sql语法规则:
一、操作文件夹
1、创建数据库db2:create database db2;
2、创建数据库db2并标明数据库的编码格式为utf8:create database db2 default charset=utf8;--------------->为了插入中文
3、展示所有文件夹(数据库):show databases;
4、删除数据库db2:drop database db2;
二、操作文件
1、展示表:show tables;
2、创建表t1(id为整型,name为字符创长度为10):create table t1(id int,name char(10));
3、创建表t1(并设置):create table t1(id int,name char(10)) default charset=utf8;------------------>为了插入中文
4、引擎:帮我们做所有的动作的一个发动机或者代码
#innodb支持事物,原子性
#myisam
创建表t1最完善的方法(设置引擎为innodb,引擎innodb支持事物(回滚),引擎myisam支持全局索引):create table t1(id int,name char(10)) engine=innodb default charset=utf8;
5、auto_increment表示:自增;一个文件里面只能有一个自增;
primary key:表示 约束(不能重复且不能为空);加速查找;一个文件里面只能有一个主键;
#######默认数据不为空:create table t3(id int auto_increment primary key,name char(10))engine=innodb default charset=utf8;
auto_increment自增就算表被清空后再插入也是从上个id往下自增,不会从1开始。
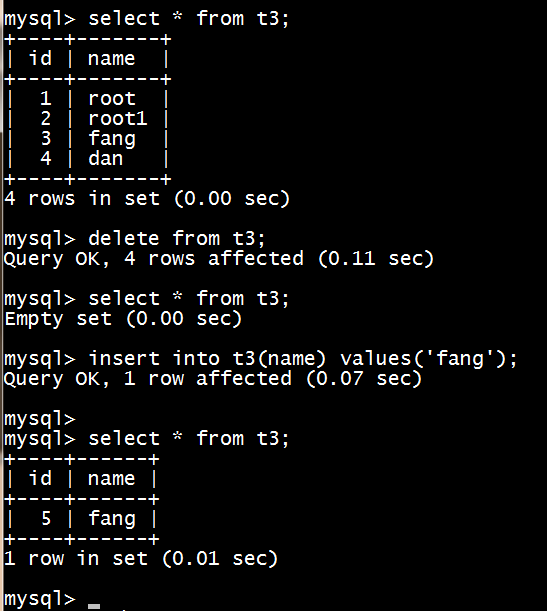
6、清空表:delete from t1;
truncate table t1;(数据大的时候速度比delete快多了)
7,删除表:drop table t1;
查看数据
查看表里面的内容:select * from t1;
插入数据
往表里面插入数据:insert into t1<id,name> values<1,'egon'>;
三、MySQL基本数据类型:
1,数值:


2,字符串


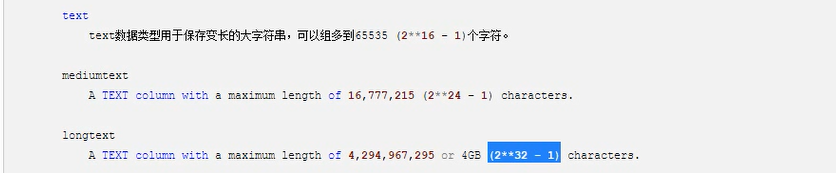
3,时间

4,枚举和集合

4、操作文件中的内容:增删改查
