纯真IP库 数据多,更新及时,很多同学在用,网上关于其读取的帖子也有不少(当然其中有一些是有BUG的),但却很少有关于其写入的帖子。OK,下面分享下写QQWry.dat。
QQWry.dat 分三个部分 :文件头,记录区,索引区。

一:首先写文件头,文件头的内容只有8个字节,首四个字节是第一条索引的绝对偏移,后四个字节是最后一条索引的绝对偏移。但是一开始我们还不知道这两个偏移量,那么就先随便写点啥,占个位吧,等后面索引写完了再回来修改。
 View Code
View Code

string path = HttpContext.Current.Server.MapPath("~/App_Data/QQWry.dat"); FileStream fs = new FileStream(path, FileMode.Create, FileAccess.ReadWrite); long firstIPIndexOffset = 0; //第一条索引的绝对偏移量 long lastIPIndexOffset = 0; //最后一条索引的绝对偏移量 byte[] head = new byte[8] { 0, 0, 0, 0, 0, 0, 0, 0 }; fs.Write(head, 0, head.Length);
二:写记录区
记录区的写入最复杂,分析QQwry.dat的数据我们可以很容易发现,一个“国家”下面有N多个“地址”,一个“地址”下面有N多个IP段。很明显这个有三个对象,并且层级关系。
View Code
public class IPEntity { public string StartIP { get; set; } public string EndIP { get; set; } /// <summary> /// 该IP记录在文件中的绝对偏移量 /// </summary> public long Offset { get; set; } } public class AdressEntity { public AdressEntity() { IPS = new List<IPEntity>(); } public string Address { get; set; } public List<IPEntity> IPS { get; set; } } public class CountryEntity { public CountryEntity() { Addrs = new List<AdressEntity>(); } public string Country { get; set; } public List<AdressEntity> Addrs { get; set; } }
记录区的数据格式不定,数据主要有以下类型:
A:结束IP(4个字节)
B:国家记录 (以0x 00结束,不定长 )
C: 地区记录 (以0x 00结束 ,不定长)
D:重定向模式标记(1或者2,1个字节)
E:绝对偏移量(3个字节)
每条记录的组成结构可能有三种情况:
第一种(最简单): [结束IP][国家]0[地址]0

View Code
//写国家 byte[] byCountry = System.Text.Encoding.GetEncoding("GB2312").GetBytes(country); fs.Write(byCountry, 0, byCountry.Length); fs.WriteByte(0); //写地址 byte[] byAdress = System.Text.Encoding.GetEncoding("GB2312").GetBytes(addr); fs.Write(byAdress, 0, byAdress.Length); fs.WriteByte(0);
使用场景:在该记录所对应的“国家”和“地址”之前都没有写入时。
读取时,找到这条记录的位置依次读下去就OK了
第二种:[结束IP]1[绝对偏移量]

View Code
fs.WriteByte(1); byte[] byOffset = BitConverter.GetBytes((data[i].Addrs[j].IPS[0].Offset + 4)); fs.Write(byOffset, 0, 3);
使用场景:在该记录所对应的“国家”和“地址”之前都已经写入过。
读取时根据绝对偏移量跳转到指定位置,(可能会跳转两次,因为可能跳到的下一个位置是重定向模式2)然后就和第一种情况类似。
第三种:[结束IP]2[绝对偏移量][地址]0
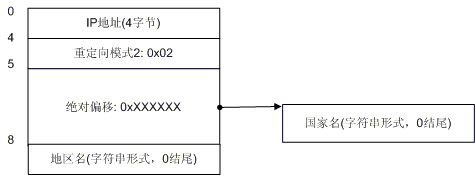
View Code
fs.WriteByte(2); byte[] byOffset = BitConverter.GetBytes((data[i].Addrs[0].IPS[0].Offset + 4)); fs.Write(byOffset, 0, 3); //写地址 byte[] byAdress = System.Text.Encoding.GetEncoding("GB2312").GetBytes(addr); fs.Write(byAdress, 0, byAdress.Length); fs.WriteByte(0);
使用场景:在该记录之前“国家”已经出现,但“地址”没有出现过。
读取时先按指定偏移跳转到指定位置读取到“国家”,然后读取该记录本身后面的“地址”
其就是为了使字符串尽量重用,同一个国家名称只写入一次,同一个地址名称也只写入一次
三:写索引区
索引区的结构:[起始IP][绝对偏移量]
其实在写记录区的时候需要把每条IP记录的绝对偏移量记下来。
写入索引时需要记录第一条索引和最后一条索引的绝对偏移量,用来更新前面提到的文件头。
写索引时必须将IP从小到大顺序写入,或者说我们提供数据源是按照IP从小到大的顺序排列的,这样我们在查找时才能使用二分法查找。
下面看一个完整的代码段:
public class IPEntity { public string StartIP { get; set; } public string EndIP { get; set; } public long Offset { get; set; } } public class AdressEntity { public AdressEntity() { IPS = new List<IPEntity>(); } public string Address { get; set; } public List<IPEntity> IPS { get; set; } } public class CountryEntity { public CountryEntity() { Addrs = new List<AdressEntity>(); } public string Country { get; set; } public List<AdressEntity> Addrs { get; set; } } public class QQWryWriter { /// <summary> /// 写文件 /// </summary> /// <param name="data">数据源,这个要事先准备好</param> public void Write(List<CountryEntity> data) { string path = HttpContext.Current.Server.MapPath("~/App_Data/QQWry.dat"); using (FileStream fs = new FileStream(path, FileMode.Create, FileAccess.ReadWrite)) { #region 写文件头 //文件头,8个字节。暂时都为0,先占个位,预留着,等索引全部写好了,再回过头来修改。 long firstIPIndexOffset = 0; //第一条索引的绝对偏移量 long lastIPIndexOffset = 0; //最后一条索引的绝对偏移量 byte[] head = new byte[8] { 0, 0, 0, 0, 0, 0, 0, 0 }; fs.Write(head, 0, head.Length); #endregion #region 写记录区 //每条记录的组成结构有三种:[结束IP][重定向模式标记][国家][地址] //第一种(最简单): [结束IP][国家]0[地址]0 //第二种: [结束IP]1[绝对偏移量] //第三种: [结束IP]2[绝对偏移量][地址]0 //其就是为了使字符串尽量重用,同一个国家名称只写入一次,同一个地址名称也只写入一次 for (int i = 0; i < data.Count; i++) { string country = data[i].Country;//国家名 for (int j = 0; j < data[i].Addrs.Count; j++) { string addr = data[i].Addrs[j].Address;//地址名 for (int k = 0; k < data[i].Addrs[j].IPS.Count; k++) { var ipEntity = data[i].Addrs[j].IPS[k]; //记下IP记录的绝对偏移,方便后面索引区的写入 ipEntity.Offset = fs.Position; //写结束IP long intEndIP = IpToInt(ipEntity.EndIP); byte[] byEndIP = BitConverter.GetBytes(intEndIP); fs.Write(byEndIP, 0, 4); //重定向模式1 if (k > 0) { fs.WriteByte(1); byte[] byOffset = BitConverter.GetBytes((data[i].Addrs[j].IPS[0].Offset + 4)); fs.Write(byOffset, 0, 3); } else { //第一条记录肯定是最简单的,直接以第一种结构写入。 if (j == 0) { //写国家 byte[] byCountry = System.Text.Encoding.GetEncoding("GB2312").GetBytes(country); fs.Write(byCountry, 0, byCountry.Length); fs.WriteByte(0); //写地址 byte[] byAdress = System.Text.Encoding.GetEncoding("GB2312").GetBytes(addr); fs.Write(byAdress, 0, byAdress.Length); fs.WriteByte(0); } //重定向模式2 else { fs.WriteByte(2); byte[] byOffset = BitConverter.GetBytes((data[i].Addrs[0].IPS[0].Offset + 4)); fs.Write(byOffset, 0, 3); //写地址 byte[] byAdress = System.Text.Encoding.GetEncoding("GB2312").GetBytes(addr); fs.Write(byAdress, 0, byAdress.Length); fs.WriteByte(0); } } } } } #endregion #region 写索引区 for (int i = 0; i < data.Count; i++) { for (int j = 0; j < data[i].Addrs.Count; j++) { for (int k = 0; k < data[i].Addrs[j].IPS.Count; k++) { var ipEntity = data[i].Addrs[j].IPS[k]; long intStartIP = IpToInt(ipEntity.StartIP); if (i == 0 && j == 0 && k == 0) { firstIPIndexOffset = fs.Position; } if (i == data.Count - 1 && j == data[i].Addrs.Count - 1 && k == data[i].Addrs[j].IPS.Count - 1) { lastIPIndexOffset = fs.Position; } byte[] byStartIP = BitConverter.GetBytes(intStartIP); fs.Write(byStartIP, 0, 4); byte[] byOffset = BitConverter.GetBytes(ipEntity.Offset); fs.Write(byOffset, 0, 3); } } } #endregion #region 更新文件头 fs.Position = 0; byte[] byFirstIPIndexOffset = BitConverter.GetBytes(firstIPIndexOffset); fs.Write(byFirstIPIndexOffset, 0, 4); fs.Position = 4; byte[] bylastIPIndexOffset = BitConverter.GetBytes(lastIPIndexOffset); fs.Write(bylastIPIndexOffset, 0, 4); #endregion fs.Flush(); fs.Close(); } } /// <summary> /// IP地址转换成Int数据 /// </summary> /// <param name="ip"></param> /// <returns></returns> private long IpToInt(string ip) { char[] dot = new char[] { '.' }; string[] ipArr = ip.Split(dot); if (ipArr.Length == 3) ip = ip + ".0"; ipArr = ip.Split(dot); long ip_Int = 0; long p1 = long.Parse(ipArr[0]) * 256 * 256 * 256; long p2 = long.Parse(ipArr[1]) * 256 * 256; long p3 = long.Parse(ipArr[2]) * 256; long p4 = long.Parse(ipArr[3]); ip_Int = p1 + p2 + p3 + p4; return ip_Int; } }
科普一下:
.Net中的各种流Stream、FileStream、xxxStream 都是字节数组,每个字节中存储的都是0~255 之间的无符号数(即非负整数) 。
1个字节(Byte)==8个二进制位(Bit),所以1个Byte能存储的最大无符号数为2^8-1=255 。
现在你应该能彻底理解一个IP为什么需要4个字节来存储了。
原文地址:http://www.cnblogs.com/xumingxiang/archive/2013/02/17/2914524.html
出处:http://www.cnblogs.com/xumingxiang
版权:本文版权归作者和博客园共有
转载:欢迎转载,为了保存作者的创作热情,请按要求【转载】,谢谢
要求:未经作者同意,必须保留此段声明;必须在文章中给出原文连接;否则必究法律责任