No.1. kNN算法中需要传入一个参数k,这个参数k的作用之前提到过,它就是指距离待预测数据最近的前k个数据,这个参数k的具体大小应该如何选择?超参数问题就是描述的这类问题。
No.2. 所谓"超参数",就是指在算法运行之前需要进行指定的参数;与"超参数"向对应的是"模型参数","模型参数"是在算法运行过程中学习得到的参数。需要提的一点是,kNN算法中并没有模型参数,但是,kNN算法中的参数k,是典型的超参数。机器学习算法工程师的一项重要工作就是"调参",通常来讲,调参所要调的就是超参数。
No.3. 寻找好的超参数的方法
主要有三种方法:根据相关领域的知识来确定超参数;根据经验数值来确定超参数;实验搜索确定超参数
No.4. 下面我们通过实验搜索来确定超参数
实验前的准备
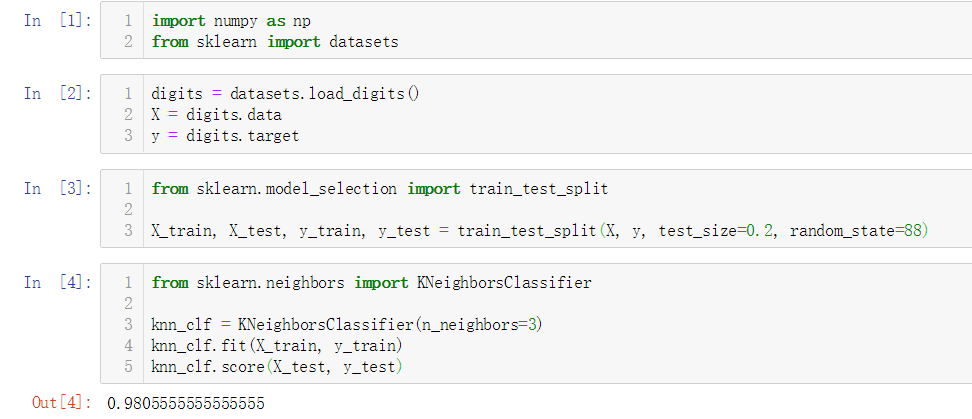
寻找参数的具体逻辑

No.5. kNN近邻算法中还有一个比较隐秘的超参数,即待预测点与训练数据集中每个点的距离,当最终的k个点里面每种类型的点数相同的情况下,我们就必须要考虑哪种类型的点与待预测点更接近;即使在每种类型的点数不同的情况下,如果点数多的类型距离待预测点都相对较远,我们也有必要考虑加入距离权重。
考虑距离权重的情况下,再次进行参数寻找
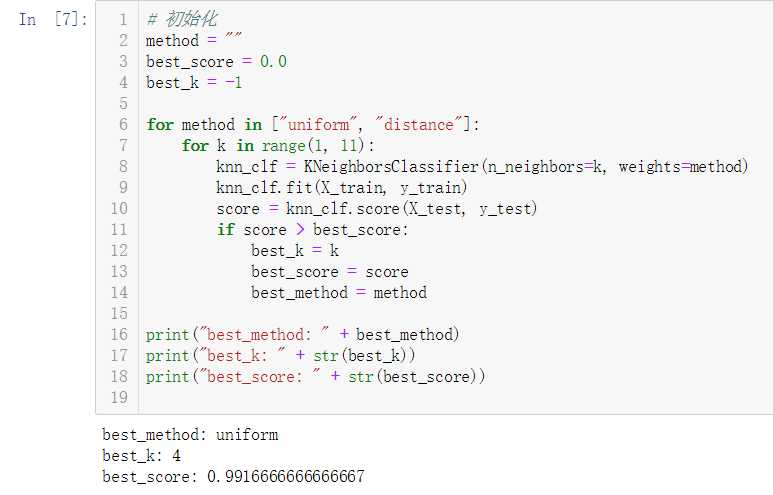
从运行结果来看,对于这个数据集,在不考虑距离、参数k为4的情况下,准确性更高
No.6. 我们之前计算待预测点与训练数据集中的每个点的距离,使用的都是"欧拉距离",即下图中参数p为2时的情况;当这个参数p的值为1时,这个距离称之为"曼哈顿距离";这个带参数p的距离公式称之为"明可夫斯基距离",这里的参数p也是一个"超参数",我们同样可以寻找最佳参数p
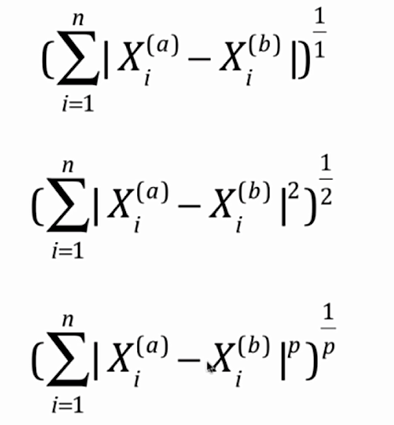
将参数p添加到业务逻辑中:
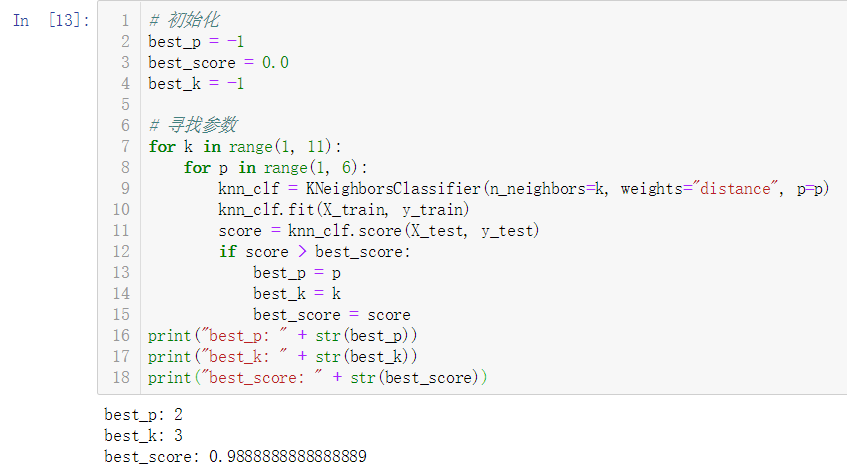
从运行结果来看,考虑距离权重的情况下,使用欧拉距离,并选择k值为3会使准确性更高
No.7. 上面的参数寻找过程存在一个问题:有些参数之间存在关联,我们想要寻找更佳的参数p的话,weights参数的值就必须选择为"distance",否则传入的参数p就会无效,sklearn提供了一种更好的参数搜索方式——网格搜索"Grid Search"
No.8. 在使用Grid Search之前,首先要定义我们的参数

进行参数搜索:
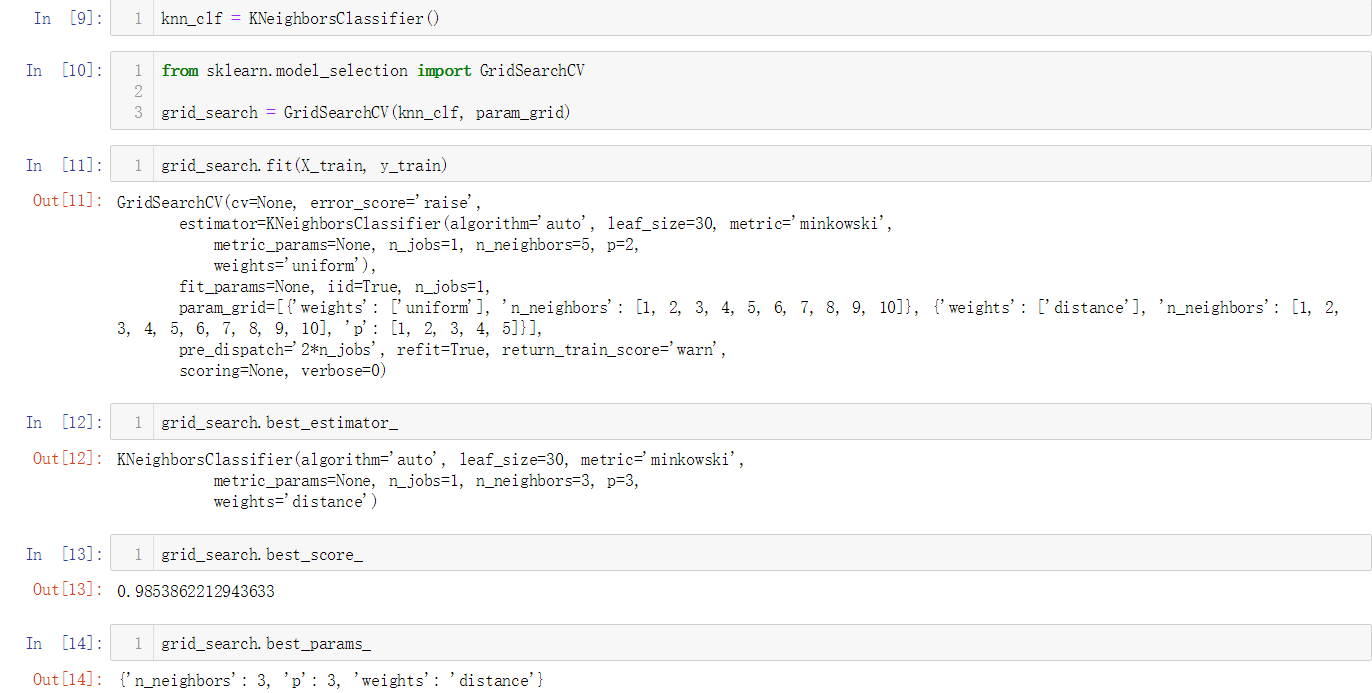
从上面搜索的结果来看,在考虑距离权重,且用于距离计算的参数p为3,k值为3的情况下准确性更好
No.9. 搜索得到最佳参数之后,我们需要使用这些最佳参数所以对应的分类器,来对测试数据进行预测
查看预测的准确率:

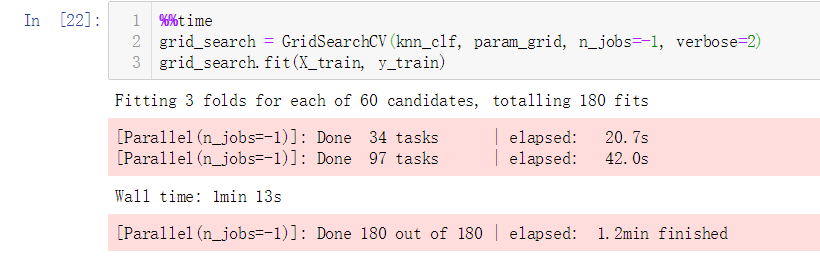
No.10. Grid Search中还有一些其它的参数,"n_jobs"用于指定进行搜索使用的CPU核心数,该参数设置为-1时会使用CPU的所有核心;"verbose"用于显示搜索的过程,指定的数值越大,显示的信息越详细