深入理解TCP协议及其源代码
前言
在前面实验我们分别实现了Socket 通信工具,探讨了Socket API、Socket 调用原理等。但是还没有针对某一实例进行讲解,在本实验我们将针对TCP协议进行详细分析,期待在Linux内核进行分析TCP原理。
1.Tcp基本原理
TCP是一种面向连接、可靠、基于字节流的传输协议,位于TCP/IP模型的传输层。
- 面向连接:不同于UDP,TCP协议需要通信双方确定彼此已经建立连接后才可以进行数据传输;
- 可靠:连接建立的双方在进行通信时,TCP保证了不会存在数据丢失,或是数据丢失后存在拯救丢失的措施;
- 字节流:实际传输中,不论是何种数据,TCP都按照字节的方式传输,而非以数据包为单位。
针对它的这三种特性,本小节我们将对其原理进行探究。
1.1面向连接(三次握手)
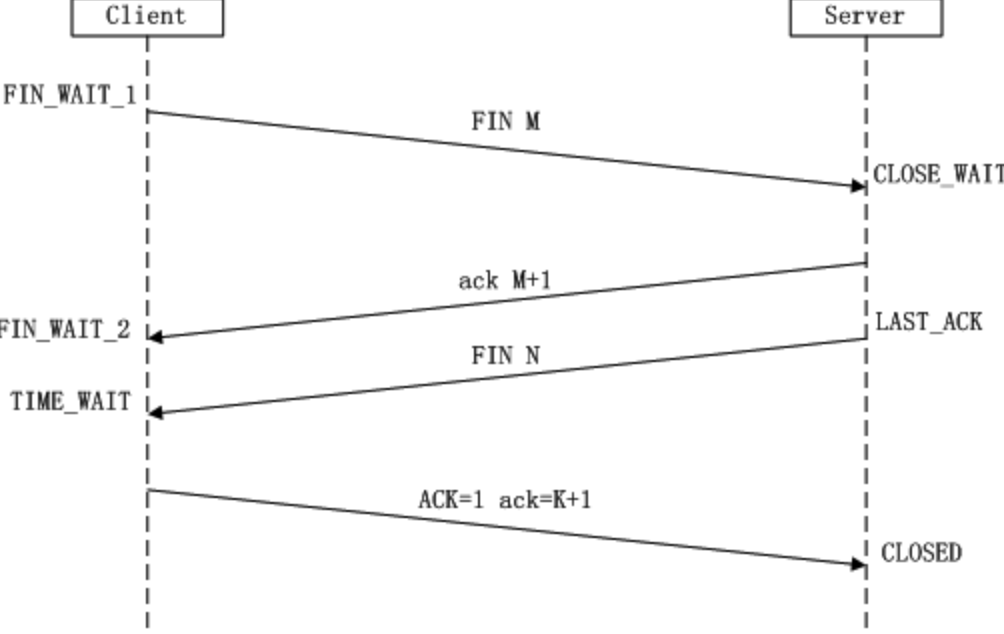
1.2可靠(简单描述)
- 检验和:TCP检验和的计算与UDP一样,在计算时要加上12byte的伪首部,检验范围包括TCP首部及数据部分,但是UDP的检验和字段为可选的,而TCP中是必须有的。计算方法为:在发送方将整个报文段分为多个16位的段,然后将所有段进行反码相加,将结果存放在检验和字段中,接收方用相同的方法进行计算,如最终结果为检验字段所有位是全1则正确(UDP中为0是正确),否则存在错误。
- 序列号:TCP将每个字节的数据都进行了编号,这就是序列号。
序列号的作用:
a、保证可靠性(当接收到的数据总少了某个序号的数据时,能马上知道)
b、保证数据的按序到达
c、提高效率,可实现多次发送,一次确认
d、去除重复数据
数据传输过程中的确认应答处理、重发控制以及重复控制等功能都可以通过序列号来实现。 - 确认应答机制(ACK):TCP通过确认应答机制实现可靠的数据传输。在TCP的首部中有一个标志位——ACK,此标志位表示确认号是否有效。接收方对于按序到达的数据会进行确认,当标志位ACK=1时确认首部的确认字段有效。进行确认时,确认字段值表示这个值之前的数据都已经按序到达了。而发送方如果收到了已发送的数据的确认报文,则继续传输下一部分数据;而如果等待了一定时间还没有收到确认报文就会启动重传机制。
- 超时重传机制:当报文发出后在一定的时间内未收到接收方的确认,发送方就会进行重传(通常是在发出报文段后设定一个闹钟,到点了还没有收到应答则进行重传)
- 流量控制:接收端处理数据的速度是有限的,如果发送方发送数据的速度过快,导致接收端的缓冲区满,而发送方继续发送,就会造成丢包,继而引起丢包重传等一系列连锁反应。因此TCP支持根据接收端的处理能力,来决定发送端的发送速度,这个机制叫做流量控制。
在TCP报文段首部中有一个16位窗口长度,当接收端接收到发送方的数据后,在应答报文ACK中就将自身缓冲区的剩余大小,放入16窗口大小中。这个大小随数据传输情况而变,窗口越大,网络吞吐量越高,而一旦接收方发现自身的缓冲区快满了,就将窗口设置为更小的值通知发送方。如果缓冲区满,就将窗口置为0,发送方收到后就不再发送数据,但是需要定期发送一个窗口探测数据段,使接收端把窗口大小告诉发送端。 - 拥塞控制:流量控制解决了 两台主机之间因传送速率而可能引起的丢包问题,在一方面保证了TCP数据传送的可靠性。然而如果网络非常拥堵,此时再发送数据就会加重网络负担,那么发送的数据段很可能超过了最大生存时间也没有到达接收方,就会产生丢包问题。
为此TCP引入慢启动机制,先发出少量数据,就像探路一样,先摸清当前的网络拥堵状态后,再决定按照多大的速度传送数据。
此处引入一个拥塞窗口:
发送开始时定义拥塞窗口大小为1;每次收到一个ACK应答,拥塞窗口加1;而在每次发送数据时,发送窗口取拥塞窗口与接送段接收窗口最小者。
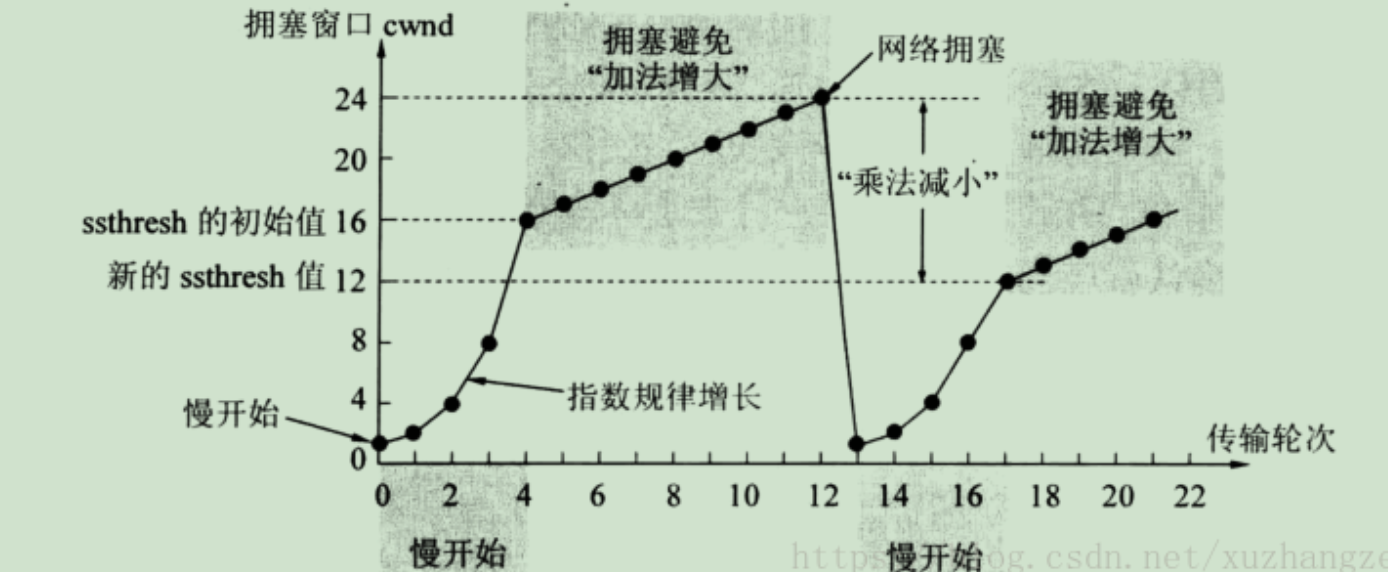
慢启动:在启动初期以指数增长方式增长;设置一个慢启动的阈值,当以指数增长达到阈值时就停止指数增长,按照线性增长方式增加;线性增长达到网络拥塞时立即“乘法减小”,拥塞窗口置回1,进行新一轮的“慢启动”,同时新一轮的阈值变为原来的一半。
“慢启动”机制可用图表示:
2.基本原理探究
在上次实验,我们通过追踪qemu底层的sys_call入口观察系统态和内核态之间的联系,理清了系统层面是怎样对底层接口进行调用的。在本小节,详细分析一下TCP协议在内核中的基本原理。
TCP协议的初始化及socket创建TCP套接字描述符

sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = move_addr_to_kernel(uservaddr, addrlen, &address);
if (err < 0)
goto out_put;
err =
security_socket_connect(sock, (struct sockaddr *)&address, addrlen);
if (err)
goto out_put;
err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen,
sock->file->f_flags);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
分析代码能够发现,在内核socket接口层这两个socket API函数对应着sys_connect和sys_accept函数,进一步对应着sock->opt->connect和sock->opt->accept两个函数指针。
进一步寻找TCP协议接口层函数定义,打开文件net/ipv4/tcp_ipv4.c,其中设定了TCP协议栈的访问接口函数,结果如下:
```c
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
.hash = inet_hash,
.unhash = inet_unhash,
.get_port = inet_csk_get_port,
.enter_memory_pressure = tcp_enter_memory_pressure,
.leave_memory_pressure = tcp_leave_memory_pressure,
.stream_memory_free = tcp_stream_memory_free,
.sockets_allocated = &tcp_sockets_allocated,
.orphan_count = &tcp_orphan_count,
.memory_allocated = &tcp_memory_allocated,
.memory_pressure = &tcp_memory_pressure,
.sysctl_mem = sysctl_tcp_mem,
.sysctl_wmem_offset = offsetof(struct net, ipv4.sysctl_tcp_wmem),
.sysctl_rmem_offset = offsetof(struct net, ipv4.sysctl_tcp_rmem),
.max_header = MAX_TCP_HEADER,
.obj_size = sizeof(struct tcp_sock),
.slab_flags = SLAB_TYPESAFE_BY_RCU,
.twsk_prot = &tcp_timewait_sock_ops,
.rsk_prot = &tcp_request_sock_ops,
.h.hashinfo = &tcp_hashinfo,
.no_autobind = true,
#ifdef CONFIG_COMPAT
.compat_setsockopt = compat_tcp_setsockopt,
.compat_getsockopt = compat_tcp_getsockopt,
#endif
.diag_destroy = tcp_abort,
};
不难发现在TCP协议中这两个函数指针对应着tcp_v4_connect函数和inet_csk_accept函数。分析到这里,应该能够想到我们可以通过MenuOS的内核调试环境设置断点跟踪tcp_v4_connect函数和inet_csk_accept函数来进一步验证三次握手的过程。
接下来针对tcp_v4_connect函数和inet_csk_accept函数进行进一步分析。
2.1tcp_v4_connect函数
继续在net/ipv4/tcp_ipv4.c文件中找到connect函数定义如下:
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *usin = (struct sockaddr_in *)uaddr;
struct inet_sock *inet = inet_sk(sk);
struct tcp_sock *tp = tcp_sk(sk);
__be16 orig_sport, orig_dport;
__be32 daddr, nexthop;
struct flowi4 *fl4;
struct rtable *rt;
int err;
struct ip_options_rcu *inet_opt;
struct inet_timewait_death_row *tcp_death_row = &sock_net(sk)-ipv4.tcp_death_row;
if (addr_len < sizeof(struct sockaddr_in))
return -EINVAL;
if (usin->sin_family != AF_INET)
return -EAFNOSUPPORT;
nexthop = daddr = usin->sin_addr.s_addr;
inet_opt = rcu_dereference_protected(inet->inet_opt,
lockdep_sock_is_held(sk));
if (inet_opt && inet_opt->opt.srr) {
if (!daddr)
return -EINVAL;
nexthop = inet_opt->opt.faddr;
}
orig_sport = inet->inet_sport;
orig_dport = usin->sin_port;
fl4 = &inet->cork.fl.u.ip4;
rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
IPPROTO_TCP,
orig_sport, orig_dport, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
if (err == -ENETUNREACH)
IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES);
return err;
}
if (rt->rt_flags & (RTCF_MULTICAST | RTCF_BROADCAST)) {
ip_rt_put(rt);
return -ENETUNREACH;
}
if (!inet_opt || !inet_opt->opt.srr)
daddr = fl4->daddr;
if (!inet->inet_saddr)
inet->inet_saddr = fl4->saddr;
sk_rcv_saddr_set(sk, inet->inet_saddr);
if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) {
/* Reset inherited state */
tp->rx_opt.ts_recent = 0;
tp->rx_opt.ts_recent_stamp = 0;
if (likely(!tp->repair))
tp->write_seq = 0;
}
inet->inet_dport = usin->sin_port;
sk_daddr_set(sk, daddr);
inet_csk(sk)->icsk_ext_hdr_len = 0;
if (inet_opt)
inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen;
tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT;
/* Socket identity is still unknown (sport may be zero).
* However we set state to SYN-SENT and not releasing socket
* lock select source port, enter ourselves into the hash tables and
* complete initialization after this.
*/
tcp_set_state(sk, TCP_SYN_SENT);
err = inet_hash_connect(tcp_death_row, sk);
if (err)
goto failure;
sk_set_txhash(sk);
rt = ip_route_newports(fl4, rt, orig_sport, orig_dport,
inet->inet_sport, inet->inet_dport, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
rt = NULL;
goto failure;
}
/* OK, now commit destination to socket. */
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
rt = NULL;
if (likely(!tp->repair)) {
if (!tp->write_seq)
tp->write_seq = secure_tcp_seq(inet->inet_saddr,
inet->inet_daddr,
inet->inet_sport,
usin->sin_port);
tp->tsoffset = secure_tcp_ts_off(sock_net(sk),
inet->inet_saddr,
inet->inet_daddr);
}
inet->inet_id = tp->write_seq ^ jiffies;
if (tcp_fastopen_defer_connect(sk, &err))
return err;
if (err)
goto failure;
err = tcp_connect(sk);
if (err)
goto failure;
return 0;
}
分析源码不难发现 tcp_v4_connect函数的主要作用就是发起一个TCP连接,建立TCP连接的过程自然需要底层协议的支持,因此我们从这个函数中可以看到它调用了IP层提供的一些服务,比如ip_route_connect和ip_route_newports从名称就可以简单分辨,这里我们关注在TCP层面的三次握手,不去深究底层协议提供的功能细节。我们可以看到这里设置了TCP_SYN_SENT并进一步调用了 tcp_connect(sk)来实际构造SYN并发送出去。
在tcp_connect函数具体负责构造一个携带SYN标志位的TCP头并发送出去,同时还设置了计时器超时重发。
其中tcp_transmit_skb函数负责将tcp数据发送出去,这里调用了icsk->icsk_af_ops->queue_xmit函数指针,实际上就是在TCP/IP协议栈初始化时设定好的IP层向上提供数据发送接口ip_queue_xmit函数,这里TCP协议栈通过调用这个icsk->icsk_af_ops->queue_xmit函数指针来触发IP协议栈代码发送数据。
2.2inet_csk_accept函数
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
struct request_sock *req;
struct sock *newsk;
int error;
lock_sock(sk);
/* We need to make sure that this socket is listening,
* and that it has something pending.
*/
error = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
goto out_err;
/* Find already established connection */
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
/* If this is a non blocking socket don't sleep */
error = -EAGAIN;
if (!timeo)
goto out_err;
error = inet_csk_wait_for_connect(sk, timeo);
if (error)
goto out_err;
}
req = reqsk_queue_remove(queue, sk);
newsk = req->sk;
if (sk->sk_protocol == IPPROTO_TCP &&
tcp_rsk(req)->tfo_listener) {
spin_lock_bh(&queue->fastopenq.lock);
if (tcp_rsk(req)->tfo_listener) {
/* We are still waiting for the final ACK from 3WHS
* so can't free req now. Instead, we set req->sk to
* NULL to signify that the child socket is taken
* so reqsk_fastopen_remove() will free the req
* when 3WHS finishes (or is aborted).
*/
req->sk = NULL;
req = NULL;
}
不难发现服务端调用inet_csk_accept函数会从请求队列中取出一个连接请求,如果队列为空则通过inet_csk_wait_for_connect函数处理,其代码如下:
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
struct inet_connection_sock *icsk = inet_csk(sk);
DEFINE_WAIT(wait);
int err;
for (;;) {
prepare_to_wait_exclusive(sk_sleep(sk), &wait,
TASK_INTERRUPTIBLE);
release_sock(sk);
if (reqsk_queue_empty(&icsk->icsk_accept_queue))
timeo = schedule_timeout(timeo);
sched_annotate_sleep();
lock_sock(sk);
err = 0;
if (!reqsk_queue_empty(&icsk->icsk_accept_queue))
break;
err = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
break;
err = sock_intr_errno(timeo);
if (signal_pending(current))
break;
err = -EAGAIN;
if (!timeo)
break;
}
finish_wait(sk_sleep(sk), &wait);
return err;
}
可以看到,inet_csk_wait_for_connect函数是一个for死循环,它循环等待连接到来,只有队列中有连接请求才会跳出循环。
三次握手过程总结:可以将整个过程描述为,client端不断初始化资源,调用到connect函数进行连接请求,当server端收到连接请求后进行处理,利用accept函数进行连接建立。
进一步的,client端的connect的请求会被server端放入请求队列,当有请求到来inet_csk_wait_for_connect函数对请求出队,进行三次握手的建立过程。按如上思路跟踪调试代码的话,会发现connect之后将连接请求发送出去,accept等待连接请求,connect启动到返回和accept返回之间就是所谓三次握手的时间。
三次握手详细过程
引用这里5