如需要使用到Solr中的dataimporthandler增量导入功能,则还需要引入两个所依赖的jar包,在上一篇随笔中所提到的下载的Solr项目文件solr-4.10.3dist目录下可以找到所依赖的两个jar包,即
将这两个jar包复制到我们本地Solr服务器下的WEB-INFlib目录下,同时需在索引库中的conf目录下,添加data-config.xml配置文件
,data-config.xml则是用来配置数据源,dataimport.properties则是记录生成索引库的时间,该文件会在索引库数据创建完毕后,自动生成。
完成以上两步后,还有非常重要的一步就是,将dataimport-handler处理器与data-config.xml相结合的配置
在索引库中的conf目录下存有一个名为solrconfig.xml的配置文件,需要在该配置文件中添加以下配置文件
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
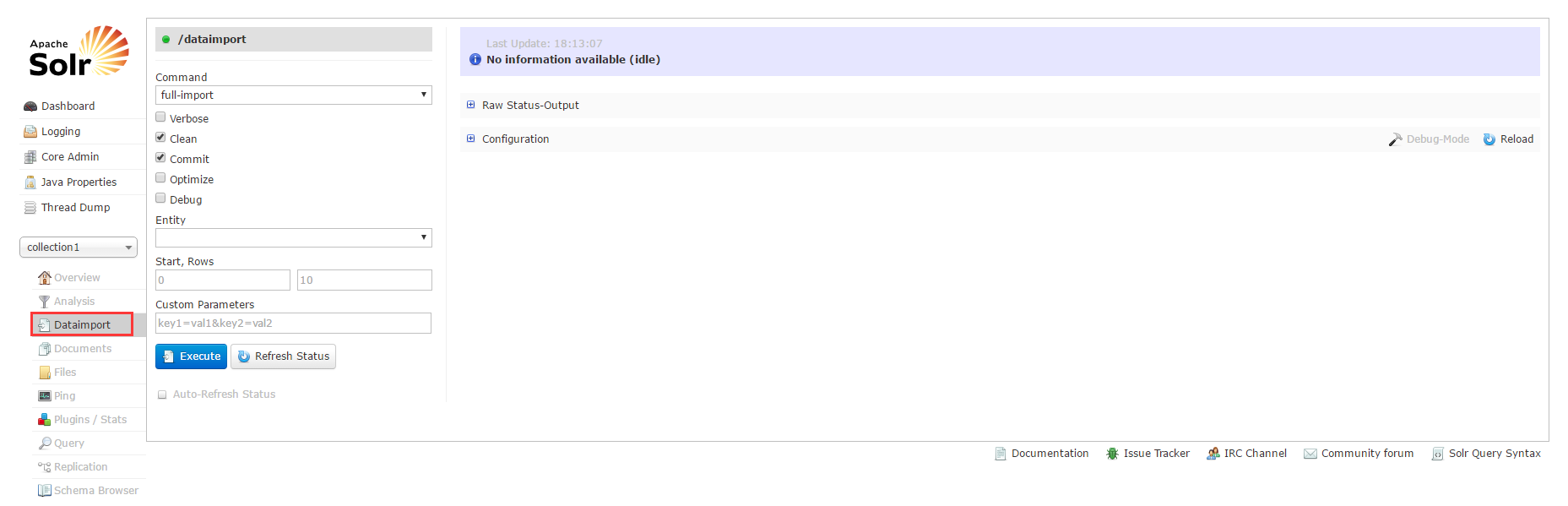
从而在Solr可视化管理页面中的Dataimport菜单中可以看到如下效果
接下来就是对data-config.xml文件与相匹配的schema.xml进行相应的配置,才能最终实现数据源的导入
data-config.xml
<?xml version="1.0" encoding="UTF-8" ?> <dataConfig> <dataSource driver="oracle.jdbc.driver.OracleDriver" url="jdbc:oracle:thin:@192.168.10.32:2016:sxlib" user="TT" password="TT"/> <document> <entity name="CIP_Book" transformer="ClobTransformer" pk="GID" query="select cb.gid gid, cb.gid bibGid, decode(cb.bib_name, null, '未知', regexp_replace(cb.bib_name, '[,|,||| | |(|)|.|[|]|+|-|!|{|}|^|~|#|?|:|;|&|]', '')) bibName, decode(cb.author, null, '未知', regexp_replace(cb.author, '[,|,||| | |(|)|.|[|]|+|-|!|{|}|^|~|#|?|:|;|&|]', '')) author, decode(cb.pub_name, null, '未知', cb.pub_name) pubName, ct.cre_date updatetime from cip_bookinfo cb join cip_bookdetail ct on cb.gid = ct.bib_gid" > <field column="gid" name="gid"/> <field column="bibGid" name="bibGid"/> <field column="bibName" name="bibName"/> <field column="author" name="author"/> <field column="updatetime" name="updateTime"/> </entity> </document> </dataConfig>在schema.xml中,Solr已经内置了很多field,但是为了符合开发需要,需要自定义符合自身需求的field,如在data-config.xml中,根据数据所查询出的书名、作者、出版社三个字段,那么在schema.xml则定义三个与之匹配的三个field,这样数据源的数据才能最终交予Solr进行管理
<field name="bibName" type="text_ik" indexed="true" stored="true"/> <field name="author" type="text_ik" indexed="true" stored="true"/> <field name="pubName" type="text_ik" indexed="true" stored="true"/>另外需要注意的是,根据数据源数据库的类型,导入对应的数据库依赖包。
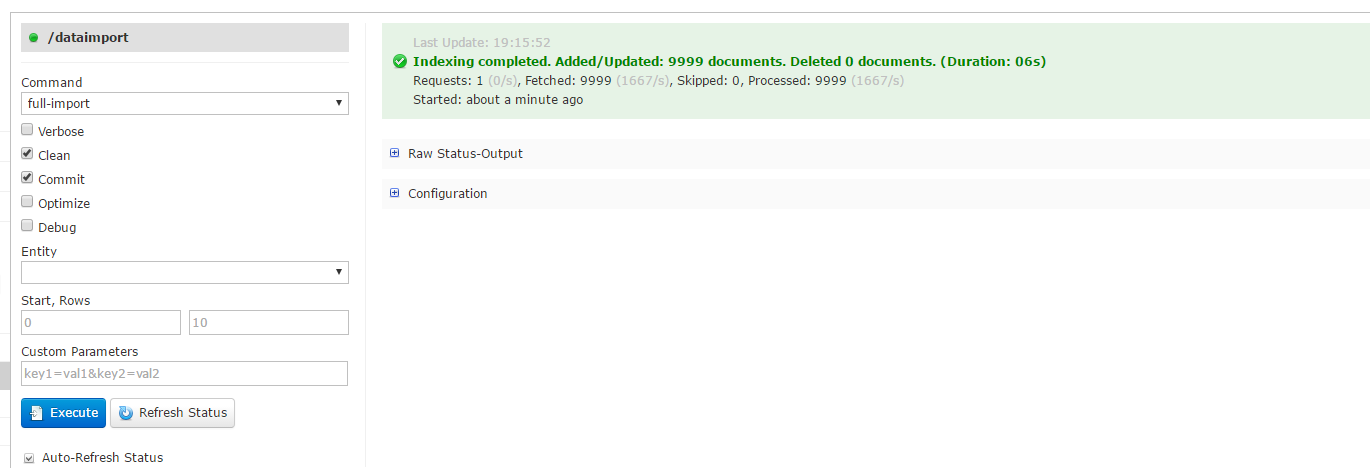
在Dataimport菜单页中点击Exceute,则会根据所配置好的数据源,实现数据导入
数据导入完毕后,通过Query菜单页可实现对数据的查询功能