本文旨在帮助读者介绍,如何使用excle实现数据驱动
本文是上文https://www.cnblogs.com/xuezhezlr/p/9096063.html的继续,如果没看上文建议自己看一下,对理解本文有很大帮助
上文中的程序是较为原始的数据驱动,虽然实现了数据驱动,但是本质上还是把数据写在代码里来读取,这种方式只是为了实现数据驱动而去做的数据驱动,意义并不大而且提高代码要求的技术水平,提高代码复杂度,反而不如原有代码逻辑性强,本文承接上文来介绍
public static Collection zlrshiyan(){
return Arrays.asList(new Object[][]{{2,6},{3,5}});
}
这部分是上文的代码中数据源头的片段,我们不禁想到,如果能从excle或者数据库等数据存储中取出数据,再加工为原有的字符串2维数据,即可使用这种方法,使得我们的数据源是excle,而代码是在另一个地方,运行时候读取即可
下文是excle的读取方法
public static String[][] getxlsData(String file, int ignoreRows,String a)
throws FileNotFoundException, IOException{
File file1 = new File(file);
return getxlsData(file1,ignoreRows,a);
}
public static String[][] getxlsData(File file, int ignoreRows,String a)
throws FileNotFoundException, IOException {
List<String[]> result = new ArrayList<String[]>();
int rowSize = 0;
BufferedInputStream in = new BufferedInputStream(new FileInputStream(
file));
// 打开HSSFWorkbook
a = a.replaceAll("/","_");//替换a为xls可以接受的类型
a=a.substring(1,a.length()).trim();//去掉第一个_
POIFSFileSystem fs = new POIFSFileSystem(in);
HSSFWorkbook wb = new HSSFWorkbook(fs);
HSSFCell cell = null;
int sheetIndex;
for (sheetIndex = 0; sheetIndex < wb.getNumberOfSheets(); sheetIndex++) {
if(wb.getSheetName(sheetIndex).equals(a))
{
break;
}
}
HSSFSheet st = wb.getSheetAt(sheetIndex);
// 第一行为标题,不取
for (int rowIndex = ignoreRows; rowIndex <= st.getLastRowNum(); rowIndex++) {
HSSFRow row = st.getRow(rowIndex);
if (row == null) {
continue;
}
int tempRowSize = row.getLastCellNum();
if (tempRowSize > rowSize) {
rowSize = tempRowSize;
}
String[] values = new String[rowSize];
Arrays.fill(values, "");
boolean hasValue = false;
for (short columnIndex = 0; columnIndex <= row.getLastCellNum()-1; columnIndex++) {
String value = "";
cell = row.getCell(columnIndex);
if (cell != null) {
// 注意:一定要设成这个,否则可能会出现乱码
cell.setEncoding(HSSFCell.ENCODING_UTF_16);
switch (cell.getCellType()) {
case HSSFCell.CELL_TYPE_STRING:
value = cell.getStringCellValue();
break;
case HSSFCell.CELL_TYPE_NUMERIC:
if (HSSFDateUtil.isCellDateFormatted(cell)) {
Date date = cell.getDateCellValue();
if (date != null) {
value = new SimpleDateFormat("yyyy-MM-dd")
.format(date);
} else {
value = "";
}
} else {
value = new DecimalFormat("0").format(cell
.getNumericCellValue());
}
break;
case HSSFCell.CELL_TYPE_FORMULA:
// 导入时如果为公式生成的数据则无值
if (!cell.getStringCellValue().equals("")) {
value = cell.getStringCellValue();
} else {
value = cell.getNumericCellValue() + "";
}
break;
case HSSFCell.CELL_TYPE_BLANK:
break;
case HSSFCell.CELL_TYPE_ERROR:
value = "";
break;
case HSSFCell.CELL_TYPE_BOOLEAN:
value = (cell.getBooleanCellValue() == true ? "Y"
: "N");
break;
default:
value = "";
}
}
if (columnIndex == 0 && value.trim().equals("")) {
break;
}
values[columnIndex] = rightTrim(value);
hasValue = true;
}
if (hasValue) {
result.add(values);
}
}
in.close();
String[][] returnArray = new String[result.size()][rowSize];
for (int i = 0; i < returnArray.length; i++) {
returnArray[i] = (String[]) result.get(i);
}
for(int i=1;i<returnArray.length;i++) {
returnArray[i][2] = returnArray[0][2] + "=" + returnArray[i][2];
for (int j = 3; j < returnArray[0].length; j++) {
returnArray[i][2] = returnArray[i][2] + "&" + returnArray[0][j] + "=" + URLEncoder.encode(returnArray[i][j],"utf-8");
}
}
String[][] returnArray2 = new String[result.size()-1][3];
for(int i=0;i<returnArray.length-1;i++)
for (int j = 0; j <= 2; j++) {
returnArray2[i][j]=returnArray[i+1][j];
}
return returnArray2;
}
/**
* 去掉字符串右边的空格
* @param str 要处理的字符串
* @return 处理后的字符串
*/
public static String rightTrim(String str) {
if (str == null) {
return "";
}
int length = str.length();
for (int i = length - 1; i >= 0; i--) {
if (str.charAt(i) != 0x20) {
break;
}
length--;
}
return str.substring(0, length);
}
在上文中主要写的就是public static String[][] getxlsData(String file, int ignoreRows,String a)这个方法,这个方法中file是写excle的路径,ignoreRows是指excle中最上面起到提示作用的那几行,代码会直接忽略不读取,而a是字符串,是指在excle中指定的sheet页的名称,这样代码中就会只读取该sheet页的数据,可喜的是代码会把数据转化为二维数组,那正是我们在原有代码中所需要的数据结构啊
下图是文章中的excle的图片
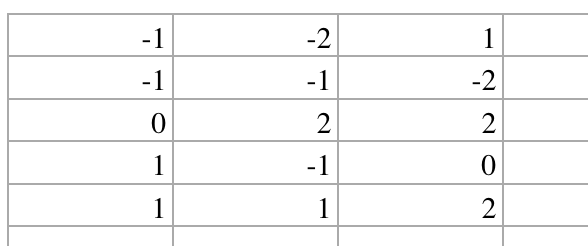
如上图的excle,到了代码里面就会变为一个3*5的2位数组形式,然后按照原先的初始化一样,即可完成初始化
private int a;
private int b;
private int c;
private int d;
@Parameterized.Parameters
@SuppressWarnings("unchecked")
public static Collection zlrshiyan() throws IOException {
File file = new File("/Users/zlr/Desktop/TestAuto_Integration/ExcelDemo.xls");
Object[][] object = getxlsData(file, 0, "/a");
return Arrays.asList(object);
// return Arrays.asList(new Object[][]{{2,6},{3,5}});
}
public zlrshiyan(String b,String d,String e){
System.out.print(b+d+e);
this.b = Integer.parseInt(b);
this.d= Integer.parseInt(d);
System.out.print(b+d);
}
@Before
public void testinit() throws Exception{
a=1;
c=3;
}
@Test
public void test1() throws Exception{
Assert.assertEquals(a+b+c, d);
}
}
在上文代码中object就是文件以a命名的sheet页所转化为的3*5的二维数组,然后就像之前一样的执行效果
这样的代码是可以复用的,如何复用呢?说实话,有点low,后来我来到了大公司,学习了spring,学习了mybits,学会了从数据库中读取代码而非这种,从excle读取代码,不过换汤不换药,思路很相近,本文来用文字大致介绍一下我在上上家公司的工作成果和自动化思路
在上文的代码中可以见到,已经将数据和代码执行逻辑分开了,那么实际上,如果某些代码的处理逻辑不同而数据数量和参数名等很相同,不同的只是参数值的话,那么可以使用一个excle的一个sheet页面来储存测试数据,而代码的处理逻辑是不变的~~这令我不禁想到了接口测试,同一个接口,往往参数设计和一些调用甚至返回断言逻辑是不变的,而变化的,往往是每次传进去的参数或者是接口启动的环境(线上,测试,甚至预发环境),这些有时候真的,比较适合而且本人实际验证了,可以使用上述代码来实现,也可以把数据载体换为数据库等,但是思路完全一样,一个sheet页其实就是数据库中的一张表啊,很相似的
另一方面,我们会想到一个问题,那就是多个接口如何去做。由于每个接口传参数不同,而且每个接口的代码调用方法,校验逻辑也不尽相同,所以,不同接口之间的test往往不一样,导致一个class文件一个接口,而数据源头,不管是excle或者是数据库,设计的方案都是越简单越好的,所以往往也一样,是一个库一个sheet页一个接口,就像下图一样
下面来讨论一下这一套框架吧
我在多个公司搭建自动化工具,其中这个框架,基本上是接口自动化框架中我所用的主流框架,我所说的接口自动化,不是人来做的那种半自动化而是全自动化,当然,可以在这个框架基础上开发各种前端的代码,使得测试人员能使用非sql语句的方式,如页面点击等等方式修改文档中的数值以及sheet页等等,不过那些的本质思路都没变化,都是在这个框架上的拓展
总的来说,这种数据驱动的自动化框架,从根本上解决了问题,如何去把代码和测试数据,分割开,使得测试人员或者其他人员,在接口逻辑不变的基础上,只需要通过一些方法,修改数据库或者文档就可以实现了对测试方式的控制,这真的是很不错的代码思维,而且,从根本上也方便了不懂代码的人执行自动化,直接降低了自动化的成本,但是,在我现在看来,其实实际上,往往公司的自动化是由少数几个同事搞起来的,而其他不懂代码的人根本不用,,,而且往往不懂代码的测试人员也没有那么强的上进心去懂代码,所以,我现在对所谓的让不会代码的人也来做自动化这个初衷表示怀疑,真的
如果把初衷改为,让测试开发们,写出的自动化确实常常因为版本的更替而不适用需要修改,这时,自动化代码的开发者,流动性又很强,那么我们的代码,可读性真的,还不错其实,交接起来很容易,即便没有交接,新人来理解往往也很容易
上述是杂谈,总之对于写一个接口自动化的后台代码而言,这一套代码,在实际运行中也遇到过各种各样的问题啊,,,下一篇文章会有所讲解的