随着自动化测试技术的发展,演化为以下几种模型:线性测试、模块化驱动测试、数据驱动测试和关键字驱动测试。
线性测试
通过录制或编写对应用程序的操作步骤产生相应的线性脚本,每个测试脚本相对独立,且不产生其它的依赖与调用,这也是早期自动化测试的一种形式,它们其实就是单纯地来模拟用户完整的操作场景。
优点:每一个脚本都是完整且独立的。所以,任何一个测试用例脚本都可以拿出来单独执行。
缺点:①开发成本很高,用例之间可能会存在重复的操作。②维护成本很高,也是因为测试用例之间存在着重复的操作。
模块化驱动测试
线性测试模型的缺点是因为其脚本之间可能存在大量的重复操作,因此早期的自动化测试专家借鉴了编程语言中的“模块化”思想,把重复的操作独立成公共模块。
当用例执行过程中需要用到这一模块操作时则被调用,这样就最大程度上消除了重复,从而提高测试用例的可维护性。
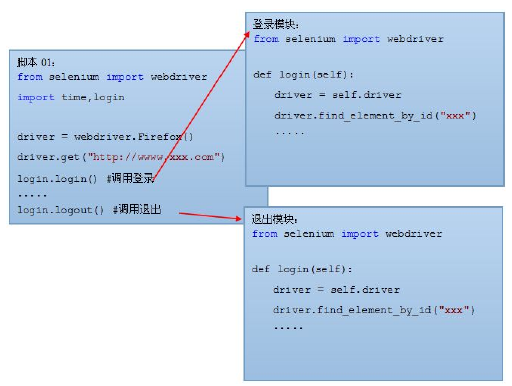
优点:①提高脚本开发效率。②提高脚本可维护性。
缺点:测试数据的不同也可能引发脚本的不可复用性,如:要测试不同用户的登录,虽然登录的步骤相同,但是登录所用的测试数据(用户名&密码)不同,在这种情况下,还是需要重复的编写登录脚本。
数据驱动测试
数据驱动测试的概念就是为了解决模块化驱动测试时因为数据导致的脚本不可复用的问题而被提出。数据驱动说的直白点就是数据的参数化,因为输入数据的不同从而引起输出结果的不同。
不管我们读取的是定义的数组、字典,或者是外部文件(excel. csv. txt. xml等)都可以看作是数据驱动。它的目的就是实现数据与脚本的分离。
多用于接口自动化测试。

关键字驱动测试
目前市面上典型关键字驱动工具以QTP、Robot Framework(RIDE)工具为主。这类工具封装了底层的代码,提供给用户独立的图形界面,以“填表格”的形式降低脚本的编写难度,我们只需要使用工具所提供的关键字以“过程式”的方式来编写用例即可。
Selenium家族中的Selenium IDE也可以看作是一种传统的关键字驱动的自动化工具。
总结
在实际自动化实施的过程中,应以项目需求为出发点,综合运用上述模型来开展自动化测试。
测试脚本
|
模块化驱动测试 |
|
|
登录模块:LoginModular.java |
package com.ModularDriveTest; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; public class LoginModular {
public static void Login(WebDriver driver) //传入webdriver参数 { System.out.println("LoginModular : Login strat ~ "); driver.findElement(By.id("input1")).sendKeys("天使未必在场"); //输入用户名 driver.findElement(By.id("input2")).sendKeys("*****"); //个人密码 driver.findElement(By.id("signin")).click(); //点击“登录” } } // static==静态成员方法,属于类,可直接使用“类名.方法名”来调用; |
|
退出模块:LogoutModular.java |
package com.ModularDriveTest; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver;
public class LogoutModular { public static void Logout(WebDriver driver) throws InterruptedException { System.out.println("LogoutModular : Logout strat ~ "); driver.findElement(By.linkText("退出")).click(); Thread.sleep(2000); //抛异常InterruptedException } } |
|
用户行为:Operation.java 模拟打开博客园“精华”首页; |
package com.ModularDriveTest; import org.openqa.selenium.WebDriver; import org.openqa.selenium.chrome.ChromeDriver;
import com.ModularDriveTest.LoginModular; //导入“登陆”模块 import com.ModularDriveTest.LogoutModular; //导入“退出”模块
public class Operation { public static void main(String[]args) throws InterruptedException{ System.out.println("Start ModularDriveTest ~ ");
WebDriver driver; System.setProperty("webdriver.chrome.driver","D:/selenium-java-3.5.3/chromedriver.exe"); //chromedriver驱动的本地存放路径 driver = new ChromeDriver(); driver.get("https://passport.cnblogs.com/user/signin?ReturnUrl=https%3A%2F%2Fwww.cnblogs.com%2F");
LoginModular.Login(driver); //调用“登陆”模块中的静态成员函数Login;
System.out.println("跳转到"精华"页面"); driver.get("https://www.cnblogs.com/pick/"); Thread.sleep(2000); //抛异常InterruptedException
LogoutModular.Logout(driver);//调用“退出”模块中的静态成员函数Logout;
driver.close(); } } |
|
数据驱动测试 |
|
|
读取.txt文件 |
package com.DataDriven; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.InputStreamReader; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.chrome.ChromeDriver;
public class TxtTest { public static void BaiduSerach(String SearchTerm) throws InterruptedException{ WebDriver driver; System.setProperty("webdriver.chrome.driver","D:/selenium-java-3.5.3/chromedriver.exe"); //chromedriver驱动的本地存放路径 driver = new ChromeDriver(); driver.get("https://www.baidu.com/"); driver.findElement(By.id("kw")).sendKeys(SearchTerm); //通过txt文件获取到的搜索关键字 driver.findElement(By.id("su")).click(); Thread.sleep(2000); driver.close(); } public static void TxtReadAndSerach(String filePath) { try{ String encoding="GBK"; File file=new File(filePath); if(file.isFile() && file.exists()) //判断文件是否存在 { InputStreamReader read=new InputStreamReader(new FileInputStream(file),encoding); //考虑编码格式 BufferedReader bufferedReader=new BufferedReader(read); String SearchTerm = null; while((SearchTerm = bufferedReader.readLine()) != null) //readLine按行读取 { System.out.println(SearchTerm); BaiduSerach(SearchTerm); //只要还有关键字参数,就调用一次BaiduSerach方法 } read .close(); } else { System.out.println("找不到指定的文件"); } } catch(Exception e) { System.out.println("读取文件内容出错"); e.printStackTrace(); } } public static void main(String[]args) throws InterruptedException{ String filePath = "D:\eclipse\workspace\SeleniumTest1\src\com\DataDriven\Txtdata.txt"; //指定测试文件的目录 TxtReadAndSerach(filePath); } } |
|
读取.csv文件 (至少三列的csv文件) |
//CSV包获取://https://sourceforge.net/projects/javacsv/files/JavaCsv/ package com.DataDriven; import java.nio.charset.Charset; import java.util.ArrayList; import com.csvreader.CsvReader;
public class CsvTest { public static void CsvRead(String filePath) { try{ ArrayList<String[]> csvList=new ArrayList<String[]>(); //用来保存数据 CsvReader reader=new CsvReader(filePath,',',Charset.forName("GBK")); //默认是逗号分隔符,UTF-8编码,当CSV文件含有中文时,使用“GBK”编码; reader.readHeaders();//跳过表头如果需要表头的话 while(reader.readRecord()) //readRecord()判断是否还有记录 { csvList.add(reader.getValues()); //getValues()读取当前记录,然后指针下移 } reader.close(); for(int row=0;row<csvList.size();row++) { System.out.println(csvList.get(row)[0]); //第一列 System.out.println(csvList.get(row)[1]); //第二列 System.out.println(csvList.get(row)[2]); //第三列 System.out.println("****************"); } } catch(Exception ex) { System .out.println(ex); } } public static void main(String[]args) throws InterruptedException{ String filePath = "D:\eclipse\workspace\SeleniumTest1\src\com\DataDriven\CsvData.csv"; //指定测试文件的目录 CsvRead(filePath); } } |
|
读取.xml文件 |
//关键步骤 File xmlFile=new File("E:\jase\info.xml"); DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc=builder.parse(xmlFile); //parse()用于打开一个XML文件 NodeList n1=doc.getElementsByTagName(”catalog");//getElementsByTagName用于得到XML文件的一个标签,以数组形式存放 System.out.println(n1.item(0).getTextContent()); //getTextContent()用于获取标签对之间的数据; |
参考:
《Selenium2 Java自动化测试实战(修正版)12_05》