一、可迭代对象,迭代器对象和生成器
像list,tuple等这些序列是可以使用for...in...语句进行遍历输出的。这是为什么呢?这就要需要知道可迭代对象(Iterable),迭代器对象(Iterator)和生成器对象(Genertor)。
1、什么是可迭代对象?
把可以通过for...in...这类语句迭代读取一条数据提供我们使用的对象。
2、可迭代对象的本质?
可迭代对象通过__iter__方法向我们提供一个迭代器,我们在迭代一个可迭代对象的时候,实际上就是先获得该对象提供的一个迭代器,然后通过这个迭代器来依次获取对象中的每一个数据。
也就是说可迭代对象必须要有 __iter__()方法
3、iter()函数和next()函数的作用是什么?
通过iter()函数获取可迭代对象的迭代器
然后我们可以对获取到的迭代器不断使用next()函数来获取下一条数据。当我们已经迭代完最后一个数据之后,再次调用next()函数会抛出Stoplteration异常
来告诉我们所有的数据都已经迭代完成,不用再执行mext()函数了
4、什么是迭代对象?
一个实现了 __iter__ 方法和 __next__ 方法的对象,就是迭代器
5、什么是生成器?
简单来说:只要在def中有yield关键字的,就是生成器
6、yield的作用是什么?
yield关键字有两点作用:
(1)保存当前运行状态(断点),然后暂停执行,即将生成器(函数)挂起
(2)将yield关键字后面表达式的值作为返回值返回,此时可以理解为起到了return作用
Python2x中的原生协成就是使用yield关键字,但在Python3x中使用的是yield from
7、如何启动生成器?
send():除了能唤醒生成器外,还可以给生成器传值
next():单纯的获取生成器的一个值
二、GIL
前言:了解Python的都知道,在Python中多线程并不是真正意义上的多线程。那为什么在Python中多线程的威力没有像其他语言哪有强大呢?
1、GIL全程是全局解释器锁,保证了同一时刻只有一个线程在执行。
2、作用:在单核的情况下实现多任务!这在当时是非常厉害的技术
3、产生问题的原因:一个CPU分配给一个进程,进程的线程是使用GIL进行资源抢夺。在多核情况下,会使其他核空闲,CPU利用率不高。
4、解决方案:
(1)使用其他解释器,如JPython(但是太慢,不好)。因为只有在CPython中才存在GIL
(2)使用其他语言(c/java)来写多线程这部分代码
(3)使用多进程+协成的方式(重点推荐)
三、浅拷贝和深拷贝
深拷贝:它是一种递归的方式拷贝某个对象,单独形成一个新对象。这种方式很浪费资源。
浅拷贝:它只复制一层信息,占用的资源少!而且大部分的形式都是浅拷贝。
四、面向对象总结
1、私有化
(1)x:公有变量
(2)_x:单个前置下划线,私有化方法或属性,from some_modue import * 是不能导入的,只有类和对象可以访问。
(3)__x:双前置下划线,避免与子类中的属性命名冲突,外部无法访问,但是可以通过特殊的方法访问到(obj._类名__xx)
(4)__x__:双前后下划线,用户命名空间的魔法方法后的属性。最好不要用
(5)x_:单后置下划线,用于避免与Python关键字冲突。
2、封装
一个功能一个函数,把相关函数封装成一个类对象。好处是代码可以复用。
3、继承:
多个子类拥有相同的功能,然后把相同的函数放到父类中,通过子类的方式继承下来。
4、多态:
(1)必须要有继承
(2)不同对象调用同一个函数,会用不同的表现形式
(3)Python中的多态并不是严谨的多态,因为没有做类型检查。
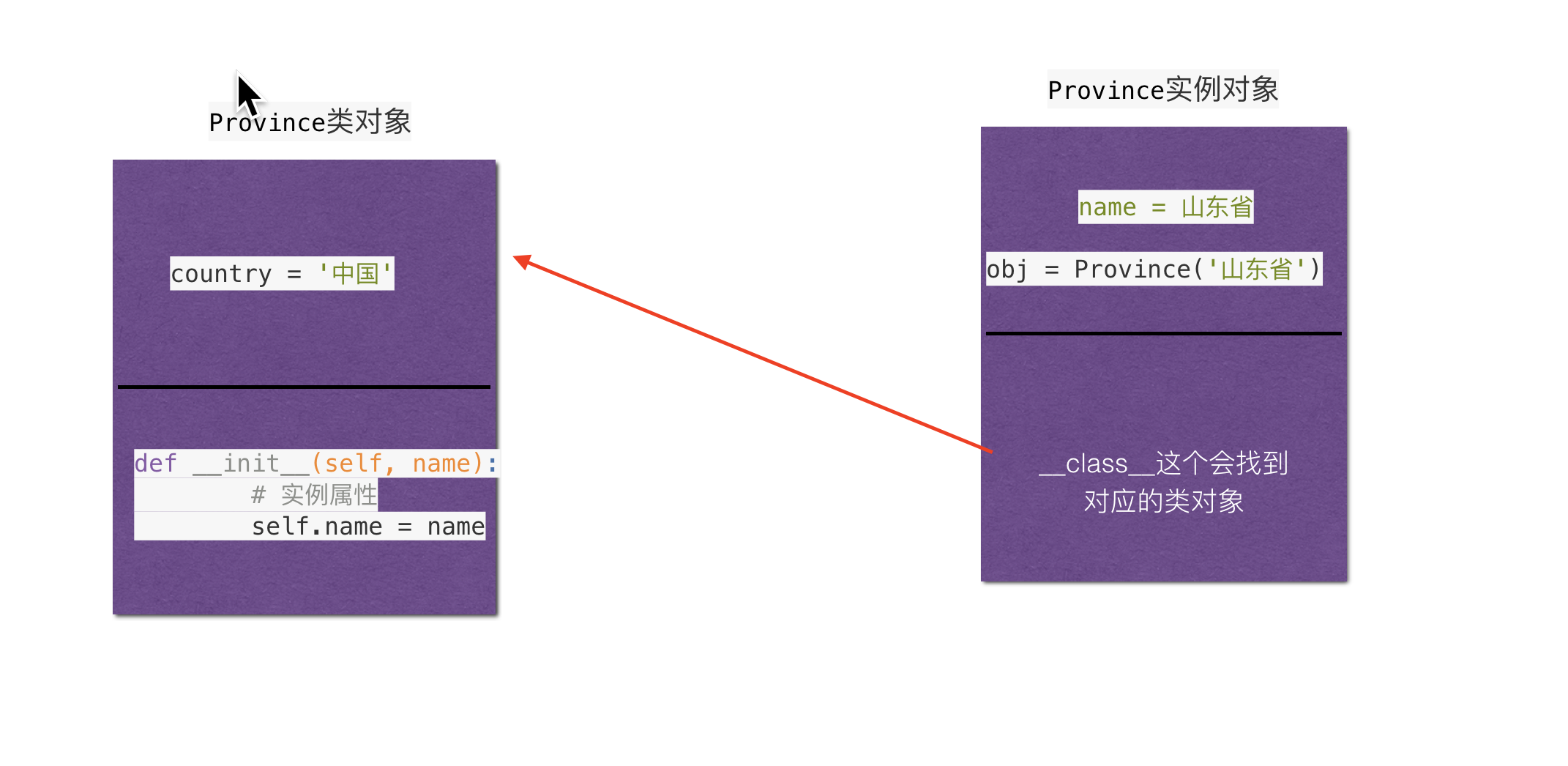
5、类与实例对象之间的关系:
6、面向函数编程和面向对象编程
面向函数编程:一个功能一个函数
面向对象编程:把相关函数封装成一个类对象
五、模块导入与路径搜索
1、动态导入:
(1)import module;
(2) __import__("some_module")
这两种方式是一样的
2、路径搜索:
在导入某一个模块时,会在sys.path()中搜索目标模块。如果找到了,那么就停止搜索,否则一直找到最后。
3、重新加载模块
from imp import reload , reload 函数的好处是当导入的某个模块做了修改时,又不想通过关机开重新导入,而是进行热更新,就能获取到修改后的值
六、类中方法总结
1、魔法方法
(1)__init__ :用于初始化对象
(2)__new__:用于创建对象
(3)__call__ :使对象变的可调用
(4)__dict__ :把类中的属性组成一个字典,属性名作为key,属性值作为value
(5)__class__:用于查看对象是由那个类创建的
2、super():
当有多个类发生继承关系时,Python内部会维护着一张继承表(通过__mro__可以查看)super()在当前继承表中找到自己的位置,然后执行下一个类的__init__方法。
七、上下文管理器(ContextManager)
在很多时候,我们都会看到with open(filename, 'w') as f : pass ,这种操作文件的方式。这种操作的好处就是我们不需要手动调用f.close()来关闭我们打开的文件。
任何一个上下文管理器对象都可以使用with关键字来操作。
只要实现了 __enter__()和__exit__()方法的类就是上下文管理器
__enter__():返回资源对象
__exit__():在出差完成之后,进行清除工作。如关闭文件
连接数据库的上下文管理器:
第一种方式:
from pymysql import connect class DBHelper: def __init__(self): self.conn = connect(host='localhost', port=3306, user='user', password='password', databases='database', charset='utf8') self.csr = self.conn.cursor() def __enter__(self): return self.csr def __exit__(self, exc_type, exc_val, exc_tb): self.csr.close() self.conn.close() with DBHelper() as csr: sql = "select * from table;" csr.execute(sql) all_datas = csr.fetchall() for item in all_datas: print(item)
第二种方式
@contextmanager def conn_db(): conn = connect(host='localhost', port=3306, user='user', password='password', database='database', charset='utf8') csr = conn.cursor() yield csr csr.close() conn.close() with conn_db() as csr: sql = "select * from table;" csr.execute(sql) all_datas = csr.fetchall() for item in all_datas: print(item)