问题背景:项目开发测试阶段出现该问题。
复现:开发调试过程中一直没有问题,本地下载excel、Word、pdf 都完美,但是在服务部署到服务器之后,测试环境的chrome就总是下载失败,提示网络错误。
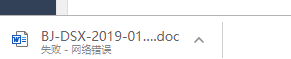 。
。
这时候追踪问题,本地测试时发现每次下载都会有问题警示:Resource interpreted as Document but transferred with MIME type application/octet-stream,
各种百度,大多数都是说修改content-type,但是不管修改成什么类型,抓包都显示返回了相应的类型,但下载就是不成功(不得不吐槽一下百度,真的是打广告一流)。
转战bing,成功找到解决办法:增加头信息Content-Length, ,其中bytes就是要下载的二进制流文件,
,其中bytes就是要下载的二进制流文件,
造成这种情况的原因,其实是高版本的chrome对字节流的下载进行了限制,需在头信息中声明字节流长度。(这里的限制具体是什么,等后续找到确切说法我再来更新)
2019.08.23 更新:这种方式导出的word有丢失文字现象。在头部增加的流的长度只是正文的长度(bytes.Length部分),还需要加上头部的长度,我这里加了5000,也是一点点测出来的。
2019-12-13 更新:这两天有用户反映导出Word失败,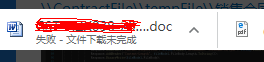 ,我先用自己电脑的chrome测试--没问题,向其询问了他使用的浏览器版本--chrome 79 最新版,下载之后尝试,果然有问题,本地调试也查不到原因,
,我先用自己电脑的chrome测试--没问题,向其询问了他使用的浏览器版本--chrome 79 最新版,下载之后尝试,果然有问题,本地调试也查不到原因,
就想着是不是字节流长度的问题,遂删除自己加的5000,测试--成功,没有丢失文字的现象!猜想可能是chrome升级后修复了某些bug,本来字节流长度也不该加上头信息的长度 呀(个人理解)
仅作为问题记录
解惑地址:https://blog.csdn.net/qq_34720759/article/details/79189480