前言
这一章节我们将讲解高并发解决方案中的服务降级和服务熔断思路,这里仅提供思路,至于如何具体操作,后续补上。
经历过12306抢票的会遇到这个问题,抢票高峰期查询列表是空的,等高峰期过后,列表再次恢复正常,这是什么问题?这里很可能采用了服务降级。
主体概要
-
服务降级和服务熔断概念
-
服务降级分类
-
服务熔断和服务降级对比
-
服务降级要考虑的问题
-
Hystrix
主体内容
一、服务降级和服务熔断概念
1.服务降级理解
服务压力剧增的时候根据当前的业务情况及流量对一些服务和页面有策略的降级,以此环节服务器的压力,以保证核心任务的进行。同时保证部分甚至大部分任务客户能得到正确的相应。也就是当前的请求处理不了了或者出错了,给一个默认的返回。
2.服务熔断理解
在股票市场,熔断这个词大家都不陌生,是指当股指波幅达到某个点后,交易所为控制风险采取的暂停交易措施。相应的,服务熔断一般是指软件系统中,由于某些原因使得服务出现了过载现象,为防止造成整个系统故障,从而采用的一种保护措施,所以很多地方把熔断亦称为过载保护。
二、服务降级分类
- 降级按照是否自动化可分为:自动开关降级和人工开关降级。
- 降级按照功能可分为:读服务降级、写服务降级。
- 降级按照处于的系统层次可分为:多级降级。
1.自动开关降级分类
(1)超时降级:主要配置好超时时间和超时重试次数和机制,并使用异步机制探测回复情况
(2)失败次数降级:主要是一些不稳定的api,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
(3)故障降级:比如要调用的远程服务挂掉了(网络故障、DNS故障、http服务返回错误的状态码、rpc服务抛出异常),则可以直接降级。降级后的处理方案有:默认值(比如库存服务挂了,返回默认现货)、兜底数据(比如广告挂了,返回提前准备好的一些静态页面)、缓存(之前暂存的一些缓存数据)
(4)限流降级:
当我们去秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时开发者会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)。
2.人工开关降级分类
秒杀、双11大促等...
三、服务熔断和服务降级对比
1.类似点
(1)目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
(2)最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
(3)粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
(4)自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;
2.区别点
(1)触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
(2)管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
(3)实现方式不太一样
四、服务降级要考虑的问题
1.核心和非核心服务
2.是否支持降级,降级策略
3.业务放通的场景,策略
五、Hystrix(防雪崩利器)
接下来我们介绍一个功能强大的类:Hystrix。该库旨在通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Hystrix具备拥有回退机制和断路器功能的线程和信号隔离,请求缓存和请求打包(request collapsing,即自动批处理,译者注),以及监控和配置等功能。
Hystrix被设计的目标是:
- 对通过第三方客户端库访问的依赖项(通常是通过网络)的延迟和故障进行保护和控制。
- 在复杂的分布式系统中阻止级联故障。
- 快速失败,快速恢复。
- 回退,尽可能优雅地降级。
- 启用近实时监控、警报和操作控制。
当一切正常时,请求看起来是这样的:

当其中有一个系统有延迟时,它可能阻塞整个用户请求:

在高流量的情况下,一个后端依赖项的延迟可能导致所有服务器上的所有资源在数秒内饱和(PS:意味着后续再有请求将无法立即提供服务)

Hystrix设计原则
- 防止任何单个依赖项耗尽所有容器(如Tomcat)用户线程。
- 甩掉包袱,快速失败而不是排队。
- 在任何可行的地方提供回退,以保护用户不受失败的影响。
- 使用隔离技术(如隔离板、泳道和断路器模式)来限制任何一个依赖项的影响。
- 通过近实时的度量、监视和警报来优化发现时间。
- 通过配置的低延迟传播来优化恢复时间。
- 支持对Hystrix的大多数方面的动态属性更改,允许使用低延迟反馈循环进行实时操作修改。
- 避免在整个依赖客户端执行中出现故障,而不仅仅是在网络流量中。
Hystrix是如何实现它的目标的
- 用一个HystrixCommand 或者 HystrixObservableCommand (这是命令模式的一个例子)包装所有的对外部系统(或者依赖)的调用,典型地它们在一个单独的线程中执行
- 调用超时时间比你自己定义的阈值要长。有一个默认值,对于大多数的依赖项你是可以自定义超时时间的。
- 为每个依赖项维护一个小的线程池(或信号量);如果线程池满了,那么该依赖性将会立即拒绝请求,而不是排队。
- 调用的结果有这么几种:成功、失败(客户端抛出异常)、超时、拒绝。
- 在一段时间内,如果服务的错误百分比超过了一个阈值,就会触发一个断路器来停止对特定服务的所有请求,无论是手动的还是自动的。
- 当请求失败、被拒绝、超时或短路时,执行回退逻辑。
- 近实时监控指标和配置变化。
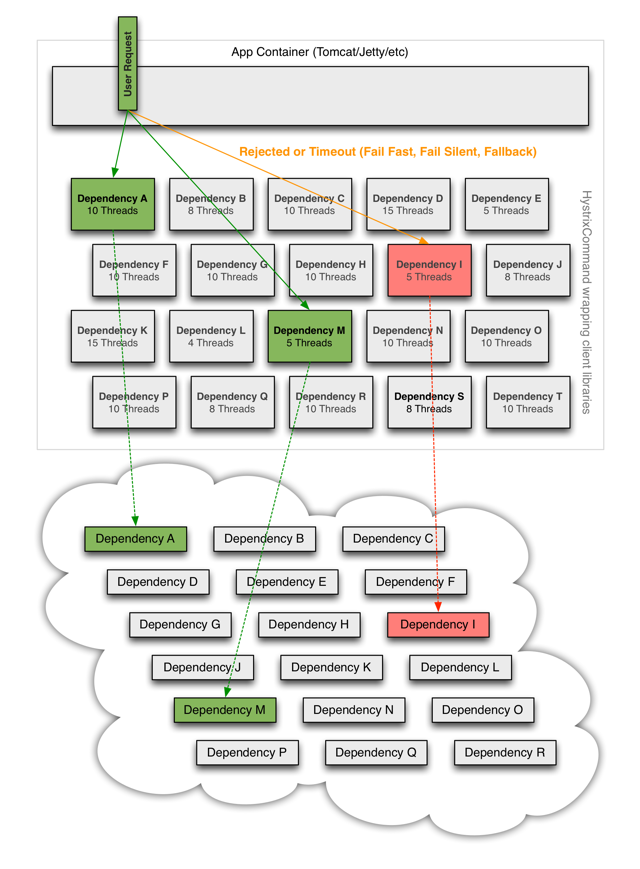
当你使用Hystrix来包装每个依赖项时,上图中所示的架构会发生变化,如下图所示:
每个依赖项相互隔离,当延迟发生时,它会被限制在资源中,并包含回退逻辑,该逻辑决定在依赖项中发生任何类型的故障时应作出何种响应: