我们知道 HDFS 最早是根据 GFS(Google File System)的论文概念模型来设计实现的。
然后呢,我就去把 GFS 的原始论文找出来仔细看了遍,GFS 的整体架构图如下:
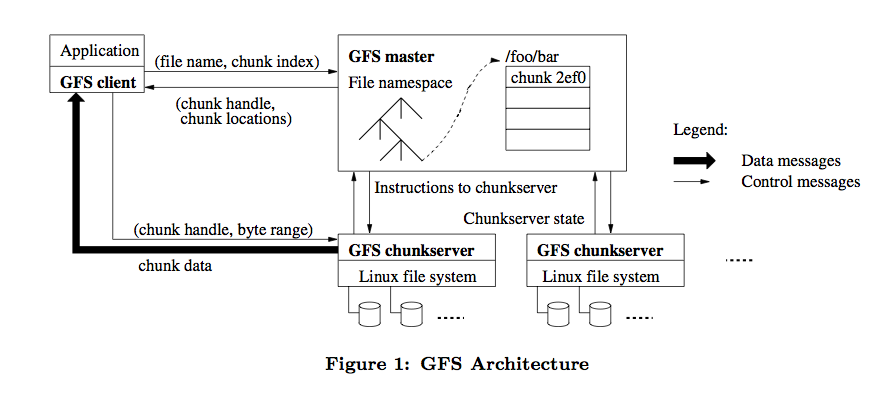
HDFS 参照了它所以大部分架构设计概念是类似的,比如 HDFS NameNode 相当于 GFS Master,HDFS DataNode 相当于 GFS chunkserver。
但还有些细节不同的地方,所以本文主要分析下不同的地方。
写入模型
HDFS 在考虑写入模型时做了一个简化,就是同一时刻只允许一个写入者或追加者。
在这个模型下同一个文件同一个时刻只允许一个客户端写入或追加。
而 GFS 则允许同一时刻多个客户端并发写入或追加同一文件。
允许并发写入带来了更复杂的一致性问题。
多个客户端并发写入时,它们之间的顺序是无法保证的,同一个客户端连续追加成功的多个记录也可能被打断。
这意味着一个客户端在连续写入文件数据时,它的数据最终在文件中的分布可能是不连续的。
所谓一致性就是,对同一个文件,所有的客户端看到的数据是一致的,不管它们是从哪个副本读取的。
如果允许多个客户端同时写一个文件,怎么保证写入数据在多个副本间一致?
我们前面讲 HDFS 时它只允许一个写入者按流水线方式写入多个副本,写入顺序一致,写入完成后数据将保持最终一致。
而对多个客户端而言,就必须让所有同时写入的客户端按同一种流水线方式去写入,才可能保证写入顺序一致。
这个写入流程我们下一节详细分析。
写入流程
GFS 使用租约机制来保障在跨多个副本的数据写入中保持顺序一致性。
GFS Master 将 chunk 租约发放给其中一个副本,这个副本我们就称为主副本,其他副本称为次副本。
由主副本来确定一个针对该 chunk 的写入顺序,次副本则遵守这个顺序,这样就保障了全局顺序一致性。
chunk 租约机制的设计主要是为了减轻 Master 的负担,由主副本所在的 chunkserver 来承担流水线顺序的安排。
如下图,我们详细描述下这个过程。
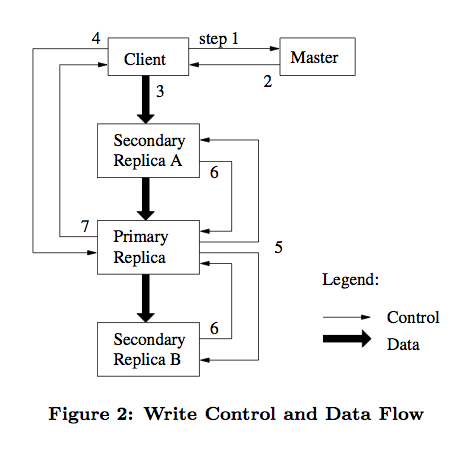
- 客户端请求 Master 询问哪个 chunkserver 持有租约以及其他副本的位置。
如果没有 chunkserver 持有租约,说明该 chunk 最近没有写操作。
Master 则选择将租约授权给其中一台 chunkserver。 - Master 返回客户端主副本和次副本的位置信息。
客户端缓存这些信息以备将来使用。
客户端以后不再需要联系 Master,除非主副本所在 chunkserver 不可用或返回租约过期了。 - 客户端选择最优的网络顺序推送数据,chunkserver 将数据先缓存在内部的 LRU 缓存中。
GFS 中采用数据流和控制流分离的方法,从而能够基于网络拓扑结构更好地调度数据流的传输。 - 一旦所有的副本确认收到了数据,客户端将发送一个写请求控制命令到主副本。
由主副本分配连续的序列号来确定最终的写入顺序。 - 主副本转发写请求到所有次副本,次副本按主副本安排的顺序执行写入操作。
- 次副本写完后向主副本应答确认操作完成。
- 最后主副本应答客户端,若任意副本写入过程中出现错误,将报告给客户端,由客户端发起重试。
GFS 和 HDFS 的写入流程都采用了流水线方式,但 HDFS 没有分离数据流和控制流。
HDFS 的数据流水线写入在网络上的传输顺序与最终写入文件的顺序一致。
而 GFS 数据在网络上的传输顺序与最终写入文件的顺序可能不一致。
GFS 在支持并发写入和优化网络数据传输方面做出了最佳的折衷。
首先,有一点要确认的是,作为GFS的一个最重要的实现,HDFS设计目标和GFS是高度一致的。在架构、块大小、元数据等的实现上,HDFS与GFS大致一致。但是,在某些地方,HDFS与GFS又有些不同。如: 1、 快照(Snapshot): GFS中的快照功能是非常强大的,可以非常快的对文件或者目录进行拷贝,并且不影响当前操作(读/写/复制)。GFS中生成快照的方式叫copy-on-write。也就是说,文件的备份在某些时候只是将快照文件指向原chunk,增加对chunk的引用计数而已,等到chunk上进行了写操作时,Chunk Server才会拷贝chunk块,后续的修改操作落到新生成的chunk上。 而HDFS暂时并不支持快照功能,而是运用最基础的复制来完成。想象一下,当HBase上的数据在进行重新划分时(过程类似于hash平衡),HDFS需要对其中的所有数据(P/T级的)进行复制迁移,而GFS只需要快照,多不方便! 2、 记录追加操作(append): 在数据一致性方面,GFS在理论上相对HDFS更加完善。 a) GFS提供了一个相对宽松的一致性模型。GFS同时支持写和记录追加操作。写操作使得我们可以随机写文件。记录追加操作使得并行操作更加安全可靠。 b) HDFS对于写操作的数据流和GFS的功能一样。但是,HDFS并不支持记录追加和并行写操作。NameNode用INodeFileUnderConstruction属性标记正在进行操作的文件块,而不关注是读还是写。DataNode甚至看不到租约!一个文件一旦创建、写入、关闭之后就不需要修改了。这样的简单模型适合于Map/Reduce编程。 3、 垃圾回收(GC): a) GFS垃圾回收采用惰性回收策略,即master并不会立即回收程序所删除的文件资源。 GFS选择以一种特定的形式标记删除文件(通常是将文件名改为一个包含时间信息的隐藏名字),这样的文件不再被普通用户所访问。Master会定期对文件的命名空间进行检查,并删除一段时间前的隐藏文件(默认3天)。 b) HDFS并没有采用这样的垃圾回收机制,而是采取了一种更加简单但是更容易实现的直接删除方式。 c) 应该说延迟回收和直接删除各有优势。延迟回收为那些“不小心“的删除操作留了后路。同时,回收资源的具体操作时在Master结点空闲时候完成,对GFS的性能有很好的提高。但是延迟回收会占用很大的存储空间,假如某些可恶的用户无聊了一直创建删除文件怎么办? 试分析下这种不同。有人说,GFS在功能上非常完善,非常强大,而HDFS在策略上较之简单些,主要是为了有利于实现。但实际上,GFS作为存储平台早已经被广泛的部署在Google内部,存储Google服务产生或者要处理的数据,同时用于大规模数据集的研究与开发工作。因此GFS并不仅仅是理论上的研究,而是具体实现。作为GFS的后辈与开源实现,HDFS在技术上应该是更加成熟的,不可能为了“偷懒”而简化功能。因此,简化说应该是不成立的。 个人认为,GFS与HDFS的不同是由于“专”与“通”的区别。众所周知,Hadoop是一个开源软件/框架,在设计之初就考虑到了用户(面向世界上的所有个人、企业)在需求上的差异,比如数据密集型(如淘宝的数据存储)、计算密集型(百度的PR算法)、混合型等等。而GFS在设计之初就对目标比较明确,都是Google的嘛,因此GFS可以对其主要功能进行性能上的优化。