概念
数据 data
数据库 database
数据库管理系统 DBMS
数据库管理员 DBA

数据库的分类
关系型: mysqloracle sqlite sql server 适合我们在存取数据的时候 字段不确定的情况下
非关系型: redismongdb 我们总是用一个固定的字段来获取某些信息 并且对数据的存取速度要求都非常高
区别
1)mysql :关系型数据库,用于持久化的存储数据到硬盘,功能强大,但读取速度较慢
2)redis :非关系型数据库,也是缓存数据库,用于存储使用 较为频繁的数据 到缓存中,读取速度快 ,持久化是使用AOF和rdb方式,支持事务,存储小量的数据
3)mongodb: 不支持事务,支持查询的语言比较多(json,xml,bson),适合大数据量的存储
应用场景
redis:数据量较小的更性能操作和运算上
MongoDB:主要解决海量数据的访问效率问题
redis 和memcache的区别
1、Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例 如图片、视频等等。
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3、虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
4、过期策略–memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10
5、分布式–设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从
6、存储数据安全–memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
7、灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
8、Redis支持数据的备份,即master-slave模式的数据备份。
总结
有持久化需求或者对数据结构和处理有高级要求的应用,选择redis,其他简单的key/value存储,选择memcache。
mysql客户端的启动:
-
在cmd里执行
mysql -uroot -p
Enter password:
root默认的用户 权限相对大 -
在mysql的客户端执行
mysql> exit # 退出客户端
-
在cmd中执行的 服务端的启停:
net start mysql
net stop mysql
mysql 导入 导出
导出(备份)所有:
语法:mysqldump -u root -p 库名 > 路劲/新名字 (注:路经后边不能有中文)
mysqldump -u root -p --all-databases > /tmp/db.dump
导出db1、db2两个数据库的所有数据
mysqldump -uroot -proot --databases db1 db2 >/tmp/user.sql
mysqldump -uroot -p -B db1 db2 >/tmp/user.sql
导入:
Mysql -uroot -p < /opt/all db.sql
mysql>source /data/all.sql;
其实导出的是库里面的表,要想导入,先建一个database库,进入库里边后再source.


存储引擎
- Innodb:默认使用mysql5.6
特点: 支持事务行级锁外键
事务: 事务由单独单元的一个或者多个sql语句组成,在这个单元中,每个mysql语句时相互依赖的。而整个单独单元作为一个不可分割的整体,
n句sql是一个完整的事件,这n句sql要么一起成功,要么一起失败(转账)
事务的四个特性:
原子性(Atomicity):所有操作要么全部成功,要么全部失败回滚
一致性(Consistency):事务必须使数据库从一个一致性状态变换到另一个一致性状态
隔离性(Isolation):一个事务的执行不能让其它事务干扰
持久性(Durability):事务一旦结束,数据就持久到数据库
行级锁: 优点: 能够支持更多的修改数据的并发操作; 缺: 修改的行数太多,效率会受影响
表级锁:
缺点: 不支持并发的修改同一张表中的数据;
优:不需要加很多锁,,效率高
外键: 在本表中有一个字段 关联 外表中的另一个字段
为什么要用innodb做存储引擎?
因为他是mysql5.6 以上默认使用的,考虑到程序今后的扩展,我要用支持事务的inndb,并且并发的删除和修改的效率比其他引擎高一些
- myisam: 默认使用mysql5.5
特点:表级锁
3)memory: 缓存的存储方式 内存
特点:读取快,不能完成数据的持久化存储,断电数据就会消失
4)blackhole :黑洞
特点: 集群(多台mysql服务,提供高可用的时候涉及到的一种存储引擎) 多级主从复制中的一台机器上的数据库常用的存储引擎
创建表
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
例:
mysql> create table staff_info (id int,name char(10),age int(3),sex enum('male', 'female'), phone char(11),job char(12));
2) 查看表结构
desc (describe) 表名; 查看表的基础信息
show create table 表名 G; 查看表的详细信息(编码 和 存储引擎)
3)修改表结构

基础数据类型
1) 数值类型
Int 整型的长度约束,实际没效果
Float 小数: float(n,m) 这个数据总长度n,小数点后为m 如:(126,45)
2) 日期时间类型
now()
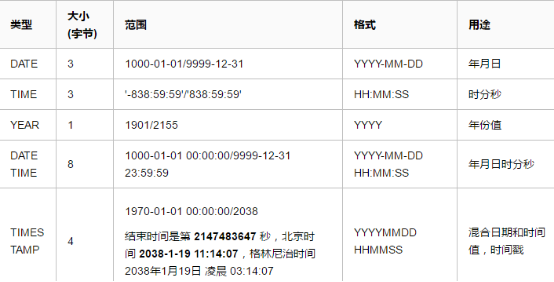
datetime : 允许为空,没有默认值,能够表示的时间范围大
timestamp :不允许为空,默认值是当前时间,能够表示的时间范围小,超出范围表示为 0000-00-00 00:00:00
如果同一个表中有两个该字段,只有第一个字段会被表示为默认当前时间
3) 字符串格式
char: 定长,存储相对浪费空间,存取速度快,不管你存储什么样的数据,他都会帮你把数据的空格在显示的时候去掉
varchar: 变长,相对节省空间,存取效率相对慢
检验:
concat(ch,'+')字符串格式
4) ENUM和SET类型
enum 枚举 单选+不能选不在枚举范围里的
set 集合 多选+去重+不能选不在集合里的
例
create table t9 (name char(20),gender enum('female','male'))
# 多选框--程序中 勾选
create table t10 (name char(20),hobby set('抽烟','喝酒','烫头','翻车'))
5) 表的约束
(1)Not null 非空
unique 唯一:不能重复输入非空的内容,但可以输入多个null
(2) primary key 主键:非空+唯一 一张表只能有一个主键,其他的还是维持原来的约束

6) 外键
外键(foreign key)所关联的外表中的那个字段必须是唯一的,建议关联外表的主键
创建外键
create table staff_info (s_id int,name varchar(20),dep_id int,foreign key(dep_id) references departments(dep_id));
增加外键
语法:alter table 表名 add constraint FK_ID foreign key(你的外键字段名) REFERENCES 外表表名(对应的表的主键字段名); //FK_ID是外键的名称
alter table book add constraint fk_id foreign key(press_id) references press(id);
删除外键
语法: ALTER TABLE 表名 DROP FOREIGN KEY 外键字段名;
7) 设置自增字段
unique auto_increment 至少是唯一的才可以
default 关键字 # 设置一个默认值
例 删除某个字段
方式一:删除class里某一个字段
create table class (id int,class_name char(12));
alter table class modify id int unique; 关联外键,字段至少唯一
create table stu (id int,stu_name char(20),class_id int,foreign key (class_id)
references class(id));
先删除stu里所关联class的id的字段
delete from class where id =1;
才能删class里对应的字段:
delete from class id=1;
方式二:删除外键所关联的多个字段(直接删除)
加上on update cascade on delete cascade(连级删除或更新)
create table class (id int primary key,class_name char(12));
关联外键,字段至少唯一
create table stu (id int primary key,stu_name char(20),class_id int,foreign key (class_id) references class(id) on update cascade on delete cascade);
数据的增删改查
1)增加数据
insert into 表名 value (1,'alex',83,'不详'); 一次插入一条数据
insert into 表名 values (1,'alex',83,'不详'),(2,'wusir',74,'male'); 支持一次写入多条数据
insert into 表名 (name,age,sex) values ('alex',83,'不详');
2) 修改数据
update 表名 set 字段名=值 where 条件
update 表名 set(修改成啥) 字段名1=值1,字段名2=值2 where 条件(在那一行)
3) 删除数据
delete from 表 where 条件;
delete from 表; 清空表
auto_increment 自增字段 至少是(int unique)
select * from 表名; * 表示所有的内容
select 字段1,字段2 from 表; 表示查指定的列的内容
select distinct 字段名 from 表; distinct关键字表示去重
在select字段可以使用四则(加减乘除)运算
select 字段*12 from 表
select 字段 as 新字段名 from 表 给字段重命名
两个格式化函数
concat() concat_ws()
concat('自己想拼的内容',字段,'你想拼的内容');
Select concat('姓名:',emp_name,'年薪:',salary) AS annual_salary from employee;
concat_ws(':',字段1,字段2)
Case语句
SELECT
(
CASE
WHEN emp_name = 'jingliyang' THEN
emp_name
WHEN emp_name = 'alex' THEN
CONCAT(emp_name,'_BIGSB')
ELSE
concat(emp_name, 'SB')
END
) as new_name
FROM
employee;
where条件
对表当中的数据进行一个条件的筛选
对一个值的判断 = > < != <> >= <=
对一个范围的判断 between 小的值 and 大的值 [小的值,大的值]
select emp_name,salary from employee where salary between 10000 and 20000;
关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS)
select emp_name,post_comment from employee where post_comment is not null;
**模糊匹配 **
like '%a_'
regext :字段名 ‘^d{15}$’
'a'的名字
'%a'以a结尾,'a%'表示以a开头,'%a%'表示匹配中间带个a的字符串
'%'通配符 匹配任意长度的任意内容
SELECT * FROM employee
WHERE emp_name LIKE 'eg%';
'a' 表示任意的一个字符a,'a_'以a开头后面是任意的两个字符
'_' 匹配一个长度的任意内容
逻辑运算符
and 两个条件必须都成立 才算成立
or 只要有一个条件成立就成立
not 非
SELECT emp_name,salary FROM employee
WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ;
SELECT emp_name,salary FROM employee
WHERE salary IN (3000,3500,4000,9000) ;
SELECT emp_name,salary FROM employee
WHERE salary NOT IN (3000,3500,4000,9000) ;
group by 分组(带去重的功能)
1) select 数据 from 表 where 条件 group by 分组
select post from employee where depart_id > 1;
结果 是 有多少个部门 就有多少条数据
2) GROUP BY关键字和GROUP_CONCAT()函数一起使用
select post,group_concat(emp_name) from employee where depart_id<3 group by post; 结果是符合条件里的部门的所有人名字
聚合函数
count(字段) 统计有多少条记录是符合条件的 只统计字段不为空的那一行数据
count(*) # count(1) # min # max # avg # sum
order by 排序
默认是升序
降序 从大到小排 desc
SELECT * FROM employee ORDER BY salary DESC;
limit限制
limit n 取n个
limit m,n 从m +1 开始 取n条
limit n offset m 从m+1开始 取n个
**having **
对group by 分组后的结果进行过滤和筛选
能够 使用聚合函数
Having: 如果是group by 用到的关键字, select 当中用到的名字 聚合函数要用到的名字
优先级
FROM 表名
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数
.多表查询
Select * from 表一,表二
1.连表查询:
用的是on连接
1) 内连接 (inner join) :只有两张表中条件互相匹配上的项才能被显示出来
select 字段 from 表1 inner join 表2 on 条件
select * from class inner join stu on stu.class_id = class.id;
等同于
Select * from class,stu where stu.class_id = class.id
2) 外链接
左外链接(left join):会完整的显示左表,根据条件显示右表
select 字段 from 表1 left join 表2 on 条件
右外链接(right join):会完整的显示右表,根据条件显示左表
select 字段 from 表1 right join 表2 on 条件
全外链接
用union连接
from 表1 left join 表2 on 条件 union 表1 right join 表2 on 条件
select * from employee as emp left join department as dep on emp.dep_id = dep.id
union
select * from employee as emp right join department as dep on emp.dep_id = dep.id;
2.子查询 (效率比连表查询低)
在一条sql中两个select,并且一个select的结果是另一个select的条件
用的是 in 连接
select * from 表1 where 字段 = (select 字段 from 表2 where 条件 = 值)
select * from 表1 where 字段 in (select 字段 from 表2 where 条件 = 值)
索引
1.索引原理
索引的目的在于提高查询效率
有什么好处坏处:占空间,拖慢写的速度
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据
索引越多,占用磁盘空间越大,修改表时对索引 的重构和更新很麻烦
2.对哪些字段添加索引
1、表的主键、外键必须有索引;
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B、复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8、频繁进行数据操作的表,不要建立太多的索引;
9、删除无用的索引,避免对执行计划造成负面影响
创建索引:
Create index age on student(age)
删除索引
drop index 索引名字 on索引的表
1.b+树 以平衡树为基础的
1).所有的非叶子结点不存储真实的数据
2).所有的叶子结点之间都被添加了双向链表
2. innodb和myisam的索引的存储方式
innodb 内部 有一个 聚集索引(聚簇索引),非聚集索引
myisam 内部 没有聚集索引 ,所有索引都是非聚集索引
3. 索引的种类
primary key: 除了约束 非空 + 唯一之外 还有其他的作用 聚集索引
unique: 约束 唯一 非聚集索引的作用
index: 没有约束的作用 普通的非聚集索引
联合唯一索引
联合主键索引
联合索引
4. 正确使用索引
1.条件必须是已经创建了索引的列
2.如果在条件中对索引列使用了范围,并且这个范围很大,速度就很慢 > < != between and not in
3.like条件 后面 必须是 'abc%' ,如果 like '%abbasff'
4.确认使用的索引列的区分度 选择区分度低的列作为索引实际上并不能有加速查找的效果
5.索引列在条件中不能参与计算
6.and和or
and/or
使用and条件的时候 mysql在优化查询的时候会有限选择区分度高的列先查询,来缩小其他条件要查询的范围
or 只会从左到右依次进行判断
所有条件中出现的列区分度都需要很高
对每一个字段都要添加索引
**5.联合索引(重复值比较多时用它)
联合索引是指对表上的多个列合起来做一个索引
create index 索引名 on 表名(字段1,字段2...);
create index name_email on s1(name,email);
最左前缀原则
# s1(name,email)
# sql语句中条件必须含有name这个字段**
6.覆盖索引
InnoDB存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询记录,而不需要查询聚集索引中的记录。(不需要再回表查了)
例子:
s elect name from 表 where id =10000 # 用到索引了 ,但是不是覆盖索引
select id from 表 where id =10000 # 用到索引了 ,也是覆盖索引
mysql 连接数据库
1.在终端提交事务
begin; # 开启事务
select * from emp where id = 1 for update; # 查询id值,for update添加行锁;
update emp set salary=10000 where id = 1; # 完成更新
commit; # 提交事务
2.使用python 操作mysql数据库
import pymysql
conn = pymysql.connect(
host='localhost', user='root', password="root",
database='db', port=3306, charset='utf-8', )
cur = conn.cursor(cursor=pymysql.cursors.DictCursor)
创建一个游标对象
# 游标里什么都不写是元祖形式,写上.cursors.DictCursor 就是字典形式
sql2 = 'select sname from student for update;', 添加一个锁
cursor.execute('select * from s1 where email="eva2300@oldboy" or email="eva6666@oldboy"')
ret = cursor.fetchmany(2) # 取几就打印几个
fetchall() # 全取
fetchone() #只取一个
print(ret)
conn.commit() # 提交到数据库
conn.close()
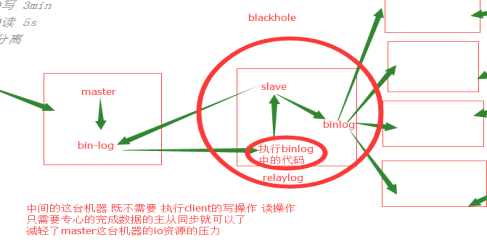
简述mysql主从复制原理?
(1) master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2) slave将master的binary log events拷贝到它的中继日志(relay log);
(3) slave重做中继日志中的事件,将改变反映它自己的数据。
总结:
查
单表查
select distinct * from 表 where 条件 group by 字段 having 过滤条件 order by 字段 limit n,m;
聚合函数 : sum avg max min count
分组聚合 : 求某个商品的平均价格,总销量,求部门的最高工资,求本月平均打卡时间最早的
多表查
多表查询
连表查询
inner join
left join
right join
子查询
在一条sql中两个select,并且一个select的结果是另一个select的条件
推荐连表查询的效率高
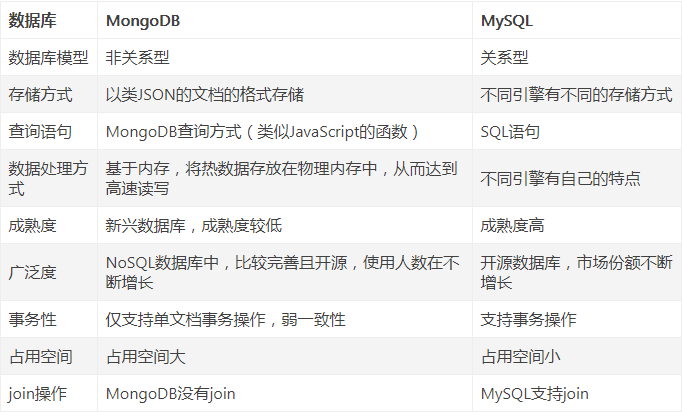
四, mongodb与MySQL的不同有哪些
爱喝马黛茶的安东尼爱喝马黛茶的安东尼2020-01-03 11:03:12原创4175
MySQL与MongoDB都是开源的常用数据库,但是MySQL是传统的关系型数据库,MongoDB则是非关系型数据库,也叫文档型数据库,是一种NoSQL的数据库。它们各有各的优点,关键是看用在什么地方。所以我们所熟知的那些SQL语句就不适用于MongoDB了,因为SQL语句是关系型数据库的标准语言。
一、关系型数据库-MySQL
1、在不同的引擎上有不同的存储方式。
2、查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高。
3、开源数据库的份额在不断增加,mysql的份额页在持续增长。
4、缺点就是在海量数据处理的时候效率会显著变慢。
二、非关系型数据库-MongoDB
非关系型数据库(nosql ),属于文档型数据库。先解释一下文档的数据库,即可以存放xml、json、bson类型系那个的数据。这些数据具备自述性,呈现分层的树状数据结构。数据结构由键值(key=>value)对组成。
1、存储方式:虚拟内存+持久化。
2、查询语句:是独特的MongoDB的查询方式。
3、适合场景:事件的记录,内容管理或者博客平台等等。
4、架构特点:可以通过副本集,以及分片来实现高可用。
5、数据处理:数据是存储在硬盘上的,只不过需要经常读取的数据会被加载到内存中,将数据存储在物理内存中,从而达到高速读写。
6、成熟度与广泛度:新兴数据库,成熟度较低,Nosql数据库中最为接近关系型数据库,比较完善的DB之一,适用人群不断在增长。
三、MongoDB优势与劣势
优势:
1、在适量级的内存的MongoDB的性能是非常迅速的,它将热数据存储在物理内存中,使得热数据的读写变得十分快。
2、MongoDB的高可用和集群架构拥有十分高的扩展性。
3、在副本集中,当主库遇到问题,无法继续提供服务的时候,副本集将选举一个新的主库继续提供服务。
4、MongoDB的Bson和JSon格式的数据十分适合文档格式的存储与查询。
劣势:
1、 不支持事务操作。MongoDB本身没有自带事务机制,若需要在MongoDB中实现事务机制,需通过一个额外的表,从逻辑上自行实现事务。
2、 应用经验少,由于NoSQL兴起时间短,应用经验相比关系型数据库较少。
3、MongoDB占用空间过大。
四、对比
TOP PERCENT 实例
使用百分比作为参数
例: SQL 语句从 websites 表中选取前面百分之 50 的记录
SELECT TOP 50 PERCENT * FROM Websites;
使用 SQL [charlist] 通配符
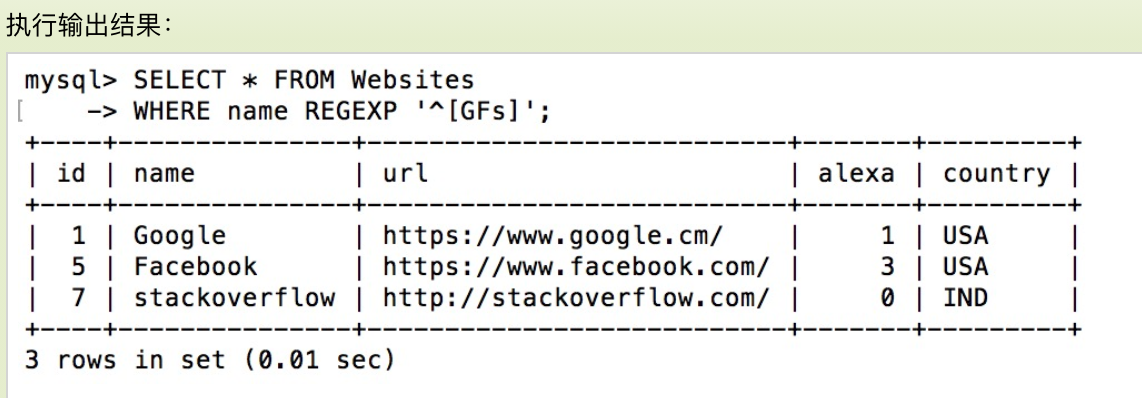
MySQL 中使用 REGEXP 或 NOT REGEXP 运算符 (或 RLIKE 和 NOT RLIKE) 来操作正则表达式。
下面的 SQL 语句选取 name 以 "G"、"F" 或 "s" 开始的所有网站:
SELECT * FROM Websites
WHERE name REGEXP '^[GFs]';
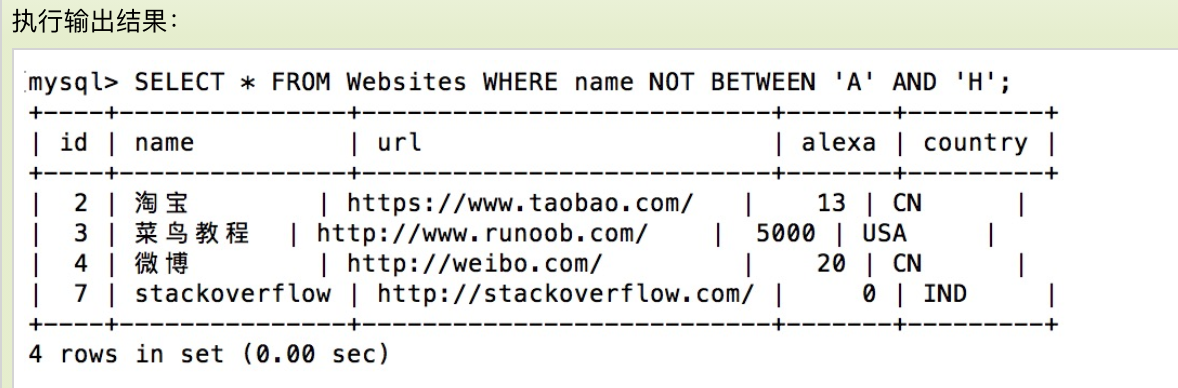
带有文本值的 NOT BETWEEN 操作符实例
下面的 SQL 语句选取 name 不介于 'A' 和 'H' 之间字母开始的所有网站:
实例
SELECT * FROM Websites
WHERE name NOT BETWEEN 'A' AND 'H';
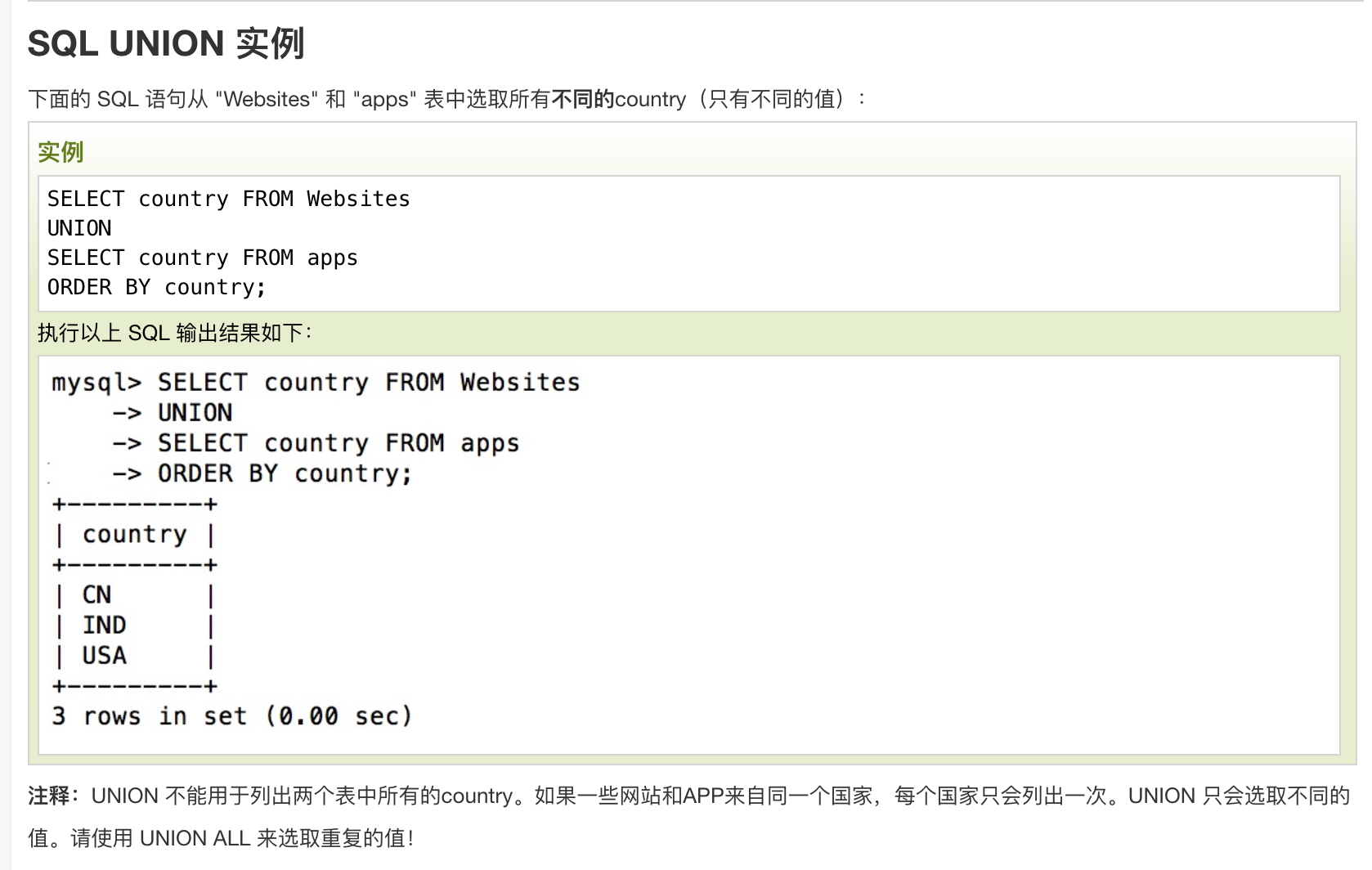
UNION 操作
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
SQL UNION 语法
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
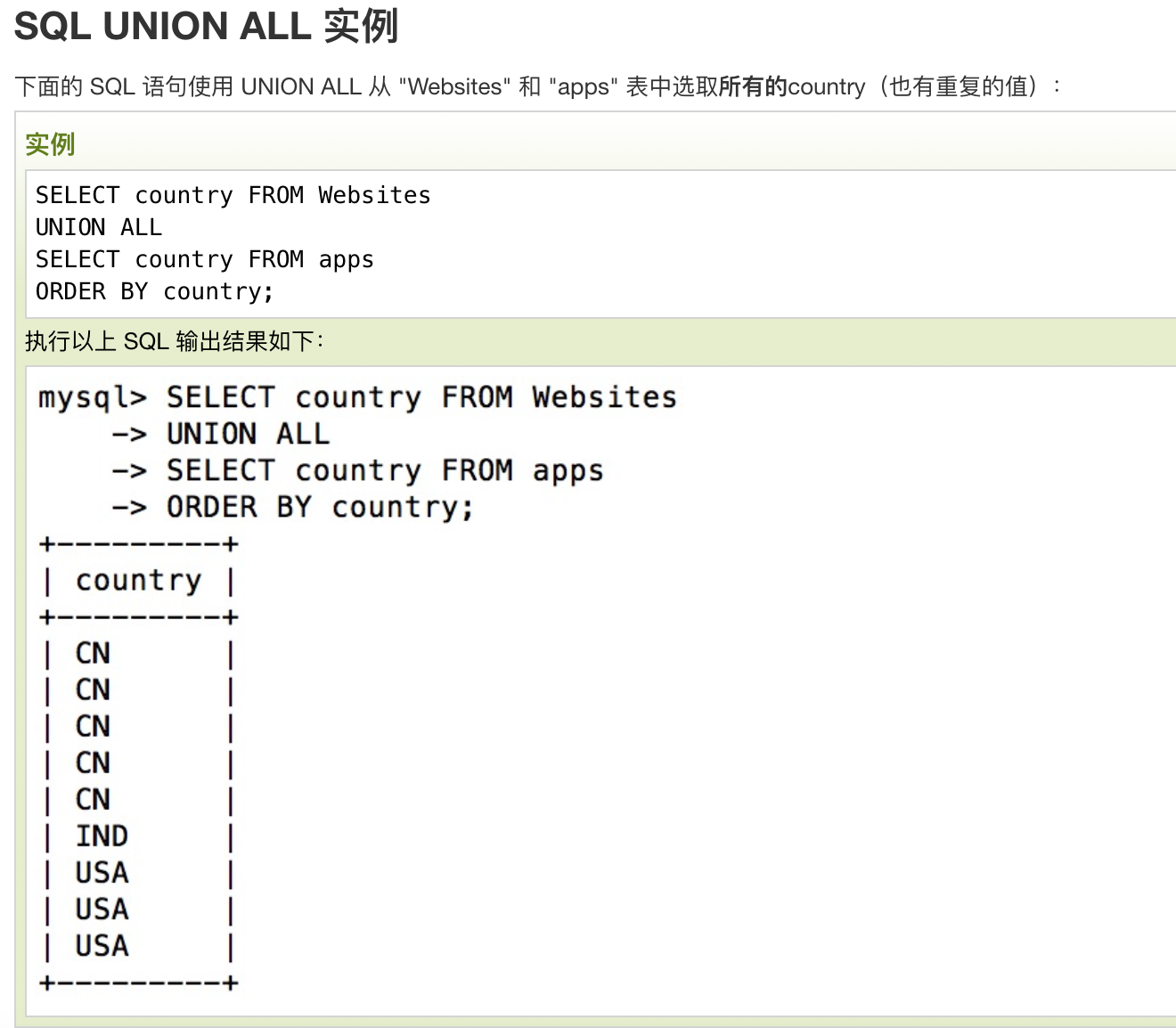
SQL UNION ALL 语法
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;
注释:UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
{{uploading-image-259436.png(uploading...)}}
insert into select 语句
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中。目标表中任何已存在的行都不会受影响
insert into selec 语法
我们可以从一个表中复制所有的列插入到另一个已存在的表中:
INSERT INTO table2
SELECT * FROM table1;
或者我们可以只复制希望的列插入到另一个已存在的表中:
INSERT INTO table2
(column_name(s))
SELECT column_name(s)
FROM table1;
select into from 和 insert into select from和create table as select * from 都是用来复制表
select into from不是用在sql 的
两者的主要区别为:
select into from 和 create table as select * from 要求目标表不存在,因为在插入时会自动创建;insert into select from 要求目标表存在。所以我们除了插入源表source_table的字段外,还可以插入常量,如sql语句:
1.新表不存在
复制表结构即数据到新表
create table new_table
select * from old_talbe;
这种方法会将old_table中所有的内容都拷贝过来,用这种方法需要注意,new_table中没有了old_table中的primary key,Extra,auto_increment等属性,需要自己手动加,具体参看后面的修改表即字段属性.
只复制表结构到新表
# 第一种方法,和上面类似,只是数据记录为空,即给一个false条件
create table new_table
select * from old_table where 1=2;
# 第二种方法
create table new_table like old_table;
2.新表存在
复制旧表数据到新表(假设两个表结构一样)
insert into new_table
select * from old_table;
复制旧表数据到新表(假设两个表结构不一样)
insert into new_table(field1,field2,.....)
select field1,field2,field3 from old_table;
复制全部数据
select * into new_table from old_table;
只复制表结构到新表
select * into new_talble from old_table where 1=2;