简介
本文主要介绍操作系统中进程管理的逻辑,主要包含了典型的进程调度算法,进程和线程的关系,进程之间互斥和同步算法几块。
该博客所有文章:http://www.cnblogs.com/xuanku/p/index.html
基础知识
进程调度和管理是操作系统知识中非常重要的一环。
每个进程都有如下三个状态:
- 就绪
- 运行
- 阻塞
一般来说,一个进程一开始处于就绪状态,等待CPU选择他运行了之后,就进入了运行状态,当进程出现IO操作之后,就进入阻塞状态。也有可能是时间片用光了,从运行状态进入就绪状态等待CPU调度。
普通调度算法
FCFS
First Come First Service。FIFO方式的调度策略,先来后到的服务方式。
这种方式的优势是实现简单,也是最容易想到的调度方案。但是有两个重大问题:
-
对短进程的运行不利
短进程必须等到前面长进程执行完毕了之后才能运行,可能会等待较长时间。
-
对IO密集型运行不利
IO密集型比短进程还惨。还不容易排队等到他运行了,结果没运行一会儿就因为IO阻塞去了,等IO操作完毕了之后,还得重新排队。
所以这个算法对IO密集型的进程运行效率是极其低下的。
RR
Round Robin。轮询调度算法为每个进程分配固定的时间片,时间片用完了就必须重新到队尾去排队。
这样的设计解决了FCFS的第一个问题,相对而言也部分解决了第2个问题。
但是对IO密集型进程依然解决得不太好,有一个优化的方案就是设计两个队列,将因为IO阻塞的进程单独放一个队列,在选择下一个运行进行的时候对这个队列的进程提权。
FCFS还有另外一个比较复杂的问题就是如何选择时间片。时间片过长就退化成FCFS算法了,过短又会造成切换开销太大。
Prediction
基于预测的算法。这类预测算法都是假设我们知道每个进程总共所需要的时间,以及IO占比信息。
假设我们能收集到这些信息,可以有如下几种调度算法:
- 最短运行时间优先
- 最短剩余时间优先
- 综合已经运行时间和剩余时间来排序
但是在真实世界中,一般这个信息是无法预测的。即使是同一个进程,之前运行的情况对当前运行的进程也不一定有参考价值。比如cat程序,不同参数对运行时间影响很大。
Feedback
这个是基于Prediction来优化的。如果说Prediction是需要预测将来进程还需要多少资源的话,Feedback算法就是基于已经消耗了的资源来判断优先级。
一般来说,也就是运行时间越长,优先级越低的调度算法。
Unix调度算法
老版调度算法
这是2.6版本之前的调度算法,该算法采用优化的RR算法,每个进程的优先级算法如下:
p(i) = base(i)+nice(i)+cpu(i)
其中base和nice值都是静态固定的,可以由用户指定的。
cpu是随着进程占用CPU时间越长权重就越低的调整因子,该因子调整逻辑如下:
cpu(i) = cpu(i-1)/2
也就是每次进程被选中调度一遍之后,下次对应的cpu因子的值都会被除以2,降低下次运行的权重。
新版调度算法
内核2.6版本之后重写了调度算法。也叫O(1)算法。
该算法针对普通进程,设置了100~139共40个优先级,进程属于哪个优先级的计算跟老版调度算法类似。系统再存储了一个位图,每个位图代表一个优先级是否有等待的进程。然后每次都选择优先级最高的且有进程的那个队列选取第一个进程来运行。
SMP的调度
对于多处理器的处理,跟上面的调度算法类似,只是在选择出进程之后,需要再判断一下给哪个CPU合适。
一般来说,考虑到CPU的本地cache,所以尽量将进程调度到之前运行的CPU上运行。当然,考虑到CPU本身的均衡性,所以肯定还是会有迁移的工作。
线程相关
用户线程&内核线程
线程从一开始诞生就有两个分类:用户级线程 和 内核级线程。
我们在Linux上常见的是内核级线程, 即线程调度相关操作都在内核里实现, 不太常见的是用户级线程。
用户级线程的优势是:
- 线程切换成本低,不用内核操作
- 用户可以自定义线程调度策略
- 跟操作系统无关,可以很快移植到另外一台机器上
但是用户线程也有如下问题:
- 一个线程的阻塞会影响其他线程,因为操作系统看不到别的线程
- 不能很好的利用多核能力,因为操作系统会把一个内核进程放到一个CPU上
目前Linux上只使用内核级线程, Solaris上面两者都提供。
线程切换
一个进程的上下文主要有如下几个部分的信息构成:
- 程序计数器
- 寄存器信息
- 栈信息
一个进程切换的过程包含:
- 保存当前进程的上下文
- 将当前进程加入操作系统对应队列
- 通过调度算法选择另外一个进程
- 调整虚存映射
- 加载新进程的上下文
但是线程切换就不一样了,之需要切换PC寄存器指向的代码地址就好,其他操作都不用做,所以线程切换的成本比进程切换低多了。
互斥和同步
简介
当多个进程需要对同一个资源进行访问的时候, 为了避免同时使用这个资源造成的混乱, 所以需要考虑进程间的互斥。
典型的互斥实现方案如下:
| 方案 | 介绍 |
|---|---|
| 中断禁用 | 杀敌一千, 自损八百。虽然能实现互斥, 但是大大降低了处理器的执行效率。而且再多处理器体系结构中, 他还不能达到互斥 |
| 专用机器指令 | 往往是通过一个不可中断的指令, 用于原子修改内存中的值, 常见的两个指令是testset和exchange, 其对应的demo代码如下图。该方案的好处是实现简单, 坏处是使用了忙等待, 可能出现饥饿, 可能死锁, 需要操作系统层进行管理和避免 |
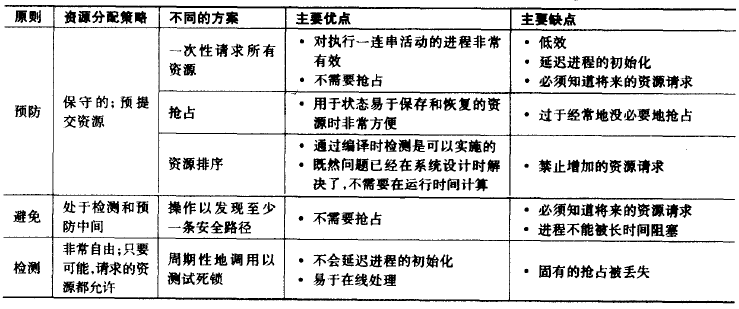
死锁的避免
死锁出现有4个必要条件:
- 互斥: 资源只能同时被一个进程使用
- 占有且等待: 一个进程在等待别的资源的时候, 将继续占有其拥有的资源
- 非抢占: 不能强行抢占别人占有的资源
- 循环等待: 在满足如上3个条件的情况下, 出现循环等待即出现死锁
要避免死锁也是从这4个条件上下手:
- 互斥: 这个是为了资源功能正常运转, 无法避免
- 占有且等待: 让进程一开始就申请所有资源才能运行。问题是效率低下, 进程可能要等待很长时间, 资源可能被控制很长时间, 程序也需要最开始就知道需要使用哪些资源;
- 非抢占: 根据进程优先级让申请资源的进程释放自己之前拥有的资源或者抢占别的进程的资源, 靠谱, 唯一的问题在于资源的使用不一定有那么容易的保存和恢复(很多硬件不像处理器那样可以随意切换使用进程的)
- 循环等待: 给资源定义一个序列, 进程只能按照序列申请资源, 会导致进程执行效率大大降低, 所以主流做法是如下两种
如上几种避免办法都有各种各样的问题, 所以一般不采用, 现在采用最多的方案还是从第4点出发, 只不过不预先避免, 而是动态探测:
-
如果一个进程启动或者新增资源需求会导致死锁, 则不允许此分配
典型的算法如
银行家算法, 此方法的弊端是需要知道一个进程将来所需要占用的资源 -
允许所有请求, 周期性的进行检测死锁
动态检测, 运行效率高, 但是如果出现死锁频率比较高, 则系统运行效率会比较低。
综合所有的死锁避免的方法的对比如下:
编程界面
多进程之间的互斥与同步方案有了如上提到的系列硬件支持之后, 就需要考虑操作系统对有并发编程的程序员们提供的编程界面了。
信号量
信号量是在内存中维护了一个int, 每次操作对该int进行++或者--。
对操作者提供了两个接口:
-
semWait
该接口检查int值, 如果该值大于0, 就将该值--, 并进入临界区; 否则就阻塞检测该值知道大于0;
-
semSignal
该接口将int值++, 并通知受阻的所有进程。通知哪个进程有的采用FIFO策略, 有的采用随机策略。
管程
信号量的方式比较灵活, 让程序员可以任意控制临界区以及交互设计, 大部分现在程序也都采用了类似的方案, 这是一个相对底层但是功能强大的方案。
但是有人提出了信号量的操作分散, 在模块中任何位置都可能出现, 造成程序编写和维护困难, 也容易出bug, 所以在70年代, 有人提出了管程的概念, 笔者在实际工作中尚未使用管程来实现进程间互斥和同步。
管程底层跟信号量类似, 只是他把所有加锁解锁的逻辑全部封装在一个类里面, 所有关于该临界资源的操作都在这个类中以函数的方式呈现, 除了这个类之外其他任何地方都看不到锁。这样就实现了锁相关逻辑集中在一个地方。
在一个类里面可以有多把锁, 跟信号量类似, 针对每把锁, 在该类的函数里可以用类似semWait和semSignal的接口等待该锁或者释放该锁。
消息传递
消息传递的方式跟锁又有些不一样了, 因为进程间同步互斥不外乎就是阻塞和交换信息两类, 而消息传递提供的API就是最底层的API, 把其他逻辑都交给了上层由程序员控制。
其提供的API如下:
-
send(destination, message)
发送请求
-
receive(source, message)
接收请求
根据两个接口是否阻塞, 一般又分成如下几类:
-
send和receive都阻塞
一般用于进程间紧密同步的时候使用
-
send不阻塞, receive阻塞
比较常见的方式, send之后可以继续做别的事情, 但是receive这头在收到相关信息之前, 必须阻塞直到相关信息确认才能继续。
-
send和receive都不阻塞
比较少见。
一般现在在分布式系统涉及到跨机器写作的时候, 会使用该方式来做进程间的同步和互斥。
参考
- 操作系统精髓与设计原理. http://book.douban.com/subject/5064311/