1. 守护线程
设置子线程为守护线程,则守护线程的代码会等待主线程代码执行完毕而结束:
# 如果打印两个 子线程执行结束,肯定是先打印的守护线程的,然后才是子线程2的,因为如果子线程2先打印出来,那么主线程代码就结束了,守护线程也就立马结束,不会在进行打印; # 如果只打印一个 “子线程执行结束” 打印的就是子线程2的,主线程代码执行完毕,守护线程也结束,来不及打印 from threading import Thread import time def func(): print("子线程1开始执行") time.sleep(2) print("子线程1执行完毕") t1=Thread(target=func) # 创建一个子线程 t1.setDaemon(True) #设置t1子线程为守护线程,等待主线程代码执行完毕,子线程就结束了 t1.start() # 子线程启动 t2=Thread(target=func) t2.start() t2.join() # 主线程等待子线程2执行完毕,主线程代码才算执行完,此时守护线程1也会随着结束
运行结果: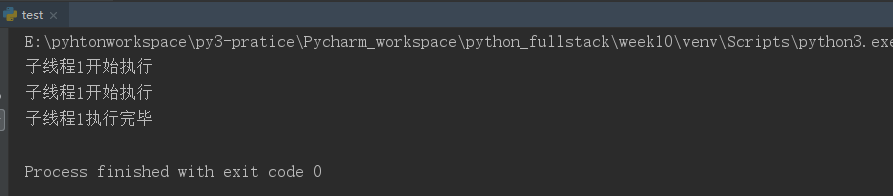
再来看一个例子:
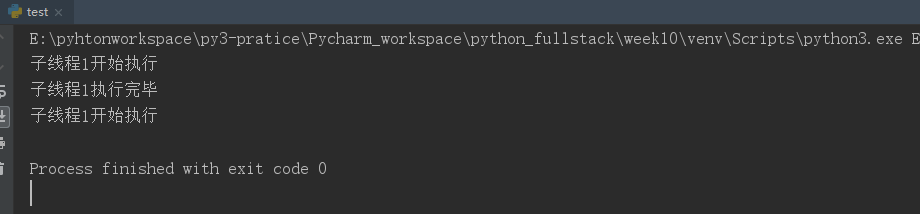
from threading import Thread import time def func(): while True: print("子线程1开始执行") time.sleep(2) print("子线程1执行完毕") t1=Thread(target=func) # 创建一个子线程 t1.setDaemon(True) #设置t1子线程为守护线程,等待主线程代码执行完毕,子线程就结束了 t1.start() # 子线程启动 time.sleep(3) # 主线程等三秒,这时候守护线程的第一轮循环差不多结束,但是第二次只会打印 开始执行,然后主线程时间就到了,守护线程自然就结束了,不会再打印 执行结束这句话 # 其实从守护线程的执行函数是一个死循环,但是程序运行会正常结束,也可以说明守护线程随着主线程代码执行结束而结束~
运行结果:
2. GIL全局解释器锁----只是锁线程,并不能真正保证数据安全
GIL只是在线程上加锁,可以保证同一时间只能有一个线程操作数据,但是并没有直接对数据加锁,所以对某些特殊情况(比如一个线程在时间片内操作数据,但代码还没执行完,时间片就轮转了,接着下一个线程操作数据,在时间片内完成了对数据的减一操作,等到时间片轮转到第一个线程时,继续上次没执行完的代码(上一次把数据取出来放到线程寄存器中,但是操作的并不是第二个线程减一之后的数据)所以数据虽然被操作了两次,但是最后仍然是减一放回去了(比如两个线程都是对n减一放回去))数据仍然是不安全的,所以需要再对数据加锁:
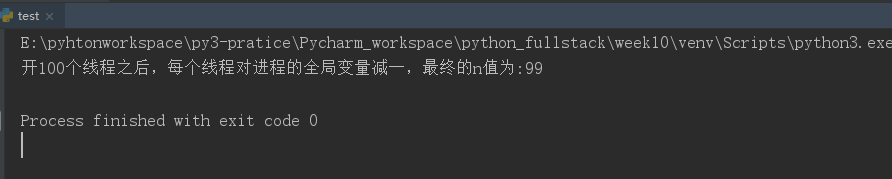
from threading import Thread import time import random def func(): global n # print("这部分代码,如果使用lock 开很多个线程的话都是多线程并发的,只有下面需要对数据加锁的部分,多线程是需要等待,也就是串行的") # time.sleep(3) # print("同样是上面这段代码,如果在每个线程开启后都使用join(),那多个线程之间就变为真正的同步了,加锁,然后在外部统一join()还可以保证上面那段代码多线程并发") temp = n time.sleep(random.randint(1,3)) # 这三句代码,只是为了让时间片轮转,一个线程执行时在时间片内代码并没有执行完,只是把要操作的数据放到线程寄存器, n = temp - 1 # 这样就会造成数据不安全(可以使用对数据加锁保证数据安全) n=100 # 进程中的全局变量,进程中的所有线程都可以共享的数据资源 t_lst=[] # 开多个线程时放到列表中,最后一起t.join()是为了让主线程需要等待子线程执行完毕(因为需要等所有子线程都操作完n之后再打印n的值)又能保证多个子线程之间并发 for i in range(100): t=Thread(target=func) t.start() t_lst.append(t) [t.join() for t in t_lst] # 所有子线程执行结束,才会执行主线程打印n的操作(因为本来就是想让所有子线程操作完n 再打印) 否则子线程还没全部执行,主线程就执行打印操作了 print("开100个线程之后,每个线程对进程的全局变量减一,最终的n值为:%s"%n)
运行结果:
如果对数据进行加锁呢(就会使数据更加安全)即使时间片内数据没操作完,但是这个线程的锁还没释放,即使下一个线程可以操作数据了(GIL的锁轮到他了),但是没有拿到数据的钥匙(对数据加的锁)因为上一个线程占用了,数据没执行完,还没释放,这样就可以保证数据的安全性;
from threading import Thread from threading import Lock # 互斥锁 import time import random def func(): global n # print("这部分代码,如果使用lock 开很多个线程的话都是多线程并发的,只有下面需要对数据加锁的部分,多线程是需要等待,也就是串行的") # time.sleep(3) # print("同样是上面这段代码,如果在每个线程开启后都使用join(),那多个线程之间就变为真正的同步了,加锁,然后在外部统一join()还可以保证上面那段代码多线程并发") lock.acquire() temp = n time.sleep(0.01) # 这三句代码,只是为了让时间片轮转,一个线程执行时在时间片内代码并没有执行完,只是把要操作的数据放到线程寄存器, n = temp - 1 # 这样就会造成数据不安全(可以使用对数据加锁保证数据安全) lock.release() n=100 # 进程中的全局变量,进程中的所有线程都可以共享的数据资源 lock=Lock() # 对线程需要操作的数据上锁 t_lst=[] # 开多个线程时放到列表中,最后一起t.join()是为了让主线程需要等待子线程执行完毕(因为需要等所有子线程都操作完n之后再打印n的值)又能保证多个子线程之间并发 for i in range(100): t=Thread(target=func) t.start() t_lst.append(t) [t.join() for t in t_lst] # 所有子线程执行结束,才会执行主线程打印n的操作(因为本来就是想让所有子线程操作完n 再打印) 否则子线程还没全部执行,主线程就执行打印操作了 print("开100个线程之后,每个线程对进程的全局变量减一,最终的n值为:%s"%n)
运行结果:

可能你会有疑问,那对线程的数据加锁,也就是同一时间只有一个线程可以拿到钥匙,操作数据,其他线程都得等着,不又变成同步了,其实这只是对加锁部分的数据来说,多个线程之间确实说串行的,但是对于多个线程需要执行的func()函数,不加锁部分的代码,其实多个线程是可以并发执行的(可以实现时间复用),如果真的使用join() 那么所有的代码,多个线程都是串行同步的了;
3. 死锁--可以使用递归锁RLock解决
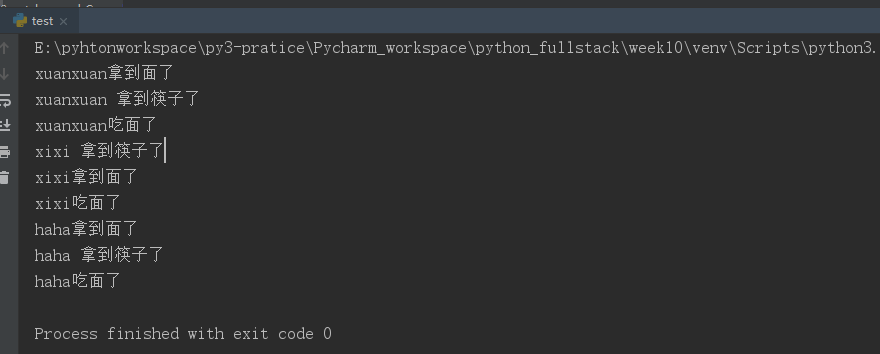
from threading import Thread from threading import Lock import time lock_1=Lock() # 管理面条的锁 lock_2=Lock() # 管理筷子的锁 def func1(name): lock_1.acquire() # 获取面的锁 print("%s拿到面了"%name) lock_2.acquire() print("%s 拿到筷子了"%name) print("%s吃面了"%name) lock_1.release() lock_2.release() def func2(name): lock_2.acquire() print("%s 拿到筷子了"%name) time.sleep(1) # 这里之所以让睡一秒,就是想触发死锁,让一个线程拿到筷子的锁,另一个线程在该线程的等待时间去拿面的锁,这样就会出现死锁,两个线程都进行等待状态 lock_1.acquire() print("%s拿到面了"%name) print("%s吃面了"%name) lock_2.release() lock_1.release() Thread(target=func1,args=("xuanxuan",)).start() # 开一个线程执行func1函数,会拿面 拿到筷子,吃面 执行完释放锁 Thread(target=func2,args=("xixi",)).start() # 开一个线程执行func2函数,先去拿筷子 获得锁,然后等1秒 Thread(target=func1,args=("haha",)).start() # 开一个线程执行func1 先去拿面,获得锁 所以就会出现一种情况,xixi拿着筷子的锁,haha 拿着面的锁,两个都陷入等待状态 # 上述现象就成为死锁
运行结果: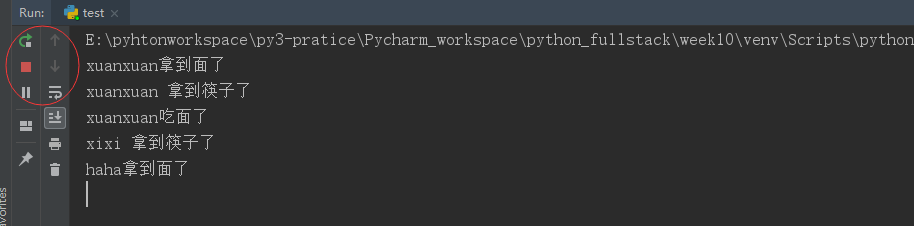
如果在不同线程中对两个数据都需要加锁,一个线程拿到其中一把的钥匙,另一个线程拿到另一把,这样两个线程就都陷入阻塞状态(死锁)解决死锁的方法可以使用递归锁(上面的Lock其实叫互斥锁,acquire之后必须等到release 下一次的acquire才不会出现阻塞)但是递归锁,可以在一个线程中多次acquire 只要最后释放同等数量release 其他线程就可以有机会拿到递归锁的钥匙:
先看一个简单版本的:
from threading import Thread from threading import RLock lock=RLock() # 递归锁,一个线程只要拿到递归锁,相当于获取了该线程所有需要加锁数据的万能钥匙 def func(): lock.acquire() print("该线程中需要加锁的数据") lock.acquire() # 如果是互斥锁就不行,必须得等锁的钥匙释放了,才能被别的使用 print("该线程中第二个需要加锁的数据") lock.release() lock.release() Thread(target=func).start()
运行结果: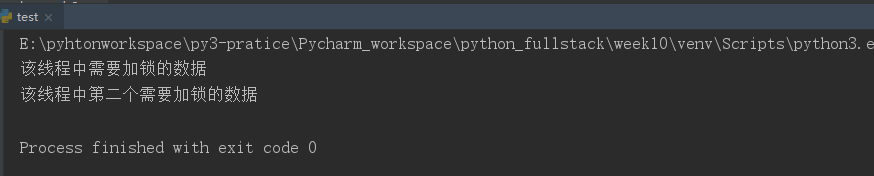
再来看吃面的例子---如果使用递归锁就不会出现死锁问题:
from threading import Thread from threading import RLock import time lock_1=lock_2=RLock() # 多个线程中都需要使用两个需要加锁的数据,就可以在线程中使用递归锁管理这两个数据, 递归锁的钥匙相当于万能钥匙,这一个线程中可以操作很多需要加锁的数据 # 这样一个线程拿到递归锁的钥匙,其他线程只能等待,不会出现一个线程拿到A数据的钥匙另一个线程拿到B数据的钥匙的死锁状态 def func1(name): lock_1.acquire() # 获取面的锁 print("%s拿到面了"%name) lock_2.acquire() print("%s 拿到筷子了"%name) print("%s吃面了"%name) lock_1.release() lock_2.release() def func2(name): lock_2.acquire() print("%s 拿到筷子了"%name) time.sleep(1) # 这里之所以让睡一秒,就是想触发死锁,让一个线程拿到筷子的锁,另一个线程在该线程的等待时间去拿面的锁,这样就会出现死锁,两个线程都进行等待状态 lock_1.acquire() print("%s拿到面了"%name) print("%s吃面了"%name) lock_2.release() lock_1.release() Thread(target=func1,args=("xuanxuan",)).start() # 开一个线程执行func1函数,会拿面 拿到筷子,吃面 执行完释放锁 Thread(target=func2,args=("xixi",)).start() # 开一个线程执行func2函数,先去拿筷子 获得锁,然后等1秒,拿着这把万能钥匙 Thread(target=func1,args=("haha",)).start() # 开一个线程执行func1 先去拿面,由于xixi开的线程已经拿到递归锁的钥匙,haha在的线程就会一直等待,直到xixi线程执行完毕,把锁归还,haha才有机会拿到锁 # 所以并不会出现死锁现象,因为一个线程只要第一个锁争夺到,就会一直使用,直到完全释放,其余线程才有机会抢钥匙
运行结果: