一: 问题描述:
爬虫微博 信息,出现302跳转,
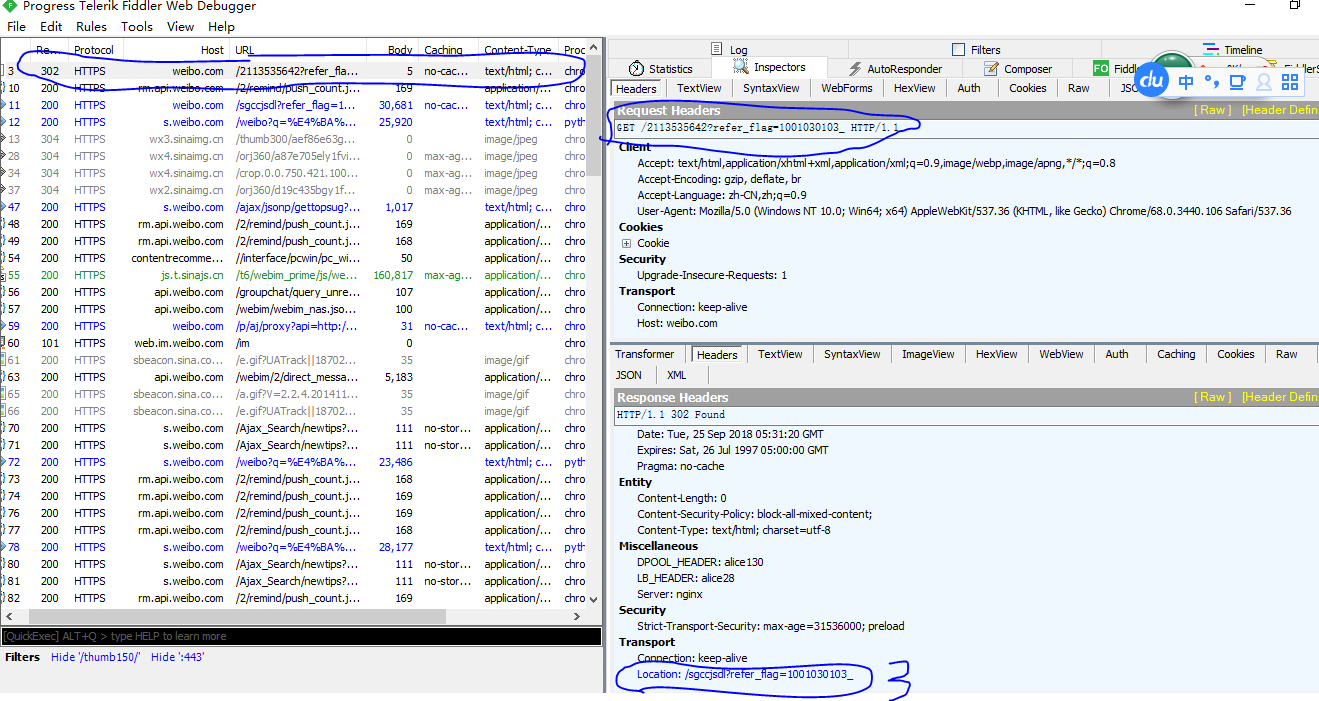
比如访问的URL是:https://weibo.com/2113535642?refer_flag=1001030103_ (图片中标记为1)
然后跳转的URL是:https://weibo.com/sgccjsdl?refer_flag=1001030103_&is_hot=1 (图片中标记为2)
截图如下所示:

访问 图中标记1 的URL的时候,没有返回任何内容,但是response headers 返回了 图中标记2 的URL。如下图所示:
下面是具体实现的代码过程:
result1 = session.get(url=str(user_url),headers=headers,verify=False,allow_redirects=False) result = result1.content new_requests_url = result1.headers['location'] new_requests_url = "https://weibo.com" + new_requests_url if '<h1 class="username">' not in result: result = session.get(url=str(new_requests_url), headers=headers, verify=False, allow_redirects=False).content
核心代码是获得需要跳转的URL,代码是 new_requests_url = result1.headers['location']