原文地址在这里,这里是多个排序算法全部整理过来的。整理转载过来只是为了自己阅读方便。
http://blog.csdn.net/morewindows/article/details/7961256
首先回顾下各种排序的主要思路:
一. 冒泡排序
冒泡排序主要思路是:
通过交换使相邻的两个数变成小数在前大数在后,这样每次遍历后,最大的数就“沉”到最后面了。重复N次即可以使数组有序。
冒泡排序改进1:在某次遍历中如果没有数据交换,说明整个数组已经有序。因此通过设置标志位来记录此次遍历有无数据交换就可以判断是否要继续循环。
冒泡排序改进2:记录某次遍历时最后发生数据交换的位置,这个位置之后的数据显然已经有序了。因此通过记录最后发生数据交换的位置就可以确定下次循环的范围了。
二. 直接插入排序
直接插入排序主要思路是:
每次将一个待排序的数据,插入到前面已经排好序的序列之中,直到全部数据插入完成。
三. 直接选择排序
直接选择排序主要思路是:
数组分成有序区和无序区,初始时整个数组都是无序区,然后每次从无序区选一个最小的元素直接放到有序区的最后,直到整个数组变有序区。
上面这三种排序都是非常简单的,下面这四种排序略有难度,希望读者能多多实践以加深理解。
四. 希尔排序
希尔排序主要思路是:
先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。由于希尔排序是对相隔若干距离的数据进行直接插入排序,因此可以形象的称希尔排序为“跳着插”。
五. 归并排序
归并排序主要思路是:
当一个数组左边有序,右边也有序,那合并这两个有序数组就完成了排序。如何让左右两边有序了?用递归!这样递归下去,合并上来就是归并排序。
六. 快速排序
快速选择排序主要思路是:
“挖坑填数+分治法”,首先令i =L; j = R; 将a[i]挖出形成第一个坑,称a[i]为基准数。然后j--由后向前找比基准数小的数,找到后挖出此数填入前一个坑a[i]中,再i++由前向后找比基准数大的数,找到后也挖出此数填到前一个坑a[j]中。重复进行这种“挖坑填数”直到i==j。再将基准数填入a[i]中,这样i之前的数都比基准数小,i之后的数都比基准数大。因此将数组分成二部分再分别重复上述步骤就完成了排序。
七. 堆排序
堆排序主要思路用张图示来表示更好:
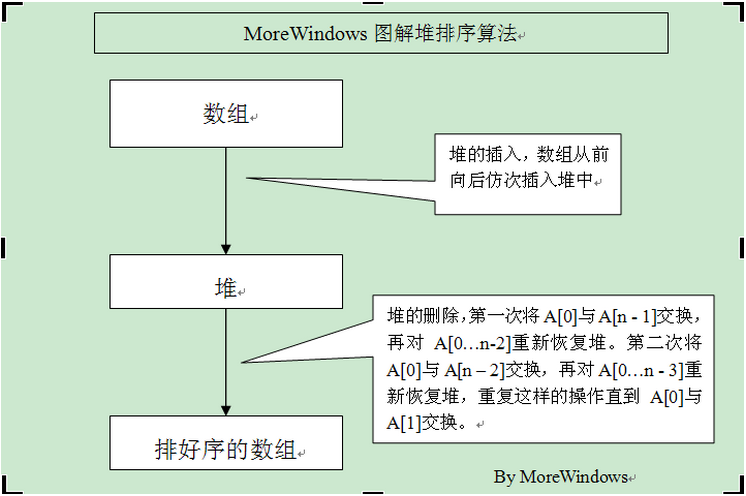
可见堆排序的难点就在于堆的的插入和删除。
堆的插入就是——每次插入都是将新数据放在数组最后,而从这个新数据的父结点到根结点必定是一个有序的数列,因此只要将这个新数据插入到这个有序数列中即可。
堆的删除就是——堆的删除就是将最后一个数据的值赋给根结点,然后再从根结点开始进行一次从上向下的调整。调整时先在左右儿子结点中找最小的,如果父结点比这个最小的子结点还小说明不需要调整了,反之将父结点和它交换后再考虑后面的结点。相当于从根结点开始将一个数据在有序数列中进行“下沉”。
因此,堆的插入和删除非常类似直接插入排序,只不是在二叉树上进行插入过程。所以可以将堆排序形容为“树上插”。
再用一张图表示下这七种常用的排序方法的关系。
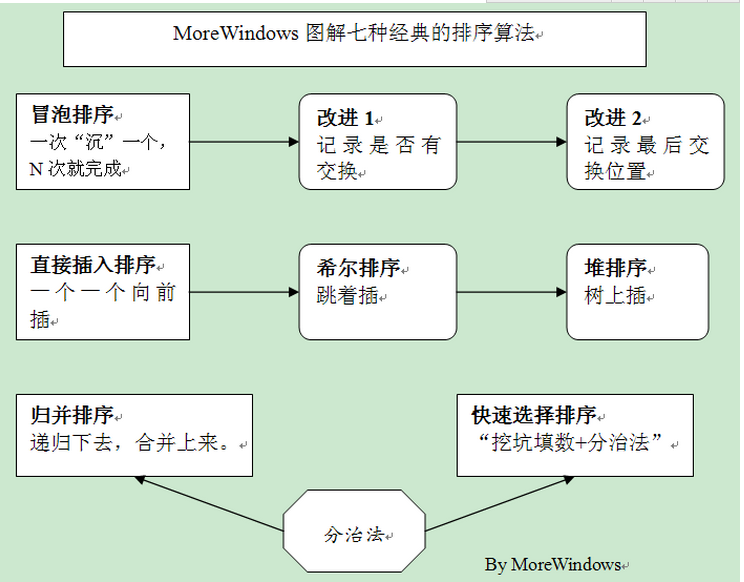
自己对里面的算法做了些小修改,如有错误,请指正。
长篇总结:
一.白话经典算法系列之一 冒泡排序的三种实现
设数组长度为N。
1.比较相邻的前后二个数据,如果前面数据大于后面的数据,就将二个数据交换。
2.这样对数组的第0个数据到N-1个数据进行一次遍历后,最大的一个数据就“沉”到数组第N-1个位置。
3.N=N-1,如果N不为0就重复前面二步,否则排序完成。


1 <span style="font-size:18px;">//冒泡排序算法1 2 //a代表排序数组,n代表数组中元素的个数,下标从0开始。 3 //这个算法是:大的元素上浮经过比较后上浮, 4 void BubbleSort(int a[],int n) 5 { 6 int i,j; 7 int temp = false;//初始为false,如果发生过交换就变为true。 8 for(i = 1; i <= n - 1; i++)//只需要排序n - 1趟就可以排序成功 9 { 10 for(j = 0; j < n - i; j++) //一趟排序 11 { 12 if(a[j] > a[j + 1]) //大的元素上浮 13 Swap(a[j],a[j + 1]); 14 temp = true; 15 } 16 if (temp == false) 17 break; 18 } 19 }</span>
1 <span style="font-size:18px;">void BubbleSort2(int a[],int n) 2 { 3 int flag;//标志位置 4 int i; 5 flag = true;//初始为空 6 int length = n; 7 while(flag) 8 { 9 flag = false; 10 for(i = 0;i < length - 1; i++) 11 { 12 if(a[i] > a[i + 1]) 13 { 14 Swap(a[i], a[i + 1]); 15 flag = true; 16 } 17 } 18 length --; 19 } 20 } 21 22 </span>
再做进一步的优化。如果有100个数的数组,仅前面10个无序,后面90个都已排好序且都大于前面10个数字,那么在第一趟遍历后,最后发生交换的位置必定小于10,且这个位置之后的数据必定已经有序了,记录下这位置,第二次只要从数组头部遍历到这个位置就可以了。
1 <span style="font-size:18px;">//改进算法3 2 void BubbleSort3(int a[],int n) 3 { 4 int temp = n - 1;//temp是循环需要遍历到的最后节点位置,初始 为 n - 1。 5 int i,flag = true; 6 int k; 7 while(flag) 8 { 9 flag = false; 10 k = temp; 11 for(i = 0; i < k; i++) 12 { 13 if(a[i] > a[i + 1]) 14 { 15 Swap(a[i],a[i + 1]); 16 temp = i + 1; 17 flag = true; 18 } 19 } 20 temp --; 21 } 22 } 23 </span>
二.白话经典算法系列之二 直接插入排序的三种实现
设数组为 a[0...n-1]。
1. 初始时,a[0]自成 1 个有序区,无序区为 a[1..n-1],令 i=1。
2. 将 a[i]并入当前的有序区 a[0...i-1]中形成 a[0...i]的有序区间。
3. i++并重复第二步直到 i==n-1,排序完成。
1 <span style="font-size:18px;">//直接插入排序算法,n代表数组元素中的个数。 2 //从第一个元素位置往后寻找插入位置 3 void InsertSort(int a[],int n) 4 { 5 int i,j; 6 for(i = 1; i < n; i++) 7 { 8 //找到合适的插入位置的下标 9 for(j = 0; j < i; j++) 10 { 11 if(a[j] <= a[i]) 12 ; 13 else 14 break; 15 } 16 while(i > j) 17 { 18 Swap(a[i],a[i - 1]); 19 i --; 20 } 21 } 22 }</span>
算法2:
1 <span style="font-size:18px;">//代码简化,搜索和数据后移数据一块操作 2 void InsertSort2(int a[],int n) 3 { 4 int i,j; 5 int temp;//temp记录 插入元素的值 6 //从后往前找插入位置,查找插入位置和数据移动一并操作 7 // 8 for(i = 1; i < n; i++) 9 { 10 temp = a[i];// 11 j = i - 1; 12 while( temp < a[j] && j >= 0) 13 { 14 a[j + 1] = a[j]; 15 j--; 16 } 17 a[j + 1] = temp;//将插入元素放入合适位置 18 } 19 }</span>
算法3改进:
1 <span style="font-size:18px;">//进一步简化插入排序版本,用Swap函数就不用一个专门的值来记录插入节点的值。 2 void InsertSort3(int a[],int n) 3 { 4 int i,j; 5 for(i = 1; i < n; i++) 6 { 7 for(j = i - 1; j >= 0 && a[j] > a[j + 1]; j--) 8 { 9 Swap(a[j],a[j + 1]); 10 } 11 } 12 }</span>
三.白话经典算法系列之三 希尔排序的实现
希尔排序的实质就是分组插入排序,该方法又称缩小增量排序,因DL.Shell于1959年提出而得名。
该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率上比前两种方法有较大提高。
以n=10的一个数组49, 38, 65, 97, 26, 13, 27, 49, 55, 4为例。
第一次 gap = 10 / 2 = 5
49 38 65 97 26 13 27 49 55 4
1A 1B
2A 2B
3A 3B
4A 4B
5A 5B
1A,1B,2A,2B等为分组标记,数字相同的表示在同一组,大写字母表示是该组的第几个元素, 每次对同一组的数据进行直接插入排序。即分成了五组(49, 13) (38, 27) (65, 49) (97, 55) (26, 4)这样每组排序后就变成了(13, 49) (27, 38) (49, 65) (55, 97) (4, 26),下同。
第二次 gap = 5 / 2 = 2
排序后
13 27 49 55 4 49 38 65 97 26
1A 1B 1C 1D 1E
2A 2B 2C 2D 2E
第三次 gap = 2 / 2 = 1
4 26 13 27 38 49 49 55 97 65
1A 1B 1C 1D 1E 1F 1G 1H 1I 1J
第四次 gap = 1 / 2 = 0 排序完成得到数组:
4 13 26 27 38 49 49 55 65 97
下面给出严格按照定义来写的希尔排序:
1 void shellsort1(int a[], int n) 2 { 3 int i, j, gap; 4 5 for (gap = n / 2; gap > 0; gap /= 2) //步长 6 for (i = 0; i < gap; i++) //直接插入排序 7 { 8 for (j = i + gap; j < n; j += gap) 9 if (a[j] < a[j - gap]) 10 { 11 int temp = a[j]; 12 int k = j - gap; 13 while (k >= 0 && a[k] > temp) 14 { 15 a[k + gap] = a[k]; 16 k -= gap; 17 } 18 a[k + gap] = temp; 19 } 20 } 21 }
很明显,上面的shellsort1代码虽然对直观的理解希尔排序有帮助,但代码量太大了,不够简洁清晰。因此进行下改进和优化,以第二次排序为例,原来是每次从1A到1E,从2A到2E,可以改成从1B开始,先和1A比较,然后取2B与2A比较,再取1C与前面自己组内的数据比较…….。这种每次从数组第gap个元素开始,每个元素与自己组内的数据进行直接插入排序显然也是正确的。
void shellsort2(int a[], int n) { int j, gap; for (gap = n / 2; gap > 0; gap /= 2) for (j = gap; j < n; j++)//从数组第gap个元素开始 if (a[j] < a[j - gap])//每个元素与自己组内的数据进行直接插入排序 { int temp = a[j]; int k = j - gap; while (k >= 0 && a[k] > temp) { a[k + gap] = a[k]; k -= gap; } a[k + gap] = temp; } }
再将直接插入排序部分用 白话经典算法系列之二 直接插入排序的三种实现 中直接插入排序的第三种方法来改写下:
1 void shellsort3(int a[], int n) 2 { 3 int i, j, gap; 4 5 for (gap = n / 2; gap > 0; gap /= 2) 6 for (i = gap; i < n; i++) 7 for (j = i - gap; j >= 0 && a[j] > a[j + gap]; j -= gap) 8 Swap(a[j], a[j + gap]); 9 }
这样代码就变得非常简洁了。
附注:上面希尔排序的步长选择都是从n/2开始,每次再减半,直到最后为1。其实也可以有另外的更高效的步长选择,如果读者有兴趣了解,请参阅维基百科上对希尔排序步长的说明:
四.白话经典算法系列之四 直接选择排序及交换二个数据的正确实现
直接选择排序和直接插入排序类似,都将数据分为有序区和无序区,所不同的是直接播放排序是将无序区的第一个元素直接插入到有序区以形成一个更大的有序区,而直接选择排序是从无序区选一个最小的元素直接放到有序区的最后。
设数组为a[0…n-1]。
1. 初始时,数组全为无序区为a[0..n-1],令i=0。
2. 在无序区a[i…n-1]中选取一个最小的元素,将其与a[i]交换。交换之后a[0…i]就形成了一个有序区。
3. i++并重复第二步直到i==n-1,排序完成。
直接选择排序无疑是最容易实现的,下面给出代码:
1 void Selectsort(int a[], int n) 2 { 3 int i, j, nMinIndex; 4 for (i = 0; i < n; i++) 5 { 6 nMinIndex = i; //找最小元素的位置 7 for (j = i + 1; j < n; j++) 8 if (a[j] < a[nMinIndex]) 9 nMinIndex = j; 10 11 Swap(a[i], a[nMinIndex]); //将这个元素放到无序区的开头 12 } 13 }
在这里,要特别提醒各位注意下Swap()的实现,建议用:
1 inline void Swap(int &a, int &b) 2 { 3 int c = a; 4 a = b; 5 b = c; 6 }
笔试面试时考不用中间数据交换二个数,很多人给出了
1 inline void Swap1(int &a, int &b) 2 { 3 a ^= b; 4 b ^= a; 5 a ^= b; 6 }
在网上搜索下,也可以找到许多这样的写法。不过这样写存在一个隐患,如果a, b指向的是同一个数,那么调用Swap1()函数会使这个数为0。如:
1 int i = 6; 2 Swap2(i, i); 3 printf("%d %d ", i);
当然谁都不会在程序中这样的写代码,但回到我们的Selectsort(),如果a[0]就是最小的数,那么在交换时,将会出现将a[0]置0的情况,这种错误相信调试起来也很难发现吧,因此建议大家将交换二数的函数写成:
1 inline void Swap(int &a, int &b) 2 { 3 int c = a; 4 a = b; 5 b = c; 6 }
或者在Swap1()中加个判断,如果二个数据相等就不用交换了:
1 inline void Swap1(int &a, int &b) 2 { 3 if (a != b) 4 { 5 a ^= b; 6 b ^= a; 7 a ^= b; 8 } 9 }
五.白话经典算法系列之五 归并排序的实现
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
首先考虑下如何将将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
1 //将有序数组a[]和b[]合并到c[]中 2 void MemeryArray(int a[], int n, int b[], int m, int c[]) 3 { 4 int i, j, k; 5 6 i = j = k = 0; 7 while (i < n && j < m) 8 { 9 if (a[i] < b[j]) 10 c[k++] = a[i++]; 11 else 12 c[k++] = b[j++]; 13 } 14 15 while (i < n) 16 c[k++] = a[i++]; 17 18 while (j < m) 19 c[k++] = b[j++]; 20 }
可以看出合并有序数列的效率是比较高的,可以达到O(n)。
解决了上面的合并有序数列问题,再来看归并排序,其的基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,那么就可以很方便的将这二组数据进行排序。如何让这二组组内数据有序了?
可以将A,B组各自再分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。
1 //将有二个有序数列a[first...mid]和a[mid...last]合并。 2 void mergearray(int a[], int first, int mid, int last, int temp[]) 3 { 4 int i = first, j = mid + 1; 5 int m = mid, n = last; 6 int k = 0; 7 8 while (i <= m && j <= n) 9 { 10 if (a[i] <= a[j]) 11 temp[k++] = a[i++]; 12 else 13 temp[k++] = a[j++]; 14 } 15 16 while (i <= m) 17 temp[k++] = a[i++]; 18 19 while (j <= n) 20 temp[k++] = a[j++]; 21 22 for (i = 0; i < k; i++) 23 a[first + i] = temp[i]; 24 } 25 void mergesort(int a[], int first, int last, int temp[]) 26 { 27 if (first < last) 28 { 29 int mid = (first + last) / 2; 30 mergesort(a, first, mid, temp); //左边有序 31 mergesort(a, mid + 1, last, temp); //右边有序 32 mergearray(a, first, mid, last, temp); //再将二个有序数列合并 33 } 34 } 35 36 bool MergeSort(int a[], int n) 37 { 38 int *p = new int[n]; 39 if (p == NULL) 40 return false; 41 mergesort(a, 0, n - 1, p); 42 delete[] p; 43 return true; 44 }
归并排序的效率是比较高的,设数列长为N,将数列分开成小数列一共要logN步,每步都是一个合并有序数列的过程,时间复杂度可以记为O(N),故一共为O(N*logN)。因为归并排序每次都是在相邻的数据中进行操作,所以归并排序在O(N*logN)的几种排序方法(快速排序,归并排序,希尔排序,堆排序)也是效率比较高的。
在本人电脑上对冒泡排序,直接插入排序,归并排序及直接使用系统的qsort()进行比较(均在Release版本下)
对20000个随机数据进行测试:
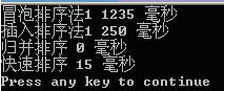
对50000个随机数据进行测试:

再对200000个随机数据进行测试:
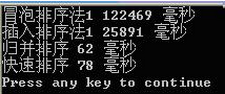
注:有的书上是在mergearray()合并有序数列时分配临时数组,但是过多的new操作会非常费时。因此作了下小小的变化。只在MergeSort()中new一个临时数组。后面的操作都共用这一个临时数组。
六.白话经典算法系列之六 快速排序 快速搞定
总的说来,要直接默写出快速排序还是有一定难度的,因为本人就自己的理解对快速排序作了下白话解释,希望对大家理解有帮助,达到快速排序,快速搞定。
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此我的对快速排序作了进一步的说明:挖坑填数+分治法:
先来看实例吧,定义下面再给出(最好能用自己的话来总结定义,这样对实现代码会有帮助)。
以一个数组作为示例,取区间第一个数为基准数。
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
72 |
6 |
57 |
88 |
60 |
42 |
83 |
73 |
48 |
85 |
初始时,i = 0; j = 9; X = a[i] = 72
由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j--;
数组变为:
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
48 |
6 |
57 |
88 |
60 |
42 |
83 |
73 |
88 |
85 |
i = 3; j = 7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
48 |
6 |
57 |
42 |
60 |
72 |
83 |
73 |
88 |
85 |
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
对挖坑填数进行总结
1.i =L; j = R; 将基准数挖出形成第一个坑a[i]。
2.j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
3.i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
4.再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
照着这个总结很容易实现挖坑填数的代码:
1 int AdjustArray(int s[], int l, int r) //返回调整后基准数的位置 2 { 3 int i = l, j = r; 4 int x = s[l]; //s[l]即s[i]就是第一个坑 5 while (i < j) 6 { 7 // 从右向左找小于x的数来填s[i] 8 while(i < j && s[j] >= x) 9 j--; 10 if(i < j) 11 { 12 s[i] = s[j]; //将s[j]填到s[i]中,s[j]就形成了一个新的坑 13 i++; 14 } 15 16 // 从左向右找大于或等于x的数来填s[j] 17 while(i < j && s[i] < x) 18 i++; 19 if(i < j) 20 { 21 s[j] = s[i]; //将s[i]填到s[j]中,s[i]就形成了一个新的坑 22 j--; 23 } 24 } 25 //退出时,i等于j。将x填到这个坑中。 26 s[i] = x; 27 28 return i; 29 }
再写分治法的代码:
1 void quick_sort1(int s[], int l, int r) 2 { 3 if (l < r) 4 { 5 int i = AdjustArray(s, l, r);//先成挖坑填数法调整s[] 6 quick_sort1(s, l, i - 1); // 递归调用 7 quick_sort1(s, i + 1, r); 8 } 9 }
这样的代码显然不够简洁,对其组合整理下:
1 //快速排序 2 void quick_sort(int s[], int l, int r) 3 { 4 if (l < r) 5 { 6 //Swap(s[l], s[(l + r) / 2]); //将中间的这个数和第一个数交换 参见注1 7 int i = l, j = r, x = s[l]; 8 while (i < j) 9 { 10 while(i < j && s[j] >= x) // 从右向左找第一个小于x的数 11 j--; 12 if(i < j) 13 s[i++] = s[j]; 14 15 while(i < j && s[i] < x) // 从左向右找第一个大于等于x的数 16 i++; 17 if(i < j) 18 s[j--] = s[i]; 19 } 20 s[i] = x; 21 quick_sort(s, l, i - 1); // 递归调用 22 quick_sort(s, i + 1, r); 23 } 24 }
快速排序还有很多改进版本,如随机选择基准数,区间内数据较少时直接用另的方法排序以减小递归深度。有兴趣的筒子可以再深入的研究下。
注1,有的书上是以中间的数作为基准数的,要实现这个方便非常方便,直接将中间的数和第一个数进行交换就可以了。
七:白话经典算法系列之七 堆与堆排序
二叉堆的定义
二叉堆是完全二叉树或者是近似完全二叉树。
二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。下图展示一个最小堆:
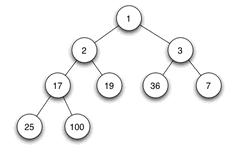
由于其它几种堆(二项式堆,斐波纳契堆等)用的较少,一般将二叉堆就简称为堆。
堆的存储
一般都用数组来表示堆,i结点的父结点下标就为(i – 1) / 2。它的左右子结点下标分别为2 * i + 1和2 * i + 2。如第0个结点左右子结点下标分别为1和2。

堆的操作——插入删除
下面先给出《数据结构C++语言描述》中最小堆的建立插入删除的图解,再给出本人的实现代码,最好是先看明白图后再去看代码。
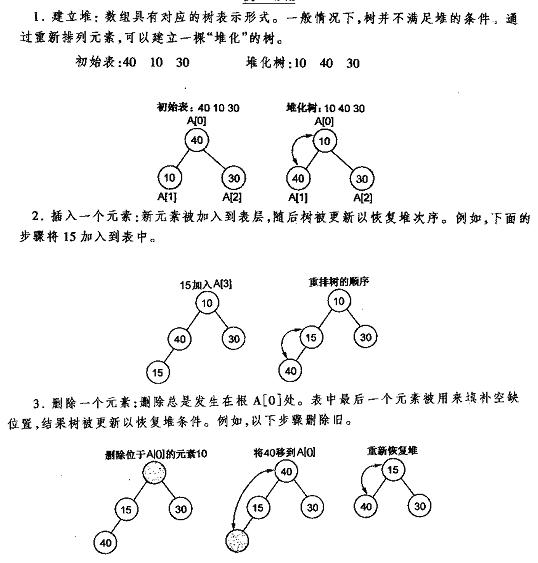
堆的插入
每次插入都是将新数据放在数组最后。可以发现从这个新数据的父结点到根结点必然为一个有序的数列,现在的任务是将这个新数据插入到这个有序数据中——这就类似于直接插入排序中将一个数据并入到有序区间中,对照《白话经典算法系列之二 直接插入排序的三种实现》不难写出插入一个新数据时堆的调整代码:
1 // 新加入i结点 其父结点为(i - 1) / 2 2 void MinHeapFixup(int a[], int i) 3 { 4 int j, temp; 5 6 temp = a[i]; 7 j = (i - 1) / 2; //父结点 8 while (j >= 0 && i != 0) 9 { 10 if (a[j] <= temp) 11 break; 12 13 a[i] = a[j]; //把较大的子结点往下移动,替换它的子结点 14 i = j; 15 j = (i - 1) / 2; 16 } 17 a[i] = temp; 18 }
更简短的表达为:
1 void MinHeapFixup(int a[], int i) 2 { 3 for (int j = (i - 1) / 2; (j >= 0 && i != 0)&& a[i] > a[j]; i = j, j = (i - 1) / 2) 4 Swap(a[i], a[j]); 5 }
插入时:
1 //在最小堆中加入新的数据nNum 2 void MinHeapAddNumber(int a[], int n, int nNum) 3 { 4 a[n] = nNum; 5 MinHeapFixup(a, n); 6 }
堆的删除
按定义,堆中每次都只能删除第0个数据。为了便于重建堆,实际的操作是将最后一个数据的值赋给根结点,然后再从根结点开始进行一次从上向下的调整。调整时先在左右儿子结点中找最小的,如果父结点比这个最小的子结点还小说明不需要调整了,反之将父结点和它交换后再考虑后面的结点。相当于从根结点将一个数据的“下沉”过程。下面给出代码:
1 // 从i节点开始调整,n为节点总数 从0开始计算 i节点的子节点为 2*i+1, 2*i+2 2 void MinHeapFixdown(int a[], int i, int n) 3 { 4 int j, temp; 5 6 temp = a[i]; 7 j = 2 * i + 1; 8 while (j < n) 9 { 10 if (j + 1 < n && a[j + 1] < a[j]) //在左右孩子中找最小的 11 j++; 12 13 if (a[j] >= temp) 14 break; 15 16 a[i] = a[j]; //把较小的子结点往上移动,替换它的父结点 17 i = j; 18 j = 2 * i + 1; 19 } 20 a[i] = temp; 21 } 22 //在最小堆中删除数 23 void MinHeapDeleteNumber(int a[], int n) 24 { 25 Swap(a[0], a[n - 1]); 26 MinHeapFixdown(a, 0, n - 1); 27 }
堆化数组
有了堆的插入和删除后,再考虑下如何对一个数据进行堆化操作。要一个一个的从数组中取出数据来建立堆吧,不用!先看一个数组,如下图:
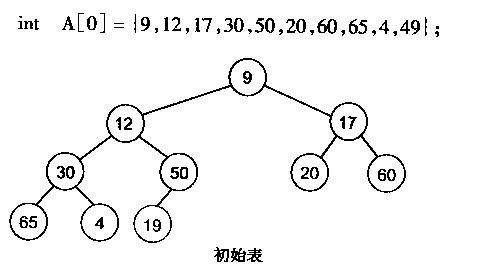
很明显,对叶子结点来说,可以认为它已经是一个合法的堆了即20,60, 65, 4, 49都分别是一个合法的堆。只要从A[4]=50开始向下调整就可以了。然后再取A[3]=30,A[2] = 17,A[1] = 12,A[0] = 9分别作一次向下调整操作就可以了。下图展示了这些步骤:
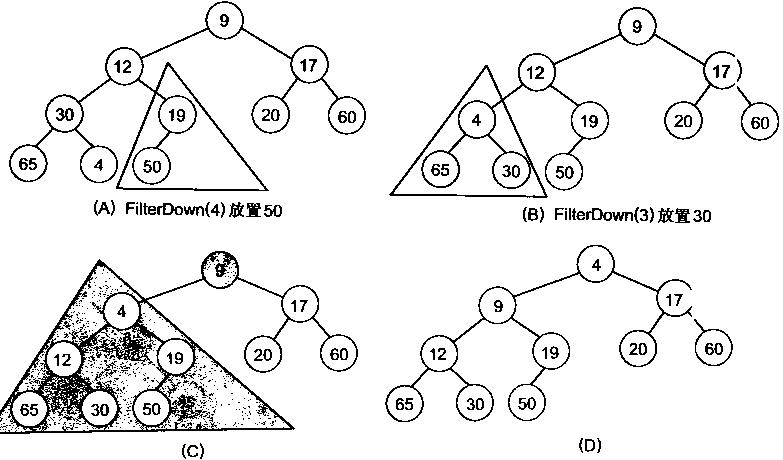
写出堆化数组的代码:
1 //建立最小堆 2 void MakeMinHeap(int a[], int n) 3 { 4 for (int i = n / 2 - 1; i >= 0; i--) 5 MinHeapFixdown(a, i, n); 6 }
至此,堆的操作就全部完成了(注1),再来看下如何用堆这种数据结构来进行排序。
堆排序
首先可以看到堆建好之后堆中第0个数据是堆中最小的数据。取出这个数据再执行下堆的删除操作。这样堆中第0个数据又是堆中最小的数据,重复上述步骤直至堆中只有一个数据时就直接取出这个数据。
由于堆也是用数组模拟的,故堆化数组后,第一次将A[0]与A[n - 1]交换,再对A[0…n-2]重新恢复堆。第二次将A[0]与A[n – 2]交换,再对A[0…n - 3]重新恢复堆,重复这样的操作直到A[0]与A[1]交换。由于每次都是将最小的数据并入到后面的有序区间,故操作完成后整个数组就有序了。有点类似于直接选择排序。
1 void MinheapsortTodescendarray(int a[], int n) 2 { 3 for (int i = n - 1; i >= 1; i--) 4 { 5 Swap(a[i], a[0]); 6 MinHeapFixdown(a, 0, i); 7 } 8 }
注意使用最小堆排序后是递减数组,要得到递增数组,可以使用最大堆。
由于每次重新恢复堆的时间复杂度为O(logN),共N - 1次重新恢复堆操作,再加上前面建立堆时N / 2次向下调整,每次调整时间复杂度也为O(logN)。二次操作时间相加还是O(N * logN)。故堆排序的时间复杂度为O(N * logN)。STL也实现了堆的相关函数,可以参阅《STL系列之四 heap 堆》。
注1 作为一个数据结构,最好用类将其数据和方法封装起来,这样即便于操作,也便于理解。此外,除了堆排序要使用堆,另外还有很多场合可以使用堆来方便和高效的处理数据,以后会一一介绍。
自己的代码:
1 <span style="font-size:18px;">#include <iostream> 2 using namespace std; 3 4 //交换两个数的值 5 inline void Swap(int &i,int &j) 6 { 7 int temp; 8 if(i != j) 9 { 10 temp = i; 11 i = j; 12 j = temp; 13 } 14 15 } 16 17 //冒泡排序算法1 18 //a代表排序数组,n代表数组中元素的个数,下标从0开始。 19 //这个算法是:大的元素上浮经过比较后上浮。 20 void BubbleSort(int a[],int n) 21 { 22 int i,j; 23 int temp = false;//初始为false,如果发生过交换就变为true 24 for(i = 1; i <= n - 1; i++)//只需要排序n - 1趟就可以排序成功 25 { 26 for(j = 0; j < n - i; j++) //一趟排序 27 { 28 if(a[j] > a[j + 1]) //大的元素上浮 29 Swap(a[j],a[j + 1]); 30 temp = true; 31 } 32 if (temp == false) 33 break; 34 } 35 } 36 void BubbleSort2(int a[],int n) 37 { 38 int flag;//标志位置 39 int i; 40 flag = true;//初始为空 41 int length = n; 42 while(flag) 43 { 44 flag = false; 45 for(i = 0;i < length - 1; i++) 46 { 47 if(a[i] > a[i + 1]) 48 { 49 Swap(a[i], a[i + 1]); 50 flag = true; 51 } 52 } 53 length --; 54 } 55 } 56 57 //改进算法3 58 void BubbleSort3(int a[],int n) 59 { 60 int temp = n - 1;//temp是循环需要遍历到的最后节点位置,初始 为 n - 1。 61 int i,flag = true; 62 int k; 63 while(flag) 64 { 65 flag = false; 66 k = temp; 67 for(i = 0; i < k; i++) 68 { 69 if(a[i] > a[i + 1]) 70 { 71 Swap(a[i],a[i + 1]); 72 temp = i + 1; 73 flag = true; 74 } 75 } 76 temp --; 77 } 78 } 79 80 //直接插入排序算法,n代表数组元素中的个数。 81 //从第一个元素位置往后寻找插入位置 82 void InsertSort(int a[],int n) 83 { 84 int i,j; 85 for(i = 1; i < n; i++) 86 { 87 //找到合适的插入位置的下标 88 for(j = 0; j < i; j++) 89 { 90 if(a[j] <= a[i]) 91 ; 92 else 93 break; 94 } 95 while(i > j) 96 { 97 Swap(a[i],a[i - 1]); 98 i --; 99 } 100 } 101 } 102 103 //代码简化,搜索和数据后移数据一块操作。 104 void InsertSort2(int a[],int n) 105 { 106 int i,j; 107 int temp;//temp记录 插入元素的值 108 //从后往前找插入位置,查找插入位置和数据移动一并操作。 109 // 110 for(i = 1; i < n; i++) 111 { 112 temp = a[i];// 113 j = i - 1; 114 while( temp < a[j] && j >= 0) 115 { 116 a[j + 1] = a[j]; 117 j--; 118 } 119 a[j + 1] = temp;//将插入元素放入合适位置 120 } 121 } 122 123 //进一步简化插入排序版本,用Swap函数就不用一个专门的值来记录插入节点的值。 124 void InsertSort3(int a[],int n) 125 { 126 int i,j; 127 for(i = 1; i < n; i++) 128 { 129 for(j = i - 1; j >= 0 && a[j] > a[j + 1]; j--) 130 { 131 Swap(a[j],a[j + 1]); 132 } 133 } 134 } 135 136 //最初版本,完全没有一点改进的版本,适合最初理解。 137 void ShellSortWorst(int a[],int n) 138 { 139 int i,j,k,gap; 140 int temp; 141 for(gap = n / 2; gap > 0; gap /= 2) 142 { 143 //对每个小组进行直接插入排序 144 for(i = 0;i < gap; i++) 145 { 146 for(j = i + gap; j < n; j += gap) 147 { 148 if(a[j] < a[j - gap])// 如果可以插入 149 { 150 temp = a[j]; 151 k = j - gap; 152 while(k >= 0 && a[k] > temp) 153 { 154 a[k + gap] = a[k]; 155 k -= gap; 156 } 157 a[k + gap] = temp; 158 } 159 } 160 } 161 } 162 } 163 //希尔排序的改进版本,a[]数组,n代表数组元素的数量,jump代表跳跃长度。 164 void ShellSortJump(int a[],int n,int jump) 165 { 166 int i,j; 167 int temp; 168 //根据Jump的值来进行一趟直接插入排序的排序 169 for(i = jump; i < n; i++)//从数组第Jump个元素开始 170 { 171 //每个元素与自己组内的数据进行直接插入排序 172 if(a[i] < a[i - jump]) 173 { 174 temp = a[i];//记录下 插入元素的值 175 j = i - jump; 176 while(j >= 0 && a[j] > temp) 177 { 178 a[j + jump] = a[j]; 179 j = j -jump; 180 } 181 a[j + jump] = temp; 182 } 183 } 184 } 185 //希尔排序 186 void ShellSort(int a[],int n) 187 { 188 int jump; 189 jump = n/2; 190 do 191 { 192 ShellSortJump(a,n,jump); 193 jump = jump /2; 194 }while(jump >= 1); 195 } 196 //合并一起 197 void ShellSort2(int a[],int n) 198 { 199 int i , j, gap; 200 int temp; 201 for(gap = n/2; gap > 0;gap /= 2)//跳跃长度 202 { 203 for(i = gap; i < n; i++) 204 { 205 if(a[i] < a[i - gap]) 206 { 207 temp = a[i]; 208 j = i - gap; 209 while(j >= 0 && a[j] > temp) 210 { 211 a[j + gap] = a[j]; 212 j = j - gap; 213 } 214 a[j + gap] = temp; 215 } 216 217 } 218 } 219 } 220 221 //希尔排序最终简化版本 222 void ShellSort3(int a[],int n) 223 { 224 int i, j, gap; 225 for(gap = n / 2; gap > 0; gap /= 2) 226 { 227 for(i = gap; i < n; i++) 228 { 229 for(j = i - gap; j >= 0 && a[j] > a[j + gap];j -= gap) 230 Swap(a[j],a[j + gap]); 231 } 232 } 233 } 234 235 //直接选择排序 236 void SelectSort(int a[],int n) 237 { 238 int s;//记录最小元素的下标 239 int i, j; 240 for(i = 0; i < n; i++) 241 { 242 s = i; 243 for(j = i + 1; j < n; j ++)//从无序区从找寻最小的值的下标 244 { 245 if(a[j] < a[s]) 246 s = j; 247 } 248 Swap(a[s],a[i]); 249 } 250 } 251 252 //快速排序 253 int QuickSortGetIndex(int a[],int start,int end) 254 { 255 int i = start, j = end; 256 int temp = a[start]; 257 while(i < j) 258 { 259 //从后往前找第一个比temp小的元素下标 260 while(i < j && a[j] >= temp) 261 j--; 262 if(i < j) 263 { 264 a[i] = a[j]; 265 i ++; 266 } 267 //从前往后找第一个比temp大的元素下标 268 while(i < j && a[i] < temp) 269 i++; 270 if(i < j) 271 { 272 a[j] = a[i]; 273 j--; 274 } 275 } 276 a[i] = temp; 277 return i; 278 } 279 //快速排序分治法 280 void Quick_Sort(int a[],int start,int end) 281 { 282 int index; 283 if(start < end) 284 { 285 index = QuickSortGetIndex(a,start,end); 286 Quick_Sort(a, start, index - 1); 287 Quick_Sort(a, index + 1, end); 288 } 289 } 290 291 292 293 //快速排序合并版本 294 void Quick_Sort2(int a[],int start,int end) 295 { 296 297 if(start < end) 298 { 299 int i = start, j = end, temp = a[start]; 300 while(i < j) 301 { 302 while(i < j && a[j] > temp) 303 j--; 304 if(i < j) 305 a[i++] = a[j]; 306 while(i < j && a[i] < temp) 307 i++; 308 if(i < j) 309 a[j--] = a[i]; 310 } 311 a[i] = temp; 312 Quick_Sort2(a, start, i - 1); 313 Quick_Sort2(a, i + 1, end); 314 } 315 316 } 317 318 //快速排序 319 void QuickSort(int a[],int n) 320 { 321 Quick_Sort2(a,0,n - 1); 322 } 323 324 void PrintArray(int a[],int n) 325 { 326 int i = 0; 327 for(;i < n;i++) 328 cout << a[i] << " "; 329 cout << endl; 330 } 331 int main() 332 { 333 int a[15] = {10,9,8,7,6,5,4,3,2,1,22,13,35,55,12}; 334 //InsertSort3(a,10); 335 //SelectSort(a,15); 336 QuickSort(a,15); 337 PrintArray(a,15); 338 339 return 0; 340 } 341 </span>