本篇主要介绍网站数据非常大的采集心得
1. 什么样的数据才能称为数据量大:
我觉得这个可能会因为每个人的理解不太一样,给出的定义 也不相同。我认为定义一个采集网站的数据大小,不仅仅要看这个网站包括的数据量的大小,还应该包括这个网址的采集难度,采集网站的服务器承受能力,采集人员所调配的网络带宽和计算机硬件资源等。这里我姑且把一个网站超过一千万个URL链接的叫做数据量大的网站。
2. 数据量大的网站采集方案:
2.1 . 采集需求分析:
作为数据采集工程师,我认为最重要的是要做好数据采集的需求分析,首先要预估这个网址的数据量大小,然后去明确采集哪些数据,有没有必要去把目标网站的数据都采集下来,因为采集的数据量越多,耗费的时间就越多,需要的资源就越多,对目标网站造成的压力就越大,数据采集工程师不能为了采集数据,对目标网站造成太大的压力。原则是尽量少采集数据来满足自己的需求,避免全站采集。
2.2. 代码编写:
因为要采集的网站数据很多,所以要求编写的代码做到稳定运行一周甚至一个月以上,所以代码要足够的健壮,足够的强悍。一般要求做到网站不变更模板,程序能一直执行下来。这里有个编程的小技巧,我认为很重要,就是代码编写好以后,先去跑一两个小时,发现程序的一些报错的地方,修改掉,这样的前期代码测试,能保证代码的健壮性。
2.3 数据存储:
当数据量有三五千万的时候,无论是MySQL还是Oracle还是SQL Server,想在一个表里面存储,已经不太可能了,这个时候可以采用分表来存储。数据采集完毕,往数据库插入的时候,可以执行批量插入等策略。保证自己的存储不受数据库性能等方面的影响。
2.4 调配的资源:
由于目标网站数据很多,我们免不了要去使用大的带宽,内存,CPU等资源,这个时候我们可以搞一个分布式爬虫系统,来合理的管理我们的资源。
3. 爬虫的道德
对于一些初级的采集工程师,为了更快的采集到数据,往往开了很多的多进程和多线程,后果就是对目标网站造成了dos攻击,结果是目标网站果断的升级网站,加入更多的反爬策略,这种对抗对采集工程师也是极其不利的。个人建议下载速度不要超过2M, 多进程或者多线程不要过百。
示例:
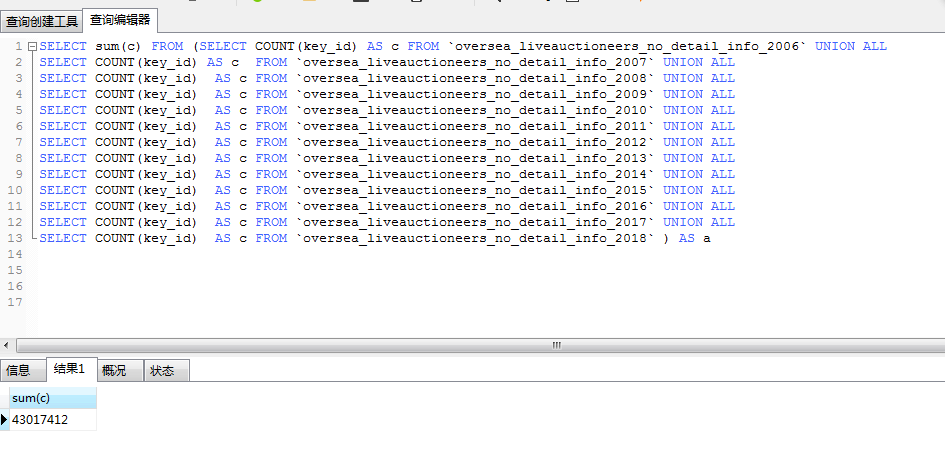
要采集的目标网站有四千万数据,网站的反爬策略是封ip,于是专门找了一台机器,开了二百多个进程去维护ip池,ip池可用的ip在500-1000个,并且保证ip是高度可用的。
代码编写完毕后,同是在两台机器上运行,每天机器开启的多线程不超过64个,下载速度不超过1M.
个人知识有限,请大牛多多包涵