关于统计信息和过滤因子在《DB2数据库查询过程(Query Processing)----概述》一文中已经作了大致介绍。本文再详细讨论一下。
过滤因子(Filter Factor)
过滤因子是一个间接参数,表示满足特定条件的行占表中所有行的比例,,记作FF(P),P表示条件谓词。过滤因子的值可以根据系统编目中的统计信息计算得出,它的主要作用是在存在多种数据访问方式的时候提供选择参考。
考虑下面这张MOBILE表:

现在该表的CITY列上有索引CITY_IDX,MOBILETYPE列上有索引TYPE_IDX。对于SQL查询语句:
Select * From MOBILE Where CITY='武汉' And MOBILETYPE='中国电信 CDMA'
这个查询语句应该使用哪个索引?
由于对于一张表,只能使用一个索引,对一个条件使用索引读入满足条件的数据行后在使用第二个条件进行进一步的筛选。那么查询优化器如何在CITY_IDX和TYPE_IDX这两个索引之间作出取舍呢?
这时候过滤因子就是一个重要的参考参数。
假设MOBILE表总共有100000行,在CITY上一共有100个不同的取值,记作COLCARD(CITY)=100。在MOBILETYPE上一共有10个不同的取值,记作COLCARD(MOBILETYPE)=10.
那么,对于每一个CITY值A,CITY列上值为A的行平均下来大概是100000/100=1000个。即满足CITY='武汉'的行一共有1000个;同理,满足MOBILETYPE='中国电信 CDMA'的行一共有100000/10=10000个。
假设MOBILE表中的所有行都位于不同的数据页上,如果使用CITY_IDX索引,那么需要读入缓冲池的数据页数为1000页,即1000次I/O;而如果使用TYPE_IDX索引,则需要读入缓冲池的数据页数为10000页,即10000次I/O。整整10倍的差距。当然是用CITY_IDX更好了。
也就是说,根据两个条件的CARD值的不同就可以判断出哪种选择更优了,但是使用COLCARD这样一个绝对的量值来作为衡量标准是非常不便的,于是引入过滤因子(Filter Factor)的概念。
过滤因子是满足条件的值在所有值中所占的比例,以上例为例:满足CITY='武汉'的行为1000,表中总的行数为100000.则:
FF(CITY='武汉')=1000/100000=1/100=0.01
同理,FF(MOBILETYPE='中国电信 CDMA')=10000/100000=1/10=0.1
FF(CITY='武汉')
< FF(MOBILETYPE='中国电信 CDMA') ,因此优先使用CITY列上的索引。
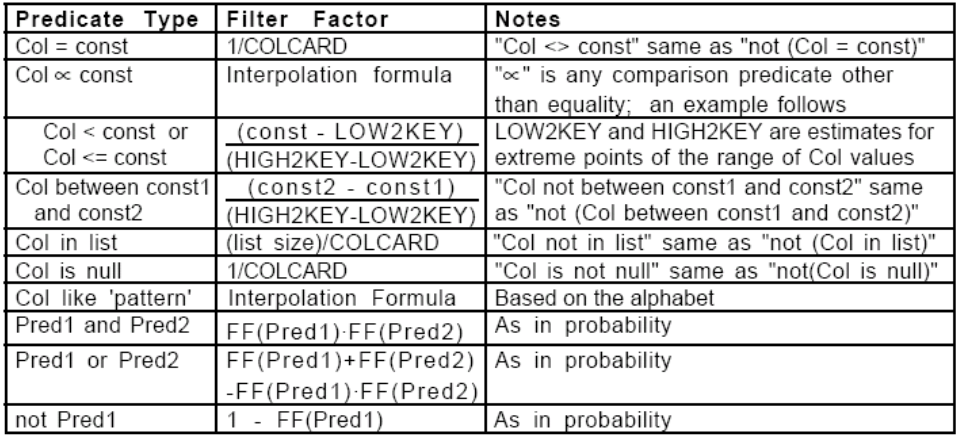
事实上,稍作理解可知,FF(P)=1/COLCARD(col) 式成立 ,col表示谓词P对应的列。
因此,求谓词P的过滤因子只需知道对应列上不同值的个数即可。这个等式也告诉我们:过滤因子并不是一个准确值,而仅仅是一个估计值。根据对应列上不同值的个数估计列上满足某个特定值的行数,然后得出这些行占所有行的比例,而并非真正统计满足特定条件的行的个数再进行计算。
下表是各种谓词对应的过滤因子的估计值算法:
统计信息(Statistics)
统计信息是DB2数据库系统中表空间,缓冲池,表,视图、权限、行,索引,约束、依赖等等对象的方方面面的信息的汇总。是数据库系统监控数据库状态,进行问题诊断和查询优化等等操作的直接凭据。
统计信息以各种表的形式存储在DB2系统编目(System Catalog)中。系统编目由多个系统表构成,是一个元数据存储库。元数据是 关于数据库中数据的信息。元数据与数据本身是分开来维护的。系统编目描述数据的逻辑和物理结构。DB2 UDB 系统编目(或简称为“编目”)由很多表和视图组成,这些表和视图由数据库管理器来维护。
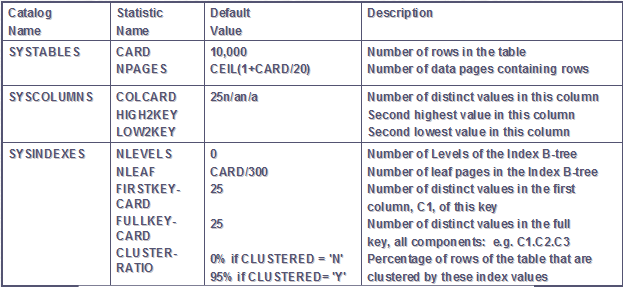
统计信息的内容非常复杂,这里只讨论与查询过程关系非常密切的三个编目表:SYSTABLES、SYSCOLUMNS和SYSINDEXS。
SYSTABLES
SYSTABLES表存储的是数据库中所有表(包括视图)的详细统计信息,关于该表的各列的含义不去介绍,IBM DB2信息中心有详细说明:
这里只关心其中的2列:
CARD:表示表中行的数量;
NPAGES:表示表所占用的数据页的数量。
SYSCOLUMNS
SYSCOLUMNS表存储的是数据库中所有列的详细统计信息,其各列的具体含义还是参考上面的IBM DB2信息中心。
关心其中3列:
COLCARD:表示该列上值不同的行的数量;
HIGH2KEY:表示列值第二高的值。至于为什么不统计最高值而是统计第二高值,因为根据经验,统计第二高值比最高值更有用。
LOW2KEY :表示列值第二低的值。同理。
SYSINDEXS
SYSINDEXS表存储的是数据库中所有索引的详细统计信息,其各列的具体含义还是参考上面的IBM DB2信息中心。
关心其中5列:
NLEVES:表示该B+树索引的层数;
NLEAF:表示该B+树索引的叶结点索引页的数量;
FIRSTKEY-CARD:表示该索引中首搜索码(主搜索码)上不同值的行的个数;
FULLKEY-CRAD:表示该索引中全部搜索码上不同值的行的个数;
CLUSTER-RATIO:表示该索引的聚簇率。
下表上上面三个编目表的部分列的描述:
实例
下面以一个具体的例子来说明上述参数的含义。
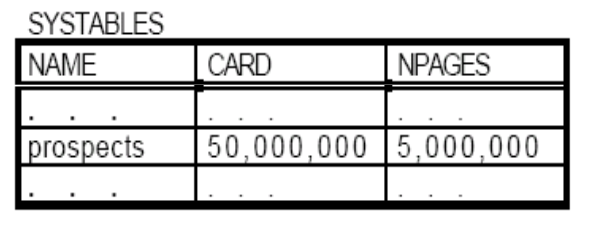
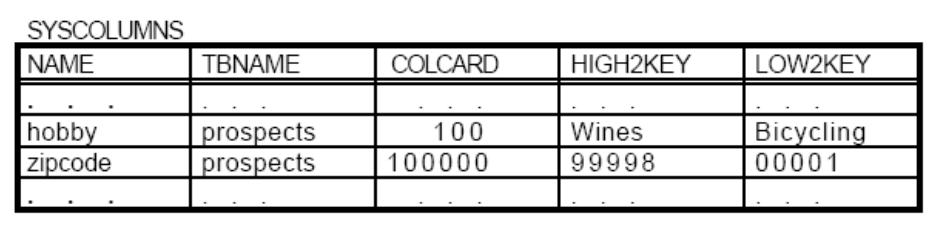
假设有一张表prospects,该表有列id、zipcode、city、straddr、hobby等。表所在表空间的页大小为4KB,且PCTFREE=0(即所有空间均可用于存储),表中共有50000000行数据,每行数据的长度为400B。zipcode列的长度为4B,city列的长度为12B,straddr列的长度为20B,hobby列的长度为8B。其中zipcode列上不同值的行有100000个,hobby列上不同值的行有100个。(zipcode,city,straddr)的组合列上没有重复值,即有50000000个不同值的行。
现在该表上有两个索引:
Create Index addrx On prospects (zipcode,city,straddr) Cluster
即由zipcode,city,straddr列组成的复合索引addrx,addrx还是一个聚簇索引。
Create Index hobbyx On prospects (hobby)
即由hobby列组成的索引hobby。
根据已知的这些条件就可以得出SYSTABLES表和SYSCOLUMNS表的相关参数了(CARD、COLCARD不用说,NPAGES为50000000/(4KB/400B)=5000000),如图:
接下来计算SYSINDEXS表的参数,这个表的一些参数基本上也可以由给定条件直接得出,需要计算的主要是B+树的层数。
先来计算addrx索引B+树的层数
addrx索引的一个索引项的长度为4B的RID+4B的zipcode+12B的city+20B的straddr=40B。
一个索引页可容纳的索引项的个数为4KB/40B=100个。
由于zipcode,city,straddr组成的索引项上没有重复搜索码,因此总共的叶结点页的个数为50000000/100=500000页。
叶结点页的上层非叶结点页的个数为500000/100=5000页。
该非叶结点页的上层非叶结点页的个数为5000/100=50页。
50 < 100,所以再上层是根结点页。
因此,addrx索引的B+树一共有4层。
再来计算hobbyx索引B+树的层数
因为hobby上有重复行,所以要考虑索引压缩,利用逻辑块进行分析。(关于DB2索引逻辑块结构可以参看:《深入理解DB2索引(Index)》)
由于一个逻辑块最多可以包含255个RID,一个RID大小为4B,因此一个逻辑块大小为2B(逻辑块前缀的大小)+8B(CITY列的长度)+255*4B=1030B,为方便计算,以1000B计;
那么一个4KB页能容纳的逻辑块个数为4KB/1000B=4个。由于一个逻辑块中RID的个数为255个,因此一个4KB索引页中容纳了约1000个RID;
对于无重复搜索码值的索引而言,一个搜索码对应一个RID,即一个索引项对应一个RID,一个RID又对应一个数据行。那么,对于有重复搜索码值的情况,同样是一个RID对应了一个数据行,如果我们还是认为一个索引项由一个搜索码和一个RID构成的话,那么可以说:一个索引页中包含1000个索引项(因为一个索引页中有1000个RID呀,只是搜索码被压缩了,若干个RID共用了一个搜索码而已);
一个叶结点索引页包含1000个索引项,那么对于50000000行数据,所需要的叶结点页的个数为50000000/1000=50000页;
由于非叶结点页没有使用压缩技术,索引项结构依然是搜索码长度+RID长度。则一个非叶结点页能容纳的索引项个数为4KB/(4B+8B)=333个,那么50000个叶结点页需要的上层非叶结点页个数最多为50000/333=151页;
151<333,故该非叶结点层的上层为根结点;
因此,hobbyx索引B+树一共有3层。
addrx索引和hobbyx索引层数对比如下图:

至此,SYSINDEX表的相关参数也全部求出:

分布统计信息(Distribution Statistics)
以上所讨论的都是基本统计信息的知识,事实上,由于数据行的重复值与分布不均匀等原因,有时候使用基本统计信息得到的访问计划并不是最优的。
举个简单的例子:一个表T中有10000行数据,其中有9990在列C1上的值满足C1>5000。C1上建有索引。对应查询语句”Select * From C1>5000“,是否应该使用C1的索引呢?
即便使用了索引,最后也仍然需要将满足条件的9990行数据读入缓冲池,而且还需要负担读入索引页以及减少索引的开销。而不使用索引,也只需要读入10000行数据而已。因此很有可能单单使用表扫描效率更高。
对于上述的情况,仅靠基本统计信息得到的当然是使用索引的访问计划,但这显然不是最优的方案。这时候收集分布统计信息就尤为必要了,它能帮助优化器作出更为准确的决策。
分布统计信息分为频率(frequency)分布统计信息和分位数(quantile)分布统计信息,前者是为了处理重复值问题的,后者是为了处理分布不均问题的(上面的例子就是一个分布不均的例子。)。
对于分布统计信息,IBM官方文档库的资料介绍得非常详细,详细内容可参考:《在 DB2 优化器中使用分布统计信息》