MHA概念

如果MHA部署在一台Slave上,那么它就只能管理一个主从复制结构 MHA为什么不能部署在master上? 本身是防的是主库宕机,如果网络出问题,那么MHA也会失效。 完全透明指的是:整个过程MHA日志中会记录的非常详细,方便运维来排查错误。
工作流程(原理)
从宕机崩溃的master保存的二进制日志文件(binlog events) 识别含有最新更新的slave 应用差异的中继日志(relay log)到其他的slave 应用从master保存的二进制日志实践(binlog events) 提升一个slave为新的master 使其他的slave连接新的master进行复制 原理简单来讲 (1)复制主库binlog日志出来 (2)找出relaylog日志中最全的从库 (3)将最全的relaylog日志所在的所有从库中同步(第一次同步) (4)将之前最全的那个从库提升为主库 (5)将复制出来的binlog日志,放到新提升的主库里 (6)其他所有从库重新只向新提升的主库,继续主从复制 知识点: 1.谁的relay log中的内容最多,说明谁的主从复制最快
MHA工具介绍
masterha_check_ssh:检查ssh连接的一个脚本,MHA要想管理,就必须能ssh到任何一个节点上,如果 连不上,MHA是做不到管理的 masterha_check_repl:检查主从复制,检测谁是主谁是从,有几个架构,能不能完成替换工作(替换就 是双主架构,检查从库上有没有开启binlog日志及配置文件中还要加一个东西(从库是不是也能当成主 库)。因为它要把从替换为主

环境准备
1.三台6.5版本的linux系统,并且都装有mysql(不能是克隆的),给root设置mysql密码
mysql的二进制安装
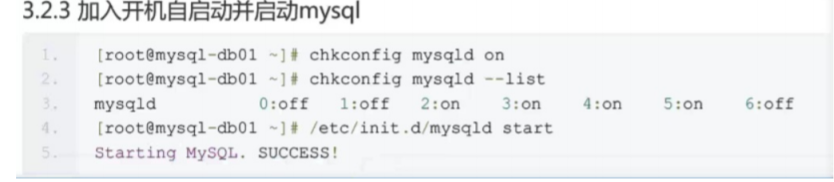
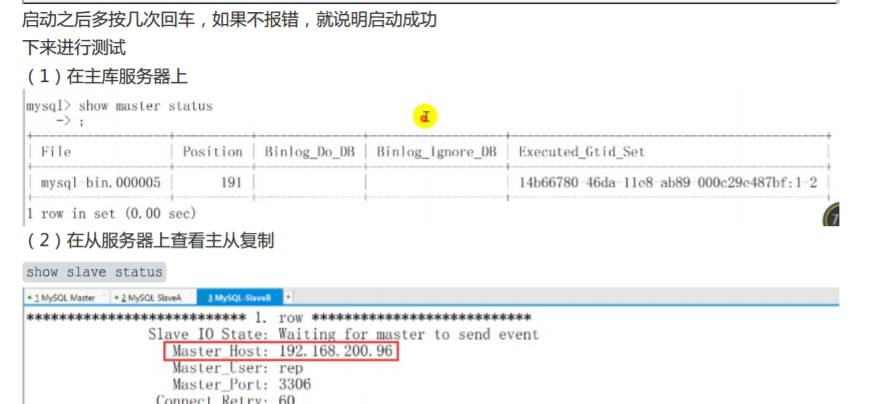
配置基于GTID的主从复制
mysql5.6版本和之前同步,不再需要告诉它从哪开始同步(相当于在从 上同步不再需要告诉它从哪个日志的哪个位置开始) 特性: (1)支持多线程复制(每个库有一个单独的sql线程) (2)支持启用GTID,在主从复制中,它会自动去找binlog和位置 (3)支持延迟复制 但是有时候打开GTID反倒麻烦 因为GTID一旦打开就控制不了它的同步进程。要想重新控制,必须先关闭GTID。所以,一旦同步出现问 题,要先关闭GTID然后进行调整。 一.要想做MHA主库和从库的先决条件 (1) 主库从库都必须开启binlog日志 (2)都要有主从复制账号(账号系统必须一致) (3)server-id不能一致
主库的配置
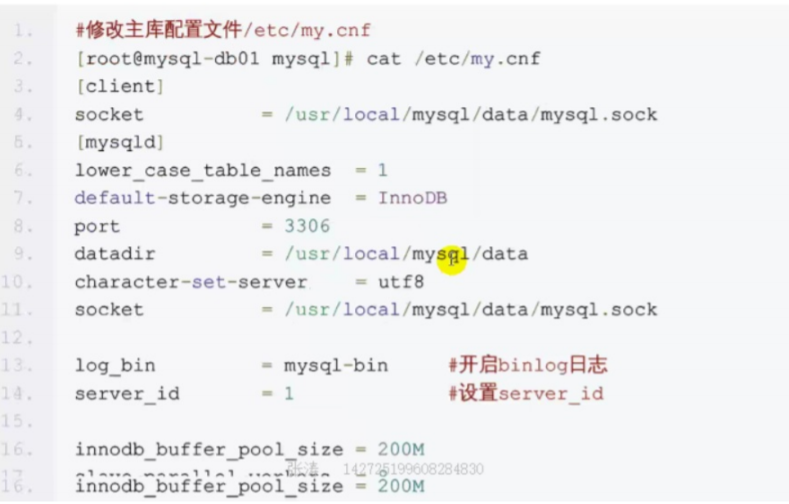
重启MYSQL服务
创建主从复制账号:

从库配置
1.修改配置文件(server-id不能一样,其它都一样),完了重启mysql服务
2查看从库gtid
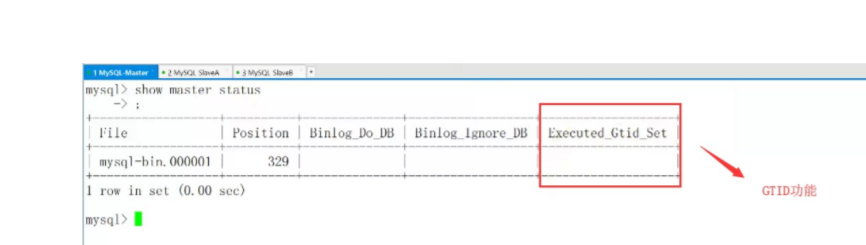

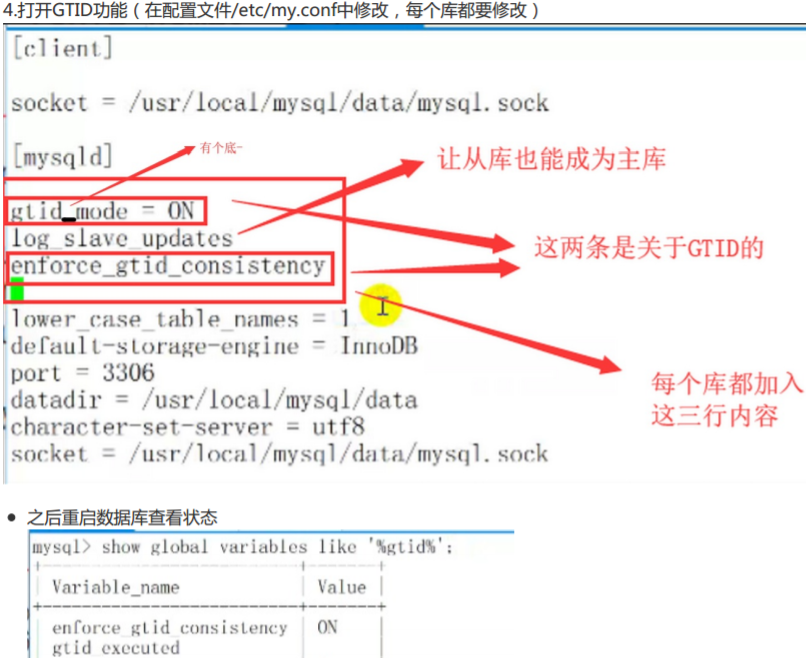
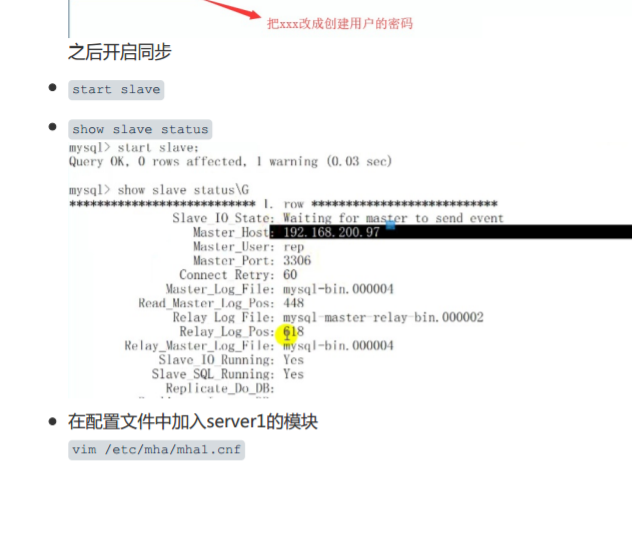
配置主从复制(在从库上)

.mysql配置文件(禁止mysql自动删除relaylog。每个从库都得有,主库也必须有) 为什么要禁止mysql自动删除中继日志?怎样设置?MHA要用到relaylog,但是relaylog要占空间,这 样的话,长此以往从库的空间不久不够用了,这种情况怎么解决? mysql有个机制是自动删时要用到relaylog,所以要把它设置成不能让它自 己删,而要把删中继日志的功能交给MHA。 永久禁止mysql自动清除relaylog
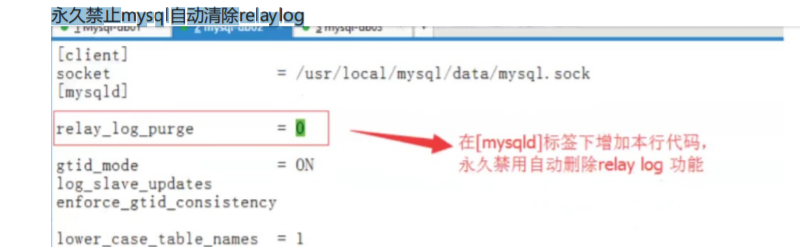
重启Mysql服务
六.部署MHA
1.安装依赖包(所有库上) 节点包(每个库上都得安装节点包)
先安装依赖包


接下来在主库上给mha创建管理账号。因为开启了主从复制,所以主库上建立。从库也会有

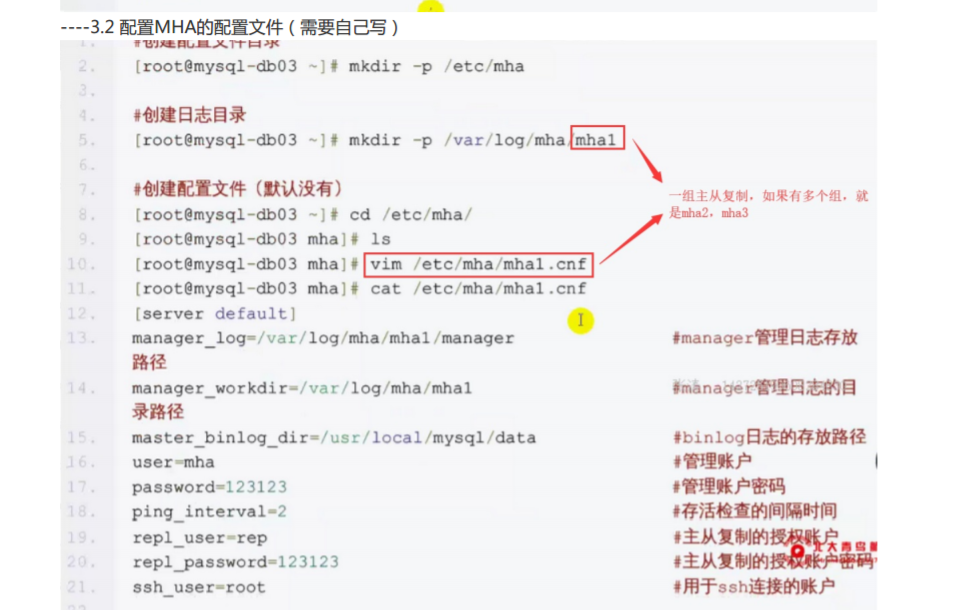
部署管理节点(mha-manager) ------3.1 在其中的一个从库上,或者其他服务器,不能在主库上
需要公网源安装,首先安装依赖包
安装完依赖包以后安装管理包

接下来是mha的配置
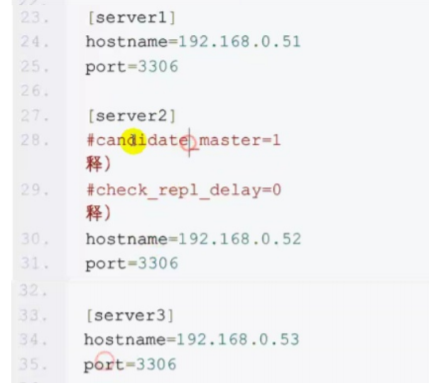

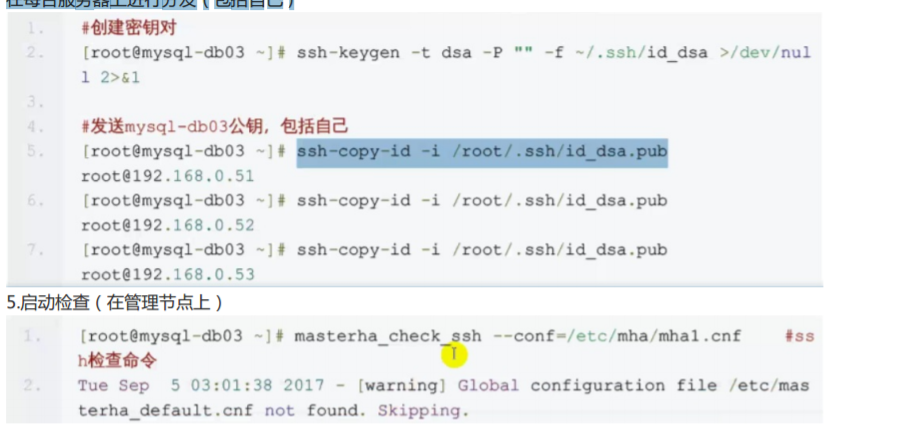
配置ssh信任(就是免密钥,在所有节点上配置) 在免密钥时,还得自己发自己 在每台服务器上进行分发(包括自己)

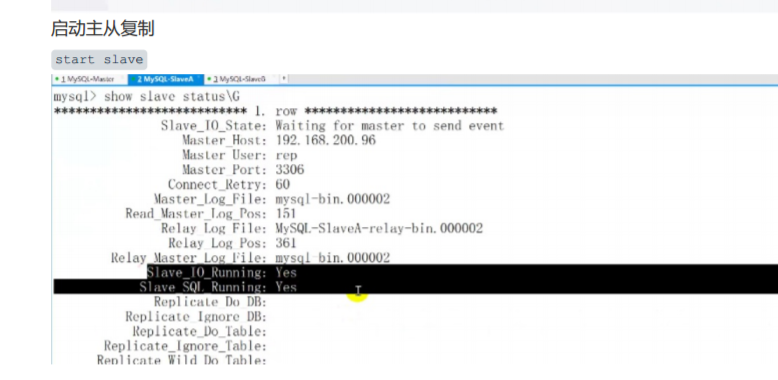
七.启动MHA
nohup masterha_manager --conf=/etc/mha/mha1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log
此时关闭主库。再取看从库,可以自由切换了
在进行切换的时候nohup进程掉线,需要手动再次启动nohup进程。(mha进程只能完成一次切换,之后 它就会宕掉,但我们也只需要一次切换就行)

杀掉mha的nohup进程。重新启动nohup进程(多按几次回车进行确定),至此恢复完成 nohup masterha_manager --conf=/etc/mha/mha1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var
虽然MHA搭建完成,但是存在问题 1.如果主库服务器宕机,那么是怎么把binlog日志复制出来的 2.从从库切换为主库,IP地址发生改变,但是开发人员是不知道的,那么怎么让它切换以后IP地址不发生改变(使用 VIP) MHA两个重要的参数 如果MHA安装在从库上,那么就得用参数告诉主库不能把这个从库切换为主库,因为如果带有MHA的 从库切换为主,要是宕机那么MHA也会宕,因此就不能去完成切换。

1.怎么在切换的时候不更改IP地址,怎么使用VIP? 通过IP漂移,IP漂移两种方式:
(1) 通过keepalived的方式管理虚拟IP的漂移
(2) 通过MHA自带脚本方式,管理虚拟IP的漂移
本身manager自带脚本,但是多数用不了
cp master_ip_failover /usr/local/bin/
chmod +x /usr/local/bin/master_ip_failover
(2)需要修改脚本 vim /usr/local/bin/master_ip_failover
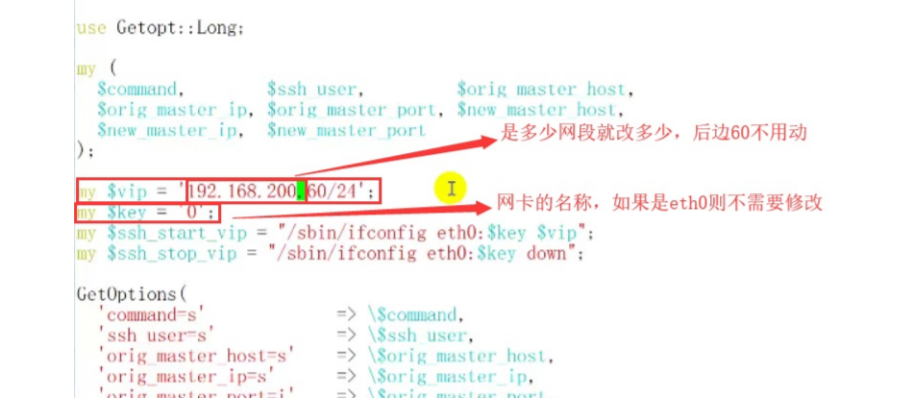
杀死mha服务之后重启服务
2.如果主库的服务宕了,从库可以把binlog日志拿过来,但是如果主库服务器宕机,那么从 库是怎么把binlog日志拿过来的? 那么就要在它宕机之前把binlog日志拿过来。所以就需要binlog-server备份服务器(可以做在从库上,不用过于安 全)
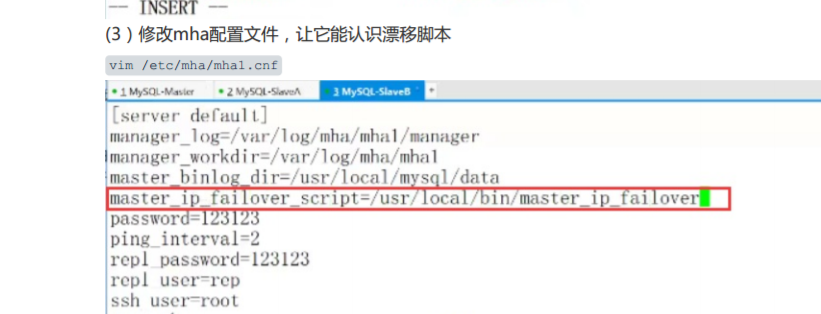
(1).先要修改MHA配置文件

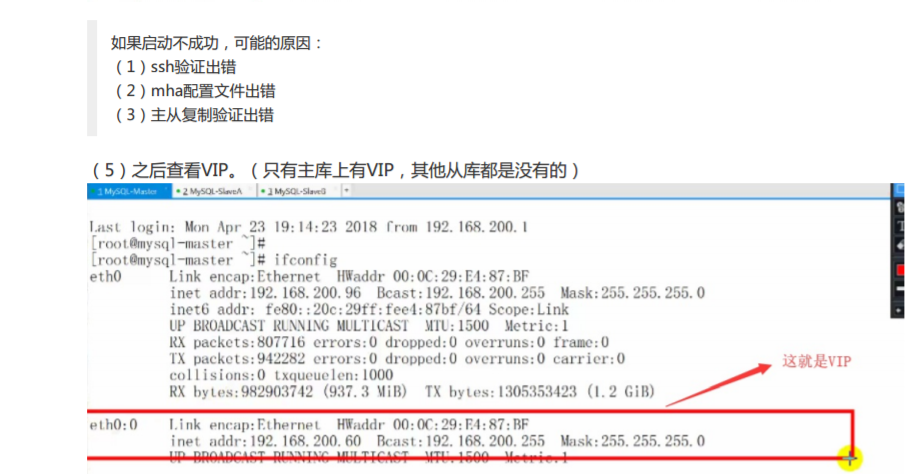
(3)杀掉mha进程,重新启动 这个时候重新启动mha进程,它就检测好几个东西 (1)检测ssh (2)检测主从复制 (3)检查配置文件 (4)检测有没有开启拉日志的进程
pkill perl
nohup masterha_manager --conf=/etc/mha/mha1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var