resultMap
·constructor–实例化的时候通过构造器将结果集注入到类中
oidArg– ID 参数; 将结果集标记为ID,以方便全局调用
oarg–注入构造器的结果集
·id–结果集ID,将结果集标记为ID,以方便全局调用
·result–注入一个字段或者javabean属性的结果
·association–复杂类型联合;许多查询结果合成这个类型
o嵌套结果映射– associations能引用自身,或者从其它地方引用
·collection–复杂类型集合
o嵌套结果映射– collections能引用自身,或者从其它地方引用
·discriminator–使用一个结果值以决定使用哪个resultMap
ocase–基于不同值的结果映射
§嵌套结果映射–case也能引用它自身, 所以也能包含这些同样的元素。它也可以从外部引用resultMap
è最佳实践:逐步地生成resultMap,单元测试对此非常有帮助。如果您尝试一下子就生成像上面这样巨大的resultMap,可能会出错,并且工作起来非常吃力。从简单地开始,再一步步地扩展,并且进行单元测试。使用框架开发有一个缺点,它们有时像是一个黑合。为了确保达到您所预想的行为,最好的方式就是进行单元测试。这对提交bugs 也非常有用。
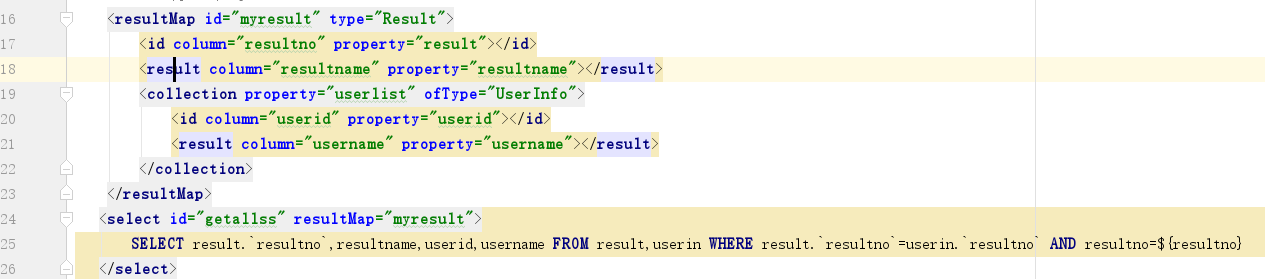
result属性如下:
|
Attribute |
Description |
|
property |
映射数据库列的字段或属性。如果JavaBean 的属性与给定的名称匹配,就会使用匹配的名字。否则,MyBatis 将搜索给定名称的字段。两种情况下您都可以使用逗点的属性形式。比如,您可以映射到“username”,也可以映射到“address.street.number”。 |
|
column |
数据库的列名或者列标签别名。与传递给resultSet.getString(columnName)的参数名称相同。 |
|
javaType |
完整java类名或别名(参考上面的内置别名列表)。如果映射到一个JavaBean,那MyBatis 通常会自行检测到。然而,如果映射到一个HashMap,那您应该明确指定javaType 来确保所需行为。 |
|
jdbcType |
这张表下面支持的JDBC类型列表列出的JDBC类型。这个属性只在insert,update或delete 的时候针对允许空的列有用。JDBC 需要这项,但MyBatis 不需要。如果您直接编写JDBC代码,在允许为空值的情况下需要指定这个类型。 |
|
typeHandler |
我们已经在文档中讨论过默认类型处理器。使用这个属性可以重写默认类型处理器。它的值可以是一个TypeHandler实现的完整类名,也可以是一个类型别名。 |
Mybatis缓存(Cache元素)
MyBatis包含一个强大的、可配置、可定制的查询缓存机制。MyBatis 3 的缓存实现有了许多改进,使它更强大更容易配置。默认的情况,缓存是没有开启,除了会话缓存以外,它可以提高性能,且能解决循环依赖。开启二级缓存,您只需要在SQL映射文件中加入简单的一行:
<cache/>
这句简单的语句作用如下:
·所有映射文件里的select语句的结果都会被缓存。
·所有映射文件里的insert、update和delete语句执行都会清空缓存。
·缓存使用最近最少使用算法(LRU)来回收。
·缓存不会被设定的时间所清空。
·每个缓存可以存储1024 个列表或对象的引用(不管查询方法返回的是什么)。
·缓存将作为“读/写”缓存,意味着检索的对象不是共享的且可以被调用者安全地修改,而不会被其它调用者或者线程干扰。
所有这些特性都可以通过cache元素进行修改。例如:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
这种高级的配置创建一个每60秒刷新一次的FIFO 缓存,存储512个结果对象或列表的引用,并且返回的对象是只读的。因此在不用的线程里的调用者修改它们可能会引用冲突。
可用的回收算法如下:
·LRU–最近最少使用:移出最近最长时间内都没有被使用的对象。
·FIFO–先进先出:移除最先进入缓存的对象。
·SOFT–软引用: 基于垃圾回收机制和软引用规则来移除对象(空间内存不足时才进行回收)。
·WEAK–弱引用:基于垃圾回收机制和弱引用规则(垃圾回收器扫描到时即进行回收)。
默认使用LRU。
flushInterval:设置任何正整数,代表一个以毫秒为单位的合理时间。默认是没有设置,因此没有刷新间隔时间被使用,在语句每次调用时才进行刷新。
Size:属性可以设置为一个正整数,您需要留意您要缓存对象的大小和环境中可用的内存空间。默认是1024。
readOnly:属性可以被设置为true 或false。只读缓存将对所有调用者返回同一个实例。因此这些对象都不能被修改,这可以极大的提高性能。可写的缓存将通过序列化来返回一个缓存对象的拷贝。这会比较慢,但是比较安全。所以默认值是false。