数据库表sql语句:
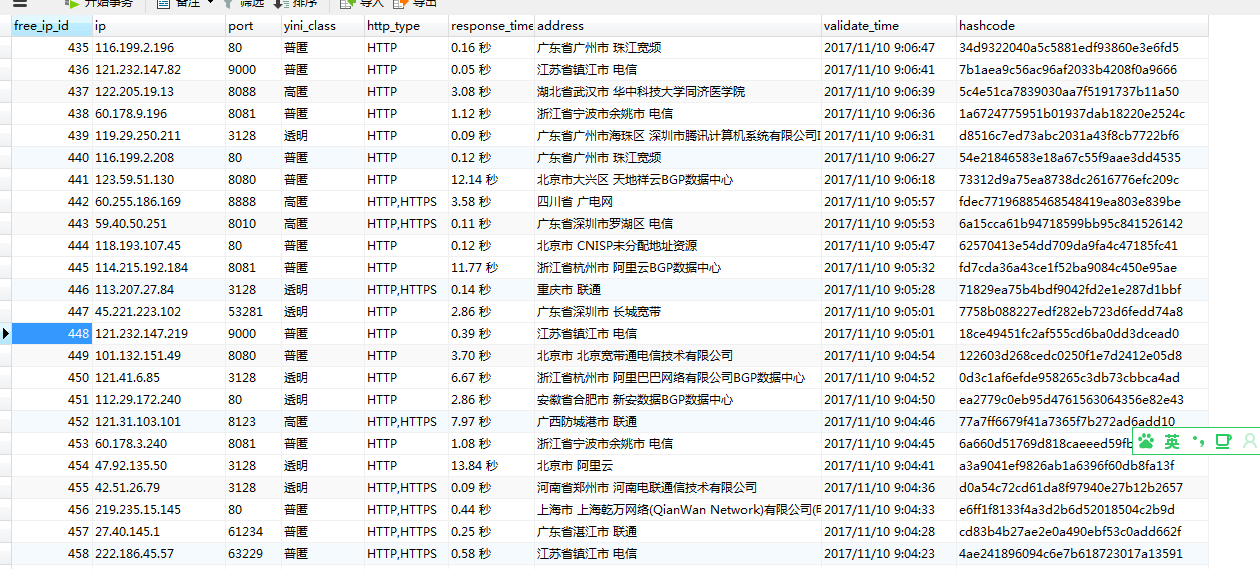
CREATE TABLE `free_ip` ( `free_ip_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `ip` varchar(255) DEFAULT NULL COMMENT 'ip地址', `port` varchar(255) DEFAULT NULL COMMENT '端口', `yini_class` varchar(255) DEFAULT NULL COMMENT '匿名等级', `http_type` varchar(255) DEFAULT NULL COMMENT '代理类型', `response_time` varchar(255) DEFAULT NULL COMMENT '响应时间', `address` varchar(255) DEFAULT NULL COMMENT '地理位置', `validate_time` varchar(255) DEFAULT NULL COMMENT '最近验证时间', `hashcode` varchar(255) DEFAULT NULL COMMENT '去重', PRIMARY KEY (`free_ip_id`), UNIQUE KEY `hashcode` (`hashcode`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=4220 DEFAULT CHARSET=utf8;
源代码:
# coding:utf-8 import random, re import sqlite3 import json, time import uuid from bs4 import BeautifulSoup import threading import requests import MySQLdb from lxml import etree import urllib3 urllib3.disable_warnings() import urllib2 import sys reload(sys) sys.setdefaultencoding('utf-8') session = requests.session() import logging import logging.handlers import platform sysStr = platform.system() if sysStr =="Windows": LOG_FILE_check = 'H:\log\log.txt' else: LOG_FILE_check = '/log/wlb/crawler/cic.log' handler = logging.handlers.RotatingFileHandler(LOG_FILE_check, maxBytes=128 * 1024 * 1024,backupCount=10) # 实例化handler 200M 最多十个文件 fmt = ' ' + '%(asctime)s - %(filename)s:%(lineno)s - %(message)s' formatter = logging.Formatter(fmt) # 实例化formatter handler.setFormatter(formatter) # 为handler添加formatter logger = logging.getLogger('check') # 获取名为tst的logger logger.addHandler(handler) # 为logger添加handler logger.setLevel(logging.DEBUG) def md5(str): import hashlib m = hashlib.md5() m.update(str) return m.hexdigest() def freeIp(): for i in range(1,1000): print "正在爬取的位置是:",i url = "http://www.ip181.com/daili/" + str(i)+ ".html" headers = { "Host":"www.ip181.com", "Connection":"keep-alive", "Upgrade-Insecure-Requests":"1", "User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.91 Safari/537.36", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "Referer":url, "Accept-Encoding":"gzip, deflate", "Accept-Language":"zh-CN,zh;q=0.8", } try: result = session.get(url=url,headers=headers).text result = result.encode('ISO-8859-1').decode(requests.utils.get_encodings_from_content(result)[0]) except: result = session.get(url=url, headers=headers).text result = result.encode('ISO-8859-1').decode(requests.utils.get_encodings_from_content(result)[0]) soup = BeautifulSoup(result, 'html.parser') result_soup = soup.find_all("div", attrs={"class": "col-md-12"})[1] result_soup = str(result_soup).replace(' ','').replace(' ','').replace(' ','').replace(' ','').replace(' class="warning"','') result_soups = re.findall('最近验证时间</td></tr>(.*?)</tbody></table><div class="page">共',result_soup)[0] print result_soups result_list = re.findall('<tr><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td></tr>',result_soups) for item in result_list: ip = item[0] port = item[1] yini_class = item[2] http_type = item[3] response_time = item[4] address = item[5] validate_time = item[6] proxy = str(ip) + ":" + port hashcode = md5(proxy) try: # 此处是数据库连接,请换成自己的数据库 conn = MySQLdb.connect(host="110.110.110.717", user="lg", passwd="456", db="369",charset="utf8") cursor = conn.cursor() sql = """INSERT INTO free_ip (ip,port,yini_class,http_type,response_time,address,validate_time,hashcode) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)""" params = (ip,port,yini_class,http_type,response_time,address,validate_time,hashcode) cursor.execute(sql, params) conn.commit() cursor.close() print " 插入成功 " except Exception as e: print "********插入失败********" print e freeIp()
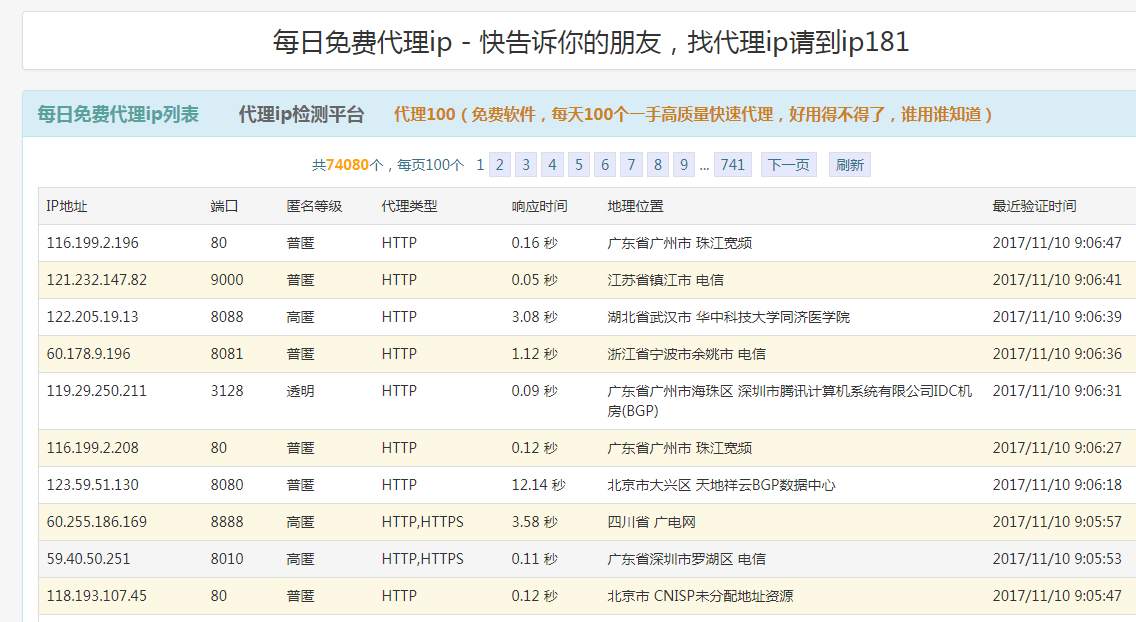
爬取效果: