1. 测试页面是 https://www.hao123.com/,这个是百度的导航
2. 为了避免网络请求带来的差异,我们把网页下载下来,命名为html,不粘贴其代码。
3.测试办法:
我们在页面中找到 百度新闻 关键字的链接,为了能更好的对比,使程序运行10000次,比较时间差异:
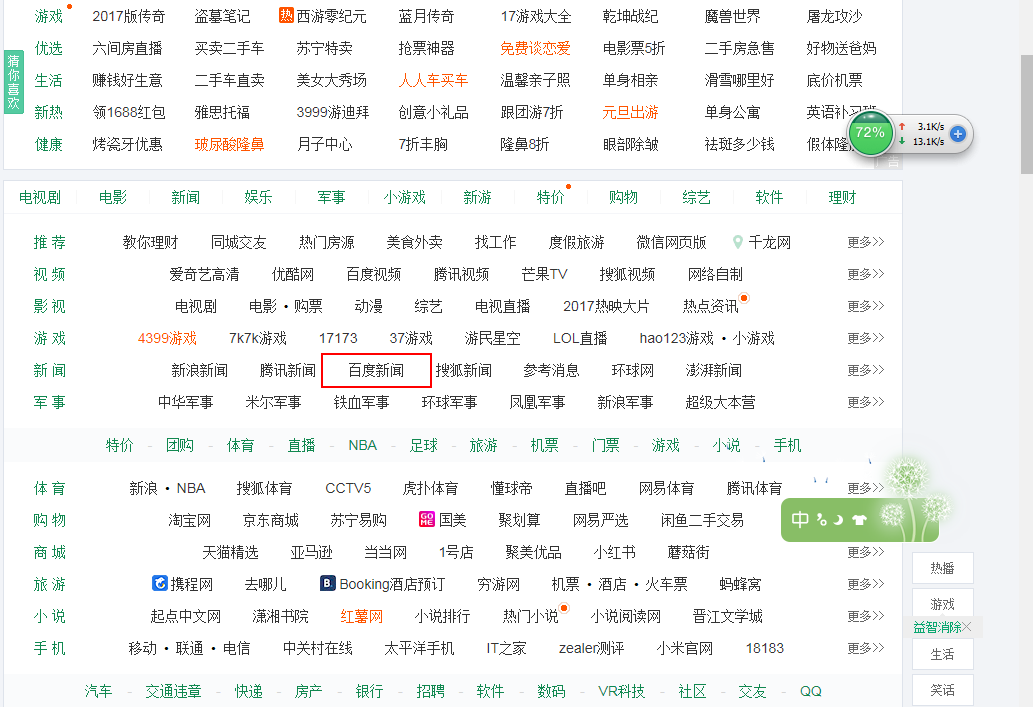
1.正则编码及其时间
start_time = time.time()
for i in range(0,10000):
baidu_news = re.findall('腾讯新闻</a></span><span><a class="sitelink mainlink singglelink" cls="xw,n" alog-custom="ind:xw,sal:0,atd:" href="(.*?)">百度新闻</a>',html)[0]
print baidu_news
end_time = time.time()
print "程序运行时间是:",end_time - start_time
运行时间:6.5 秒钟
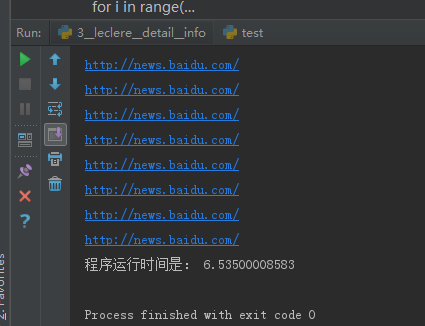
2.xpath 编码及其时间
start_time = time.time() selector = etree.HTML(html) for i in range(0,10000): content=selector.xpath('//*[@id="coolsite-top"]/div[4]/span[3]/a/@href')[0] print content end_time = time.time() print "程序运行时间是:",end_time - start_time
运行时间:17.39 秒钟
总结:其中 selector = etree.HTML(html) 将源码转化为能被XPath匹配的格式,这个过程失比较耗时的。
结论:正则效率优于xpath
如有异议,请联系作者,谢谢