在编程中我们经常会合并某个矩阵,通常我们会使用循环来实现,然而循环有时候会降低程序运行的效率,
所以利用ArrayFire中的向量的平坦模式,我们可以利用空间来换取时间。主要的思路是:
1.我们将m*n的矩阵展开成一个1*(m*n)或者(m*n)*1的向量;
2.同理我们将p*q的矩阵展开成一个1*(p*q)或者(p*q)*1的向量;
3.我们再次定义一个向量x=((p*q):(m*n))或x=((m*n):(p*q))将上述两个向量合并到一起;
4.现在我得到了一个一维的目标向量,现在我们要将这个目标向量拆开成a*b的目标矩阵,具体的做法是
再次定义一个f(a*b)的目标矩阵,将x向量的赋值给目标矩阵就可以实现了。
这样我们就不用使用循环来实现了,利用向量化的思路实现了空间换取时间。
代码如下:


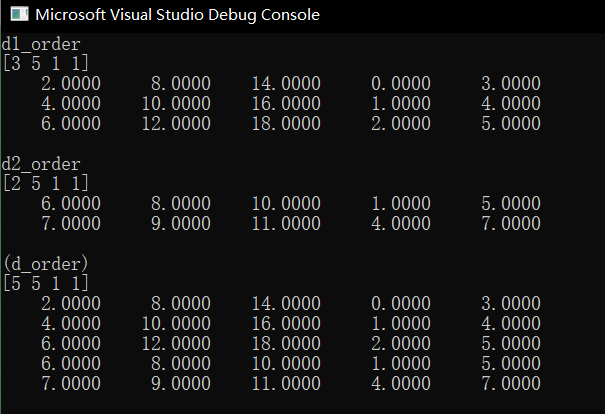
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> #include<arrayfire.h> #include<iostream> using namespace af; int main(void) { float h_a[] = { 0,1,2,3,4,5 }; float h_b[] = { 1,4,5,7 }; float h_c[] = { 6,7,8,9,10,11 }; float h_d[] = { 2,4,6,8,10,12,14,16,18 }; float dt = 1.0f; array d_b(3, 2, h_a); //' array d_d(2, 2, h_b); array d_c(2, 3, h_c); //' array d_a(3, 3, h_d); array d_R; //merge array_1 array d_f = af::join(0, af::flat((d_a)), af::flat((d_b))); float *yptr = d_f.device<float>(); array d1_order(3, 5, yptr); //d_order = transpose(d_order); //merge array_2 array d_g = af::join(0, af::flat((d_c)), af::flat((d_d))); float *gptr = d_g.device<float>(); array d2_order(2, 5, gptr); //merge array_3 array d_k = af::join(0, af::flat(transpose(d1_order)), af::flat(transpose(d2_order))); float *kptr = d_k.device<float>(); array d_order(5, 5, kptr); d_order = transpose(d_order); af_print(d1_order); af_print(d2_order); af_print((d_order)); return 0; }
在vs2017上运行如下: