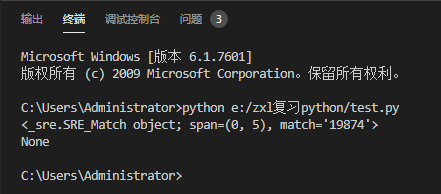
ret2 = re.search('d+','@$19874ashfk01248')
print(ret2,type(ret2)) #传参格式:('正则表达式','字符串') 返回值类型: 正则匹配结果的对象 如果匹配上了就返回对象,返回值类型是正则表达式的内容
if ret2:print(ret2.group()) #返回的对象通过group来获取,只取匹配到的第一个结果
ret3 = re.search('s+','19874ashfk01248')
print(ret3) #如果没有匹配上,返回值类型: None

# 1.3 match
ret4 = re.match('d+','19874ashfk01248')
print(ret4) #若匹配到只取第一个结果
ret5 = re.match('d+','%^19874ashfk01248')
print(ret5) #match默认从开头匹配,开头匹配不上直接返回None
#re.search('^d+','19874ashfk01248') 正则表达式里开头加^ 效果一样的
2、替换 sub subn
# sub
#相当于repalce的用法
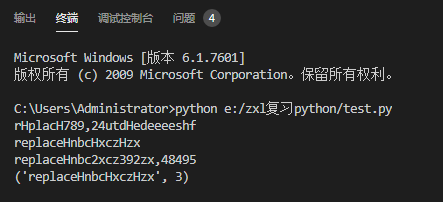
print('replace789,24utdeedeeeeshf'.replace('e','H',3)) #把字符串中H替换成e,替换3次
ret = re.sub('d+','H','replace789nbc2xcz392zx') #按正则表法式把字符串中匹配到的替换成H
print(ret)
ret1 = re.sub('d+','H','replace789nbc2xcz392zx,48495',1)
print(ret1)
# subn
ret2 = re.subn('d+','H','replace789nbc2xcz392zx')
print(ret2) #会把替换的次数返回
3、切割 split
# split ***
# print('alex|83|'.split('|'))
# ret = re.split('d+','alex83egon20taibai40')
# print(ret) #结果:['alex', 'egon', 'taibai', '']
4、进阶方法 compile finditer
- 爬虫自动化开发
# 4.1 compile 预编译***** 时间效率
# ret = re.compile('-0.d+|-[1-9]d+(.d+)?')
# res = ret.search('alex83egon-20taibai-40')
# print(res.group())
# 节省时间 : 只有在多次使用某一个相同的正则表达式的时候,这个compile才会帮助我们提高程序的效率
# finditer 生成迭代器***** 空间效率
# print(re.findall('d','sjkhkdy982ufejwsh02yu93jfpwcmc'))
# ret = re.finditer('d','sjkhkdy982ufejwsh02yu93jfpwcmc')
# for r in ret:
# print(r.group()) #使用.group()打印内容
5、分组:python中的正则表达式:
#findall会优先显示分组中的内容,要想取消分组优先,(?:正则表达式)
#split 遇到分组,会保留分组内被切掉的内容
#search 如果search中有分组的话,通过group(n)就能够依次拿到group中分组匹配的内容
#1、findall分组优先
ret1 = re.findall('www.baidu.com|www.oldboy.com','www.oldboy.com')
print(ret1)
ret2 = re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret2)
ret3 = re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret3)

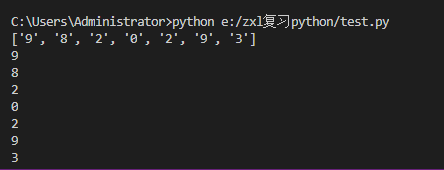
ret1 = re.findall('-0.d+|-[1-9]d*(.d+)?','-1abc-200')
print(ret1)
ret2 = re.findall('-0.d+|-[1-9]d*(?:.d+)?','-1abc-200')
print(ret2)

#2、split遇见分组,会返回被切割的内容
ret = re.split('d+','alex83egon20taibai40')
print(ret)
ret = re.split('(d+)','alex83egon20taibai40')
print(ret)

#3、search遇见分组
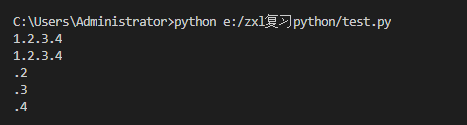
ret = re.search('d+(.d+)(.d+)(.d+)?','1.2.3.4-2*(60+(-40.35/5)-(-4*3))')
print(ret.group())
print(ret.group(0))
print(ret.group(1))
print(ret.group(2))
print(ret.group(3))
作业:
#只取整数:
import re
ret1=re.findall(r"d+(?:.d+)?","1-2*(60+(-40.35/5)-(-4*3))")
print(ret1) #获取的是所有
ret2=re.findall(r"d+(?:.d+)|(d+)","1-2*(60+(-40.35/5)-(-4*3))")
print(ret2)
ret2.remove('')
print(ret2)

#表单页签
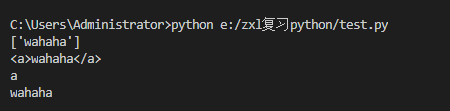
import re
ret = re.findall('>(w+)<',r'<a>wahaha<a>')
print(ret)
ret = re.search(r'<(w+)>(w+)</(w+)>',r'<a>wahaha</a>')
print(ret.group())
print(ret.group(1))
print(ret.group(2))
#分组命名:
# (?P<name>正则表达式) 表示给分组起名字
# (?P=name)表示使用这个分组,这里匹配到的内容应该和分组中的内容完全相同
# 通过索引使用分组
# 1 表示使用第一组,匹配到的内容必须和第一个组中的内容完全相同

import re
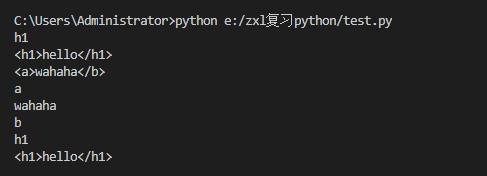
ret = re.search("<(?P<name>w+)>w+</(?P=name)>","<h1>hello</h1>")
print(ret.group('name'))
print(ret.group())
#使用(?P<name>)和(?P=name),字符串里对象前后名必须一致,否则会报错
ret = re.search(r'<(?P<tag>w+)>(?P<c1>w+)</(?P<c2>w+)>',r'<a>wahaha</b>')
print(ret.group())
print(ret.group('tag'))
print(ret.group('c1'))
print(ret.group('c2'))
ret = re.search(r"<(w+)>w+</1>","<h1>hello</h1>")
print(ret.group(1))
print(ret.group())