HDFS:Hadoop Distributes File System

HDFS 1.0
Namenode
namenode又称名称节点,是负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即Fslmage和Editlog.你可以把它理解为大管家,它不负责存储具体的数据。
- Fslmage用于维护文件系统树以及文件树所有的文件和文件夹的元数据
- 操作日志文件Editlog中记录了所有针对文件的创建,删除,重命名等操作。
- 注意这两个都是文件也会加载解析到内存中。
为啥会拆成两个呢?主要是因为fasimage这个文件会很大的,多了之后就不好操作了,就拆分成两个。把后续增量的修改放到Editlog中,一个Fslmage和一个Editlog进行合并会得到一个新的fslmage.
因为它是系统的大管家,如果这个玩意坏了,丢失了。就相当于你系统的引导区坏了。整个文件系统就崩溃了。所以这个重要的东西需要备份。这个时候就产生了一个叫SecondaryNameNode的节点用来做备份,它会定期的和nmaenode进行通信来完成整个的备份操作。具体的操作如下:
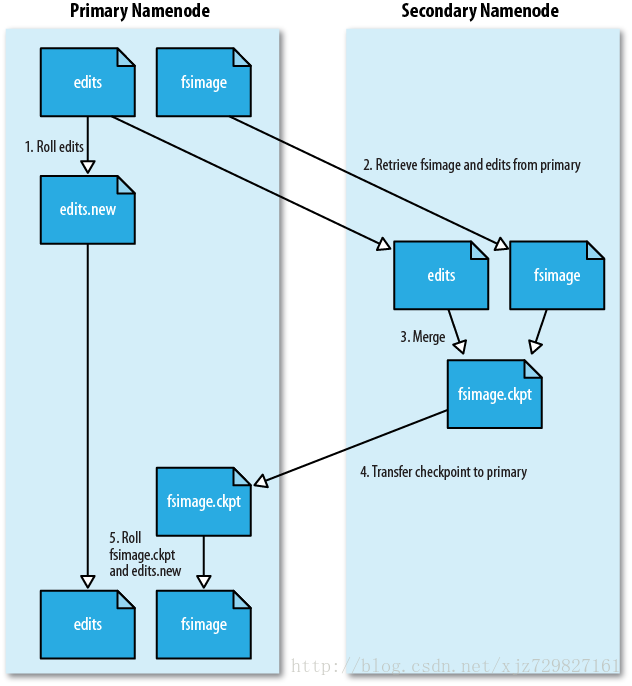
SecondaryNameNode的工作情况:
1.SecondaryNameNode会定期和namenode通信,请求其停止使用Editlog文件,暂时将新写的操作写道一个新的文件Edit.new上来。这个操作事瞬间完成,上层写日志的函数完全感觉不到差别;
2.SecondaryNameNode通过HTTP GET方式从Namenode上获取到Fsnage和FEditlog文件并下载到本地的相应目录下;
3.SecondaryNameNode将下载下来的fslmage载入到内存,然后一条一条的执行Editlog文件中的各项更新操作,使得内存中的fslmage保持最新,这个过程就是Editlog和Fslmage文件合并。
4.SecondaryNameNode执行完(3)操作之后,会通过post当时将新的Fslmage文件发送到NameNode节点上。
5.NameNode将从SecondaryNameNode接收到的新的Fslmage替换旧的Fslmage文件同时将edit.new替换Editlog文件,通过这个过程editlog就变小了
除了这个自带的备份操作,还需要进行人工的备份,把一份fsimage到多个地方进行备份,万一namenode的节点坏了呢。
DataNode
datanode数据节点,用来具体的存储文件,维护了blockld和datanode本地文件的映射。需要不断的与namenode节点通信,来告知其自己的信息,方便namenode来管控整个系统。
这里还提到一个块的概念,就想linux本地文件系统也有块的概念一样,这里也有块的概念,这里的块默认事128m,每个块都会默认存储三份
HDFS 2.0
有问题就得改,1.0出现很多问题
- 单点故障问题
- 不可以水平扩展
- 系统整体性能受限于单个名称节点的吞吐量
- 单个名称节点难以提供不同程序之间的隔离性
- HDFS HA是热备份,提供高可用性,但是无法解决可扩展性,系统性能和隔离性
解决上面这些问题所使用的手段就是热备份
热备份(HDFS HA)
- HDFS HA是为了解决的难点故障问题
- HA集群设置两个名称节点,活跃 和 待命
- 两个名称节点的状态同步,可以借助于一个共享存储系统来实现、
- 一旦活跃名称节点出现故障,就可以立即切换到待命名称节点
- Zookeeper确保一个名称节点在对外服务
- 名称节点维护映射信息,数据集欸但哦同时向两个名称节点汇报信息

Federation
- 多个命名空间。为了处理一个namenode的局限性,高了几个namenode大家一起来管理。就像编程中的命名空间一样
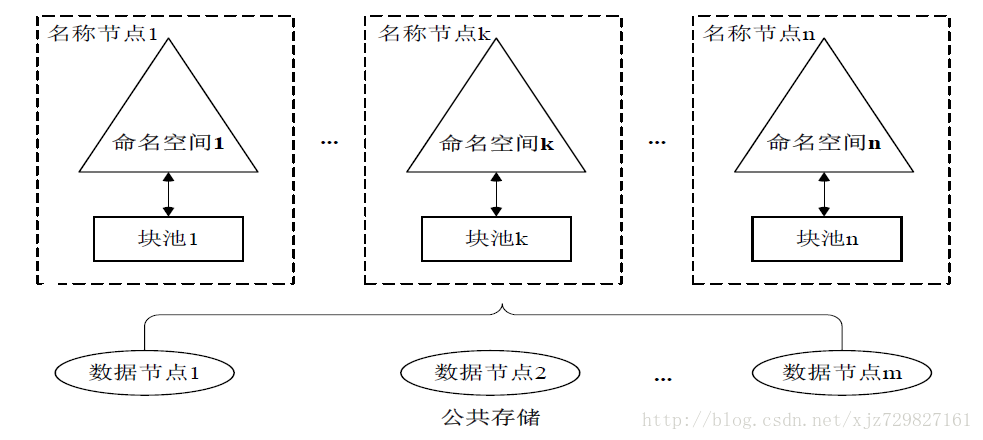
- 在HDFS Federation中,设计了多个相互独立的名称节点,使得HDFS的命名服务能够水平扩展,这些名称节点分别进行各自命名空间和块的管理,相互之间是联盟关系,不需要彼此协调,并且向后兼容
- HDFS Federation中,所有名称节点会共享底层的数据节点存储资源,数据节点向所有名称节点汇报
- 属于同一命名空间的 块构成一个“块池”
HDFS Federation设计可解决但名称节点存在的一下几个问题
1.hdfs集群扩展性。多个名称节点各自分管一部分目录,使得一个集群可以扩展到更多节点,不再像hdfs1.0中那样由于内存的限制制约文件存储数目
2.性能更高效。多个名称节点管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率
3.良好的隔离性。用户可根据需要将不同业务数据交到不同名称节点管理,这样不同业务之间影响很小。