当你必须自己实现一个解析器时,你对它的期望会有很多,包括性能良好、灵活、特性丰富、方便使用,以及便于维护等等。说到底,这也是你自己的代码。在本文中,我将为你介绍在Java中实现高性能解析器的一种方式,这种方法并且独一无二,但难度适中,不仅实现了高性能,而且它的模块化设计方式也比较合理。这种设计是受到了VTD-XML的设计方式的启发,后者是我所见过的最快的Java XML解析器,比起StAX和SAX这两种标准的Java XML解析器都要快上许多。
两种基本的解析器类型
为解析器进行分类的方式有好几种,在这里我将解析器分为两种基础类型:
- 顺序访问解析器
- 随机访问解析器
顺序访问是指解析器对进行数据进行解析,在数据解析完成后将其转交给数据处理器(processor)的过程。数据处理器只能访问当前正在进行解析的数据,它既不能访问已解析过的数据,也不能访问等待解析的数据。这种解析器也被称为基于事件的解析器,例如SAX和StAX解析器。
而随机访问解析器是指解析器允许数据处理代码可以随意访问正在进行解析的数据之前和之后的任意数据(随机访问)。这种解析器的例子有XML DOM解析器。
下图展示了顺序访问解析器与随机访问解析器的不同之处:
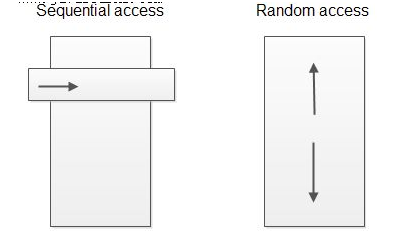
顺序访问解析器只能让你访问当前正在解析的“视窗”或“事件”,而随机访问解析器允许你任意地浏览所有已解析数据。
设计概况
我在这里所介绍的解析器设计属于随机访问解析器。
随机访问解析器的实现通常会慢于顺序访问解析器,因为它们一般都会为已解析数据创建某种对象树,数据处理代码将通过这棵树对数据进行访问。创建这种对象树不仅要花费较长的CPU时间,消耗的内存也很大。
相对于从已解析数据中创建一棵对象树的方式,另一种性能更佳的方式是为原来的数据缓冲区建立一个对应的索引缓冲区,这些索引会指向在已解析数据中找到的元素的起点与终点。数据处理代码此时不再通过对象树访问数据,而是直接在包括了原始数据的缓冲区中访问已解析数据。以下是对这两种处理方式的图示:
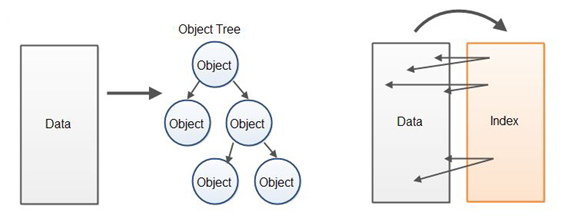
由于我找不到一个更好的名字,因此我将这种方式简单地命名为“索引覆盖解析器”(Index Overlay Parser)。该解析器为原始数据创建了一个覆盖于其上的索引。这种方式让人联想起数据库索引将数据保存在磁盘的方式,它为原始的、未处理的数据创建了一个索引,以实现更快地浏览和搜索数据的目的。
如同我之前所说的,这种设计方式是受到了VTD-XML(VTD是指虚拟令牌描述符)的启发,因此你也可以把这种解析器称为虚拟令牌描述符解析器。但我还是倾向于索引覆盖这个名字,因为它表现了虚拟令牌描述符的本质,即对原始数据建立的索引。
解析器设计概要
一种常规的解析器设计方式将解析过程分为两步。第一步是将数据分解为内聚的令牌,一个令牌是已解析数据中的一个或多个字节或字符。第二步是对令牌进行解释,并根据这些令牌构建更大的元素。以下是这两个步骤的图示:
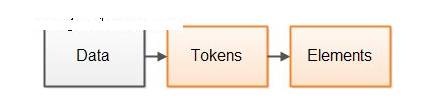
这里的元素并不一定是指XML元素(虽然XML元素也是解析器元素),而是指构成解析数据的更大的“数据元素”。比如说,在一个XML文档中元素代表了XML元素,而在一个JSON文档中元素则代表了JSON对象,等等。
举例来说,<myelement>这个字符串可以被分解为以下几个令牌:
- <
- myelement
- >
一旦数据被分解为令牌,解析器就能够相对容易地了解它的意义,并且决定这些令牌构成的更大的元素。解析器就能够理解一个XML元素是由一个’<’令牌开始,随后是一个字符串(即元素名称),随后有可能是一些属性,最后以一个’>’令牌结尾。
索引覆盖解析器设计
在这种解析器的设计方式中也包含了两个步骤:输入数据首先被一个令牌生成器(tokenizer)组件分解为令牌,解析器随后将对令牌进行解析,以决定输入数据的一个更大的元素边界。
你也可以为解析过程加入一个可选的“元素浏览步骤”。如果解析器从解析数据中构建出一棵对象树,它通常会包含在整棵树中进行浏览的链接。如果我们不选择对象树,而是构建出一个元素索引缓冲区,我们也许需要另一个组件以帮助数据处理代码在元素索引缓冲区中进行浏览。
以下是我们的解析器设计的概要:
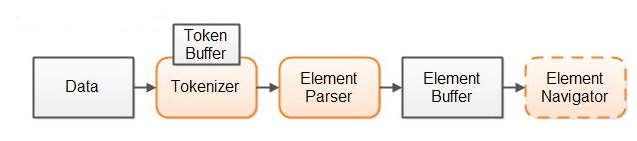
我们首先将所有数据读入一个数据缓冲区中,为了能够通过在解析过程中创建的索引对原始数据进行随机访问,所有的原始数据必须已经存在于内存中。
第二步,令牌生成器会将数据分解为令牌。令牌生成器内部的某个令牌缓冲区会将该令牌的起点索引、终点索引和令牌类型都保留下来。使用令牌缓冲区使你能够查找之前或之后的令牌,在这种设计中解析器会利用到这一项特性。
第三步,解析器获取了令牌生成器所产生的令牌,根据上下文对其进行验证,并决定它所表示的元素。随后解析器会根据从令牌生成器处获取的令牌构建一个元素索引(即索引覆盖)。解析器会从令牌生成器中一个接一个地获取令牌。因此令牌生成器不必立即将所有数据都分解为令牌,它只需要每次找到一个令牌就行了。
数据处理代码将浏览整个元素缓冲区,利用它访问原始数据。你也可以选择用一个元素浏览组件将元素缓冲区包装起来,使浏览元素缓冲区的工作更加简单。
这种设计不会从解析数据中生成一棵对象树,但它确实生成了一个可浏览的结构,即元素缓冲区,索引(即整数数组)将指向包含了原始数据的数据缓冲区。你可以使用这些索引浏览原始数据缓冲区中的所有数据。
【Java开发学习交流群02】 群号215703787