参考:
https://blog.csdn.net/revivedsun/article/details/80088080
https://www.h3399.cn/201812/638875.html
https://www.cnblogs.com/gendan5/p/11803838.html
https://my.oschina.net/wstone/blog/2885485
Java 8+ 函数式库Vavr功能简介
1 概述
Vavr 是Java 8+中一个函数式库,提供了一些不可变数据类型及函数式控制结构。
1.1 Maven 依赖
添加依赖,可以到maven仓库中查看最新版本。
<dependency>
<groupId>io.vavr</groupId>
<artifactId>vavr</artifactId>
<version>0.9.0</version>
</dependency>2. Option
Option的作用是消除代码中的null检查。在Vavr中Option是一个对象容器,与Optional类似,有一个最终结果。 Vavr中的Option实现了Serializable, Iterable接口,并且具有更加丰富的API。在Java中,我们通常通过if语句来检查引用是否为null,以此来保证系统健壮与稳定。如果不检查会出现空指针异常。
@Test
public void givenValue_whenNullCheckNeeded_thenCorrect() {
Object object = null;
if (object == null) {
object = "someDefaultValue";
}
assertNotNull(possibleNullObj);
}如果包含较多的if检查,同时带有嵌套语句,那么代码开始变得臃肿。Option通过将null替换为一个有效对象来解决这个问题。使用Option null值会通过None实例来表示,而非null值则是某个具体对象实例。
@Test
public void givenValue_whenCreatesOption_thenCorrect() {
Option<Object> noneOption = Option.of(null);
Option<Object> someOption = Option.of("val");
assertEquals("None", noneOption.toString());
assertEquals("Some(val)", someOption.toString());
}代码中调用toString时,并没有进行检查来处理NullPointerException问题。Option的toString会返回给我们一个有意义的值,这里是 “None”。当值为null时,还可以指定默认值。
@Test
public void givenNull_whenCreatesOption_thenCorrect() {
String name = null;
Option<String> nameOption = Option.of(name);
assertEquals("baeldung", nameOption.getOrElse("baeldung"));
}当为非null时返回值本身。
@Test
public void givenNonNull_whenCreatesOption_thenCorrect() {
String name = "baeldung";
Option<String> nameOption = Option.of(name);
assertEquals("baeldung", nameOption.getOrElse("notbaeldung"));
}这样在处理null相关检查时,只需要写一行代码即可。
3. 元组Tuple
Java中没有与元组(Tuple)相对应的结构。Tuple是函数式编程中一种常见的概念。Tuple是一个不可变,并且能够以类型安全的形式保存多个不同类型的对象。Tuple中最多只能有8个元素。
public void whenCreatesTuple_thenCorrect1() {
Tuple2<String, Integer> java8 = Tuple.of("Java", 8);
String element1 = java8._1;
int element2 = java8._2();
assertEquals("Java", element1);
assertEquals(8, element2);
}引用元素时从1开始,而不是0。
Tuple中的元素必须是所声明的类型。
@Test
public void whenCreatesTuple_thenCorrect2() {
Tuple3<String, Integer, Double> java8 = Tuple.of("Java", 8, 1.8);
String element1 = java8._1;
int element2 = java8._2();
double element3 = java8._3();
assertEquals("Java", element1);
assertEquals(8, element2);
assertEquals(1.8, element3, 0.1);
}当需要返回多个对象时可以考虑使用Tuple。
4. Try
在Vavr, Try是一个容器,来包装一段可能产生异常的代码。Option用来包装可能产生null的对象,而Try用来包装可能产生异常的代码块,这样就不用显式的通过try-catch来处理异常。下面的代码用来检查是否产生了异常。
@Test
public void givenBadCode_whenTryHandles_thenCorrect() {
Try<Integer> result = Try.of(() -> 1 / 0);
assertTrue(result.isFailure());
}我们也可以在产生异常时获取一个默认值。
@Test
public void givenBadCode_whenTryHandles_thenCorrect2() {
Try<Integer> computation = Try.of(() -> 1 / 0);
int errorSentinel = result.getOrElse(-1);
assertEquals(-1, errorSentinel);
}或者根据具体需求再抛出一个异常。
@Test(expected = ArithmeticException.class)
public void givenBadCode_whenTryHandles_thenCorrect3() {
Try<Integer> result = Try.of(() -> 1 / 0);
result.getOrElseThrow(ArithmeticException::new);
}5. 函数式接口
Java 8中的函数式接口最多接收两个参数,Vavr对其进行了扩展,最多支持8个参数。
@Test
public void whenCreatesFunction_thenCorrect5() {
Function5<String, String, String, String, String, String> concat =
(a, b, c, d, e) -> a + b + c + d + e;
String finalString = concat.apply(
"Hello ", "world", "! ", "Learn ", "Vavr");
assertEquals("Hello world! Learn Vavr", finalString);
}此外可以通过静态工厂方法FunctionN.of使用方法引用来创建一个Vavr函数。
public int sum(int a, int b) {
return a + b;
}@Test
public void whenCreatesFunctionFromMethodRef_thenCorrect() {
Function2<Integer, Integer, Integer> sum = Function2.of(this::sum);
int summed = sum.apply(5, 6);
assertEquals(11, summed);
}6. 集合Collections
Java中的集合通常是可变集合,这通常是造成错误的根源。特别是在并发场景下。
此外Jdk中的集合类存在一些不足。例如JDK中的集合接口提供的一个方法clear,
该方法删除所有元素而且没有返回值。
interface Collection<E> {
void clear();
}在并发场景下大多集合都会会产生问题,因此有了诸如ConcurrentHashMap这样的类。
此外JDK还通过一些其它的方法创建不可变集集合,但误用某些方法时会产生异常。如
下,创建不可修改List,在误调用add的情况下会产生UnsupportedOperationException
异常。
@Test(expected = UnsupportedOperationException.class)
public void whenImmutableCollectionThrows_thenCorrect() {
java.util.List<String> wordList = Arrays.asList("abracadabra");
java.util.List<String> list = Collections.unmodifiableList(wordList);
list.add("boom");
}Vavr中的集合则会避免这些问题,并且保证了线程安全、不可变等特性。在Vavr中创建一个list,实例并且不包含那些会导致UnsupportedOperationException异常的方法,且不可变,这样避免误用,造成错误。
@Test
public void whenCreatesVavrList_thenCorrect() {
List<Integer> intList = List.of(1, 2, 3);
assertEquals(3, intList.length());
assertEquals(new Integer(1), intList.get(0));
assertEquals(new Integer(2), intList.get(1));
assertEquals(new Integer(3), intList.get(2));
}此外还可以通过提供的API执行计算任务。
@Test
public void whenSumsVavrList_thenCorrect() {
int sum = List.of(1, 2, 3).sum().intValue();
assertEquals(6, sum);
}Vavr集合提供了在Java集合框架中绝大多数常见的类,并且实现了其所有特征。Vavr提供的集合工具使得编写的代码更加紧凑,健壮,并且提供了丰富的功能。
7. 验证Validation
Vavr将函数式编程中 Applicative Functor(函子)的概念引入Java。vavr.control.Validation类能够将错误整合。通常情况下,程序遇到错误就,并且未做处理就会终止。然而,Validation会继续处理,并将程序错误累积,最终最为一个整体处理。
例如我们希望注册用户,用户具有用户名和密码。我们会接收一个输入,然后
决定是否创建Person实例或返回一个错误。Person类如下。
public class Person {
private String name;
private int age;
// setters and getters, toString
}接着,创建一个PersonValidator类。每个变量都会有一个方法来验证。此外还有方法可以将所有的验证结果整合到一个Validation实例中。
class PersonValidator {
String NAME_ERR = "Invalid characters in name: ";
String AGE_ERR = "Age must be at least 0";
public Validation<List<String>, Person> validatePerson(
String name, int age) {
return Validation.combine(
validateName(name), validateAge(age)).ap(Person::new);
}
private Validation<String, String> validateName(String name) {
String invalidChars = name.replaceAll("[a-zA-Z ]", "");
return invalidChars.isEmpty() ?
Validation.valid(name)
: Validation.invalid(NAME_ERR + invalidChars);
}
private Validation<String, Integer> validateAge(int age) {
return age < 0 ? Validation.invalid(AGE_ERR)
: Validation.valid(age);
}
}验证规则为age必须大于0,name不能包含特殊字符。
@Test
public void whenValidationWorks_thenCorrect() {
PersonValidator personValidator = new PersonValidator();
Validation<List<String>, Person> valid =
personValidator.validatePerson("John Doe", 30);
Validation<List<String>, Person> invalid =
personValidator.validatePerson("John? Doe!4", -1);
assertEquals(
"Valid(Person [name=John Doe, age=30])",
valid.toString());
assertEquals(
"Invalid(List(Invalid characters in name: ?!4,
Age must be at least 0))",
invalid.toString());
}Validation.Valid实例包含了有效值。Validation.Invalid包含了错误。因此validation要么
返回有效值要么返回无效值。Validation.Valid内部是一个Person实例,而Validation.Invalid是一组错误信息。
8. 延迟计算Lazy
Lazy是一个容器,表示一个延迟计算的值。计算被推迟,直到需要时才计算。此外,计算的值被缓存或存储起来,当需要时被返回,而不需要重复计算。
@Test
public void givenFunction_whenEvaluatesWithLazy_thenCorrect() {
Lazy<Double> lazy = Lazy.of(Math::random);
assertFalse(lazy.isEvaluated());
double val1 = lazy.get();
assertTrue(lazy.isEvaluated());
double val2 = lazy.get();
assertEquals(val1, val2, 0.1);
}上面的例子中,我们执行的计算是Math.random。当我们调用isEvaluated检查状态时,发现函数并没有被执行。随后调用get方法,我们得到计算的结果。第2次调用get时,再次返回之前计算的结果,而之前的计算结果已被缓存。
9. 模式匹配Pattern Matching
当我们执行一个计算或根据输入返回一个满足条件的值时,我们通常会用到if语句。
@Test
public void whenIfWorksAsMatcher_thenCorrect() {
int input = 3;
String output;
if (input == 0) {
output = "zero";
}
if (input == 1) {
output = "one";
}
if (input == 2) {
output = "two";
}
if (input == 3) {
output = "three";
}
else {
output = "unknown";
}
assertEquals("three", output);
}上述代码仅仅执行若干比较与赋值操作,没个操作都需要3行代码,当条件数量大增时,代码将急剧膨胀。当改为switch时,情况似乎也没有好转。
在Vavr中,我们通过Match方法替换switch块。每个条件检查都通过Case方法调用来替换。 $()来替换条件并完成表达式计算得到结果。
@Test
public void whenMatchworks_thenCorrect() {
int input = 2;
String output = Match(input).of(
Case($(1), "one"),
Case($(2), "two"),
Case($(3), "three"),
Case($(), "?"));
assertEquals("two", output);
}这样,代码变得紧凑,平均每个检查仅用一行。此外我们还可以通过谓词(predicate)来替换表达式。
Match(arg).of(
Case(isIn("-h", "--help"), o -> run(this::displayHelp)),
Case(isIn("-v", "--version"), o -> run(this::displayVersion)),
Case($(), o -> run(() -> {
throw new IllegalArgumentException(arg);
}))
);10. 总结
本文介绍了Vavr的基本能力,Vavr是基于Java 8的一个流行的函数式编程库。通过Vavr提供的功能我们可以改进我们的代码。
11. 原文地址
使用 Vavr 进行函数式编程
在本系列的上一篇文章中对 Java 平台提供的 Lambda 表达式和流做了介绍. 受限于 Java 标准库的通用性要求和二进制文件大小, Java 标准库对函数式编程的 API 支持相对比较有限. 函数的声明只提供了 Function 和 BiFunction 两种, 流上所支持的操作的数量也较少. 为了更好地进行函数式编程, 我们需要第三方库的支持. Vavr 是 Java 平台上函数式编程库中的佼佼者.
Vavr 这个名字对很多开发人员可能比较陌生. 它的前身 Javaslang 可能更为大家所熟悉. Vavr 作为一个标准的 Java 库, 使用起来很简单. 只需要添加对 io.vavr:vavr 库的 Maven 依赖即可. Vavr 需要 Java 8 及以上版本的支持. 本文基于 Vavr 0.9.2 版本, 示例代码基于 Java 10.
元组
元组 (Tuple) 是固定数量的不同类型的元素的组合. 元组与集合的不同之处在于, 元组中的元素类型可以是不同的, 而且数量固定. 元组的好处在于可以把多个元素作为一个单元传递. 如果一个方法需要返回多个值, 可以把这多个值作为元组返回, 而不需要创建额外的类来表示. 根据元素数量的不同, Vavr 总共提供了 Tuple0,Tuple1 到 Tuple8 等 9 个类. 每个元组类都需要声明其元素类型. 如 Tuple2<String, Integer > 表示的是两个元素的元组, 第一个元素的类型为 String, 第二个元素的类型为 Integer. 对于元组对象, 可以使用 _1,_2 到 _8 来访问其中的元素. 所有元组对象都是不可变的, 在创建之后不能更改.
元组通过接口 Tuple 的静态方法 of 来创建. 元组类也提供了一些方法对它们进行操作. 由于元组是不可变的, 所有相关的操作都返回一个新的元组对象. 在 清单 1 中, 使用 Tuple.of 创建了一个 Tuple2 对象. Tuple2 的 map 方法用来转换元组中的每个元素, 返回新的元组对象. 而 apply 方法则把元组转换成单个值. 其他元组类也有类似的方法. 除了 map 方法之外, 还有 map1,map2,map3 等方法来转换第 N 个元素; update1,update2 和 update3 等方法用来更新单个元素.
清单 1. 使用元组
- Tuple2<String, Integer> tuple2 = Tuple.of("Hello", 100);
- Tuple2<String, Integer> updatedTuple2 = tuple2.map(String::toUpperCase, v -> v * 5);
- String result = updatedTuple2.apply((str, number) -> String.join(",",
- str, number.toString()));
- System.out.println(result);
虽然元组使用起来很方便, 但是不宜滥用, 尤其是元素数量超过 3 个的元组. 当元组的元素数量过多时, 很难明确地记住每个元素的位置和含义, 从而使得代码的可读性变差. 这个时候使用 Java 类是更好的选择.
函数
Java 8 中只提供了接受一个参数的 Function 和接受 2 个参数的 BiFunction.Vavr 提供了函数式接口 Function0,Function1 到 Function8, 可以描述最多接受 8 个参数的函数. 这些接口的方法 apply 不能抛出异常. 如果需要抛出异常, 可以使用对应的接口 CheckedFunction0,CheckedFunction1 到 CheckedFunction8.
Vavr 的函数支持一些常见特征.
组合
函数的组合指的是用一个函数的执行结果作为参数, 来调用另外一个函数所得到的新函数. 比如 f 是从 x 到 y 的函数, g 是从 y 到 z 的函数, 那么 g(f(x))是从 x 到 z 的函数. Vavr 的函数式接口提供了默认方法 andThen 把当前函数与另外一个 Function 表示的函数进行组合. Vavr 的 Function1 还提供了一个默认方法 compose 来在当前函数执行之前执行另外一个 Function 表示的函数.
在清单 2 中, 第一个 function3 进行简单的数学计算, 并使用 andThen 把 function3 的结果乘以 100. 第二个 function1 从 String 的 toUpperCase 方法创建而来, 并使用 compose 方法与 Object 的 toString 方法先进行组合. 得到的方法对任何 Object 先调用 toString, 再调用 toUpperCase.
清单 2. 函数的组合
- Function3<Integer, Integer, Integer, Integer> function3 = (v1, v2, v3)
- -> (v1 + v2) * v3;
- Function3<Integer, Integer, Integer, Integer> composed =
- function3.andThen(v -> v * 100);
- int result = composed.apply(1, 2, 3);
- System.out.println(result);
- // 输出结果 900
- Function1<String, String> function1 = String::toUpperCase;
- Function1<Object, String> toUpperCase = function1.compose(Object::toString);
- String str = toUpperCase.apply(List.of("a", "b"));
- System.out.println(str);
- // 输出结果[A, B]
部分应用
在 Vavr 中, 函数的 apply 方法可以应用不同数量的参数. 如果提供的参数数量小于函数所声明的参数数量(通过 arity() 方法获取), 那么所得到的结果是另外一个函数, 其所需的参数数量是剩余未指定值的参数的数量. 在清单 3 中, Function4 接受 4 个参数, 在 apply 调用时只提供了 2 个参数, 得到的结果是一个 Function2 对象.
清单 3. 函数的部分应用
- Function4<Integer, Integer, Integer, Integer, Integer> function4 =
- (v1, v2, v3, v4) -> (v1 + v2) * (v3 + v4);
- Function2<Integer, Integer, Integer> function2 = function4.apply(1, 2);
- int result = function2.apply(4, 5);
- System.out.println(result);
- // 输出 27
柯里化方法
使用 curried 方法可以得到当前函数的柯里化版本. 由于柯里化之后的函数只有一个参数, curried 的返回值都是 Function1 对象. 在清单 4 中, 对于 function3, 在第一次的 curried 方法调用得到 Function1 之后, 通过 apply 来为第一个参数应用值. 以此类推, 通过 3 次的 curried 和 apply 调用, 把全部 3 个参数都应用值.
清单 4. 函数的柯里化
- Function3<Integer, Integer, Integer, Integer> function3 = (v1, v2, v3)
- -> (v1 + v2) * v3;
- int result =
- function3.curried().apply(1).curried().apply(2).curried().apply(3);
- System.out.println(result);
记忆化方法
使用记忆化的函数会根据参数值来缓存之前计算的结果. 对于同样的参数值, 再次的调用会返回缓存的值, 而不需要再次计算. 这是一种典型的以空间换时间的策略. 可以使用记忆化的前提是函数有引用透明性.
在清单 5 中, 原始的函数实现中使用 BigInteger 的 pow 方法来计算乘方. 使用 memoized 方法可以得到该函数的记忆化版本. 接着使用同样的参数调用两次并记录下时间. 从结果可以看出来, 第二次的函数调用的时间非常短, 因为直接从缓存中获取结果.
清单 5. 函数的记忆化
- Function2<BigInteger, Integer, BigInteger> pow = BigInteger::pow;
- Function2<BigInteger, Integer, BigInteger> memoized = pow.memoized();
- long start = System.currentTimeMillis();
- memoized.apply(BigInteger.valueOf(1024), 1024);
- long end1 = System.currentTimeMillis();
- memoized.apply(BigInteger.valueOf(1024), 1024);
- long end2 = System.currentTimeMillis();
- System.out.printf("%d ms -> %d ms", end1 - start, end2 - end1);
注意, memoized 方法只是把原始的函数当成一个黑盒子, 并不会修改函数的内部实现. 因此, memoized 并不适用于直接封装本系列第二篇文章中用递归方式计算斐波那契数列的函数. 这是因为在函数的内部实现中, 调用的仍然是没有记忆化的函数.
值
Vavr 中提供了一些不同类型的值.
Option
Vavr 中的 Option 与 Java 8 中的 Optional 是相似的. 不过 Vavr 的 Option 是一个接口, 有两个实现类 Option.Some 和 Option.None, 分别对应有值和无值两种情况. 使用 Option.some 方法可以创建包含给定值的 Some 对象, 而 Option.none 可以获取到 None 对象的实例. Option 也支持常用的 map,flatMap 和 filter 等操作, 如清单 6 所示.
清单 6. 使用 Option 的示例
- Option<String> str = Option.of("Hello");
- str.map(String::length);
- str.flatMap(v -> Option.of(v.length()));
- Either
Either 表示可能有两种不同类型的值, 分别称为左值或右值. 只能是其中的一种情况. Either 通常用来表示成功或失败两种情况. 惯例是把成功的值作为右值, 而失败的值作为左值. 可以在 Either 上添加应用于左值或右值的计算. 应用于右值的计算只有在 Either 包含右值时才生效, 对左值也是同理.
在清单 7 中, 根据随机的布尔值来创建包含左值或右值的 Either 对象. Either 的 map 和 mapLeft 方法分别对右值和左值进行计算.
清单 7. 使用 Either 的示例
- import io.vavr.control.Either;
- import java.util.concurrent.ThreadLocalRandom;
- public class Eithers {
- private static ThreadLocalRandom random =
- ThreadLocalRandom.current();
- public static void main(String[] args) {
- Either<String, String> either = compute()
- .map(str -> str + "World")
- .mapLeft(Throwable::getMessage);
- System.out.println(either);
- }
- private static Either<Throwable, String> compute() {
- return random.nextBoolean()
- ? Either.left(new RuntimeException("Boom!"))
- : Either.right("Hello");
- }
- }
- Try
Try 用来表示一个可能产生异常的计算. Try 接口有两个实现类, Try.Success 和 Try.Failure, 分别表示成功和失败的情况. Try.Success 封装了计算成功时的返回值, 而 Try.Failure 则封装了计算失败时的 Throwable 对象. Try 的实例可以从接口 CheckedFunction0,Callable,Runnable 或 Supplier 中创建. Try 也提供了 map 和 filter 等方法. 值得一提的是 Try 的 recover 方法, 可以在出现错误时根据异常进行恢复.
在清单 8 中, 第一个 Try 表示的是 1/0 的结果, 显然是异常结果. 使用 recover 来返回 1. 第二个 Try 表示的是读取文件的结果. 由于文件不存在, Try 表示的也是异常.
清单 8. 使用 Try 的示例
- Try<Integer> result = Try.of(() -> 1 / 0).recover(e -> 1);
- System.out.println(result);
- Try<String> lines = Try.of(() -> Files.readAllLines(Paths.get("1.txt")))
- .map(list -> String.join(",", list))
- .andThen((Consumer<String>) System.out::println);
- System.out.println(lines);
- Lazy
Lazy 表示的是一个延迟计算的值. 在第一次访问时才会进行求值操作, 而且该值只会计算一次. 之后的访问操作获取的是缓存的值. 在清单 9 中, Lazy.of 从接口 Supplier 中创建 Lazy 对象. 方法 isEvaluated 可以判断 Lazy 对象是否已经被求值.
清单 9. 使用 Lazy 的示例
- Lazy<BigInteger> lazy = Lazy.of(() ->
- BigInteger.valueOf(1024).pow(1024));
- System.out.println(lazy.isEvaluated());
- System.out.println(lazy.get());
- System.out.println(lazy.isEvaluated());
数据结构
Vavr 重新在 Iterable 的基础上实现了自己的集合框架. Vavr 的集合框架侧重在不可变上. Vavr 的集合类在使用上比 Java 流更简洁.
Vavr 的 Stream 提供了比 Java 中 Stream 更多的操作. 可以使用 Stream.ofAll 从 Iterable 对象中创建出 Vavr 的 Stream. 下面是一些 Vavr 中添加的实用操作:
groupBy: 使用 Fuction 对元素进行分组. 结果是一个 Map,Map 的键是分组的函数的结果, 而值则是包含了同一组中全部元素的 Stream.
partition: 使用 Predicate 对元素进行分组. 结果是包含 2 个 Stream 的 Tuple2.Tuple2 的第一个 Stream 的元素满足 Predicate 所指定的条件, 第二个 Stream 的元素不满足 Predicate 所指定的条件.
scanLeft 和 scanRight: 分别按照从左到右或从右到左的顺序在元素上调用 Function, 并累积结果.
zip: 把 Stream 和一个 Iterable 对象合并起来, 返回的结果 Stream 中包含 Tuple2 对象. Tuple2 对象的两个元素分别来自 Stream 和 Iterable 对象.
在清单 10 中, 第一个 groupBy 操作把 Stream 分成奇数和偶数两组; 第二个 partition 操作把 Stream 分成大于 2 和不大于 2 两组; 第三个 scanLeft 对包含字符串的 Stream 按照字符串长度进行累积; 最后一个 zip 操作合并两个流, 所得的结果 Stream 的元素数量与长度最小的输入流相同.
清单 10. Stream 的使用示例
- Map<Boolean, List<Integer>> booleanListMap = Stream.ofAll(1, 2, 3, 4, 5)
- .groupBy(v -> v % 2 == 0)
- .mapValues(Value::toList);
- System.out.println(booleanListMap);
- // 输出 LinkedHashMap((false, List(1, 3, 5)), (true, List(2, 4)))
- Tuple2<List<Integer>, List<Integer>> listTuple2 = Stream.ofAll(1, 2, 3, 4)
- .partition(v -> v> 2)
- .map(Value::toList, Value::toList);
- System.out.println(listTuple2);
- // 输出 (List(3, 4), List(1, 2))
- List<Integer> integers = Stream.ofAll(List.of("Hello", "World", "a"))
- .scanLeft(0, (sum, str) -> sum + str.length())
- .toList();
- System.out.println(integers);
- // 输出 List(0, 5, 10, 11)
- List<Tuple2<Integer, String>> tuple2List = Stream.ofAll(1, 2, 3)
- .zip(List.of("a", "b"))
- .toList();
- System.out.println(tuple2List);
- // 输出 List((1, a), (2, b))
Vavr 提供了常用的数据结构的实现, 包括 List,Set,Map,Seq,Queue,Tree 和 TreeMap 等. 这些数据结构的用法与 Java 标准库的对应实现是相似的, 但是提供的操作更多, 使用起来也更方便. 在 Java 中, 如果需要对一个 List 的元素进行 map 操作, 需要使用 stream 方法来先转换为一个 Stream, 再使用 map 操作, 最后再通过收集器 Collectors.toList 来转换回 List. 而在 Vavr 中, List 本身就提供了 map 操作. 清单 11 中展示了这两种使用方式的区别.
清单 11. Vavr 中数据结构的用法
- List.of(1, 2, 3).map(v -> v + 10); //Vavr
- java.util.List.of(1, 2, 3).stream()
- .map(v -> v + 10).collect(Collectors.toList()); //Java 中 Stream
模式匹配
在 Java 中, 我们可以使用 switch 和 case 来根据值的不同来执行不同的逻辑. 不过 switch 和 case 提供的功能很弱, 只能进行相等匹配. Vavr 提供了模式匹配的 API, 可以对多种情况进行匹配和执行相应的逻辑. 在清单 12 中, 我们使用 Vavr 的 Match 和 Case 替换了 Java 中的 switch 和 case.Match 的参数是需要进行匹配的值. Case 的第一个参数是匹配的条件, 用 Predicate 来表示; 第二个参数是匹配满足时的值.$(value) 表示值为 value 的相等匹配, 而 $() 表示的是默认匹配, 相当于 switch 中的 default.
清单 12. 模式匹配的示例
- String input = "g";
- String result = Match(input).of(
- Case($("g"), "good"),
- Case($("b"), "bad"),
- Case($(), "unknown")
- );
- System.out.println(result);
- // 输出 good
在清单 13 中, 我们用 $(v -> v> 0) 创建了一个值大于 0 的 Predicate. 这里匹配的结果不是具体的值, 而是通过 run 方法来产生副作用.
清单 13. 使用模式匹配来产生副作用
- int value = -1;
- Match(value).of(
- Case($(v -> v> 0), o -> run(() -> System.out.println("> 0"))),
- Case($(0), o -> run(() -> System.out.println("0"))),
- Case($(), o -> run(() -> System.out.println("< 0")))
- );
- // 输出< 0
总结
当需要在 Java 平台上进行复杂的函数式编程时, Java 标准库所提供的支持已经不能满足需求. Vavr 作为 Java 平台上流行的函数式编程库, 可以满足不同的需求. 本文对 Vavr 提供的元组, 函数, 值, 数据结构和模式匹配进行了详细的介绍. 下一篇文章将介绍函数式编程中的重要概念 Monad.
参考资源
参考 Vavr 的官方文档 http://www.vavr.io/vavr-docs/ .
查看 Vavr 的 Java API 文档 http://www.javadoc.io/doc/io.vavr/vavr/0.9.2 .
评论
来源: http://www.ibm.com/developerworks/cn/java/j-understanding-functional-programming-4/index.html
与本文相关文章
- Scala 函数式编程 (五) 函数式的错误处理
- 面向对象编程 —— java实现函数求导
- Java - 函数式编程 (一) 初识篇
- Java8 函数式编程以及 Lambda 表达式
- Java 函数式编程 (六):Optional
- 使用 Java 进行 udp-demo 编程时碰到的 consumer 和 producter 无法连接并报出 "java.net.SocketException: Can't assign requested address" 问题
- Scala 函数式编程 (六) 懒加载与 Stream
- Java 函数式编程 (五): 闭包
Vavr Option:Java Optional 的另一个选项
每当涉及Java,总会有很多选项。 这篇文章讨论了 Java 基础类 Optional 用法,与 Vavr 中的对应方法进行比较。Java 8最早引入了 Optional,把它定义为“一种容器对象,可以存储 null 或非 null 值”。
通常,在返回值可能为null的地方,会出现NullPointerException。开发人员可以使用 Optional 避免 null 值检查。在这种情况下,Optional 提供了一些方便的功能。但可惜的是,Java 8并没有包含所有功能。Optional中的某些功能需要使用 Java 11。要解决这类问题还可以使用 Vavr Option类。
本文将介绍如何使用 Java Optional类,并与 Vavr Option 进行比较。注意:示例代码要求使用Java 11及更高版本。所有代码在 Vavr0.10.2环境下完成测试。
让我们开始吧。
Java Optional 简介
Optional 并不是什么新概念,像 Haskell、Scala 这样的函数式编程语言已经提供了实现。调用方法后,返回值未知或者不存在(比如 null)的情况下,用 Optional 处理非常好用。下面通过实例进行介绍。
新建 Optional 实例
首先,需要获得 Optional 实例,有以下几种方法可以新建 Optional 实例。不仅如此,还可以创建empty Optional。方法一,通过 value 创建,过程非常简单:
Optional<Integer> four = Optional.of(Integer.valueOf(4));
if (four.isPresent){
System.out.println("Hoorayy! We have a value");
} else {
System.out.println("No value");
}为Integer 4 新建一个Optional实例。这种方法得到的 Optional 始终包含一个 value 且不为 null,例如上面这个示例。使用 ifPresent() 可以检查value是否存在。可以注意到 four 不是 Integer,而是一个装有整数的容器。如果确认 value 存在,可以用 get() 方法执行拆箱操作。具有讽刺意味的是,调用 get() 前如果不进行检查,可能会抛出 NoSuchElementException。
方法二,得到 Optional 对象的另一种方法是使用 stream。Stream提供的一些方法会返回Optional,可以用来检查结果是否存在,例如:
-
findAny
-
findFirst
-
max
-
min
-
reduce
查看下面的代码段:
Optional<Car> car = cars.stream().filter(car->car.getId().equalsIgnoreCase(id)).findFirst();
方法三,使用 Nullable 新建 Optional。可能产生 null:
Optional<Integer> nullable = Optional.ofNullable(client.getRequestData());
最后,可以新建一个 empty Optional:
Optional<Integer> nothing = Optional.empty();
如何使用 Optional
获得 Optional 对象后即可使用。一种典型的场景是在 Spring 仓库中根据 Id 查找记录。可以使用 Optional 实现代码逻辑,避免 null 检查(顺便提一下,Spring 也支持 Vavr Option)。比如,从图书仓库里查找一本书。
Optional<Book> book = repository.findOne("some id");
首先,如果有这本书,可以继续执行对应的业务逻辑。在前面的章节用 if-else实现了功能。当然,还有其他办法:Optional 提供了一个方法,接收 Consumer 对象作为输入:
repository.findOne("some id").ifPresent(book -> System.out.println(book));
还可以直接使用方法引用,看起来更简单:
repository.findOne("some id").ifPresent(System.out::println);
如果仓库中没有该书,可以用ifPresentOrElseGet提供回调函数:
repository.findOne("some id").ifPresentOrElseGet(book->{
// 如果 value 存在
}, ()->{
// 如果 value 不存在
});如果结果不存在,可以返回另一个value:
Book result = repository.findOne("some id").orElse(defaultBook);
但是,Optional 也有缺点,使用时需要注意。最后一个例子中,“确保”无论如何都能获得一本书,可能在仓库中,也可能来自 orElse。但如果默认的返回值不是常量或者需要支持一些复杂方法该怎么办?首先,Java 无论如何都会执行 findOne,然后调用 orElse方法。默认返回值可以为常量,但正如我之前所说那样,执行过程比较耗时。
另一个示例
下面用一个简单的示例介绍如何实际使用 Optional 和 Option 类。有一个 CarRepository,可以根据提供的 ID(比如车牌号)查找汽车,接下来用这个示例介绍如何使用 Optional 和 Option。
首先,加入下面代码
从 POJO 类 Car 开始。它遵循 immutable 模式,所有字段都标记为 final,只包含 getter 没有 setter。初始化时提供所有数据:
public class Car {
private final String name;
private final String id;
private final String color;
public Car (String name, String id, String color){
this.name = name;
this.id = id;
this.color = color;
}
public String getId(){
return id;
}
public String getColor() {
return color;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "Car "+name+" with license id "+id+" and of color "+color;
}
}接下来创建 CarRepository类。提供两种方法根据Id查找汽车:一种是老办法,使用 Optional。和之前在 Spring 仓库的做法类似,结果可能为 null。
public class CarRepository {
private List<Car> cars;
public CarRepository(){
getSomeCars();
}
Car findCarById(String id){
for (Car car: cars){function(){ //外汇跟单www.gendan5.com if (car.getId().equalsIgnoreCase(id)){
return car;
}
}
return null;
}
Optional<Car> findCarByIdWithOptional(String id){
return cars.stream().filter(car->car.getId().equalsIgnoreCase(id)).findFirst();
}
private void getSomeCars(){
cars = new ArrayList<>();
cars.add(new Car("tesla", "1A9 4321", "red"));
cars.add(new Car("volkswagen", "2B1 1292", "blue"));
cars.add(new Car("skoda", "5C9 9984", "green"));
cars.add(new Car("audi", "8E4 4321", "silver"));
cars.add(new Car("mercedes", "3B4 5555", "black"));
cars.add(new Car("seat", "6U5 3123", "white"));
}
}注意:初始化过程会在仓库中添加一些汽车模拟数据,便于演示。为了突出重点,避免问题复杂化,下面的讨论专注于 Optional 和 Option。
使用Java Optional
使用JUnit创建一个新测试:
@Test
void getCarById(){
Car car = repository.findCarById("1A9 4321");
Assertions.assertNotNull(car);
Car nullCar = repository.findCarById("M 432 KT");
Assertions.assertThrows(NullPointerException.class, ()->{
if (nullCar == null){
throw new NullPointerException();
}
});
}上面的代码段采用了之前的老办法。查找捷克牌照1A9 4321对应的汽车,检查该车是否存在。输入俄罗斯车牌找不到对应的汽车,因为仓库中只有捷克车。结果为 null 可能会抛出 NullPointerException。
接下来用Java Optional。第一步,获得 Optional 实例,从存储库中使用指定方法返回 Optional:
@Test
void getCarByIdWithOptional(){
Optional<Car> tesla = repository.findCarByIdWithOptional("1A9 4321");
tesla.ifPresent(System.out::println);
}这时调用findCarByIdWithOptional方法打印车辆信息(如果有的话)。运行程序,得到以下结果:
Car tesla with license id 1A9 4321 and of color red
但是,如果代码中没有特定方法该怎么办?这种情况可以从方法返回可能包含 null 的 Optional,称为nullable。
Optional<Car> nothing = Optional.ofNullable(repository.findCarById("5T1 0965"));
Assertions.assertThrows(NoSuchElementException.class, ()->{
Car car = nothing.orElseThrow(()->new NoSuchElementException());
});上面这段代码段中,我们发现了另一种方法。通过 findCarById 创建 Optional,如果未找到汽车可以返回 null。没有找到车牌号5T1 0965汽车时,可以用 orElseThrow 手动抛出 NoSuchElementException。另一种情况,如果请求的数据不在仓库中,可以用orElse返回默认值:
Car audi = repository.findCarByIdWithOptional("8E4 4311")
.orElse(new Car("audi", "1W3 4212", "yellow"));
if (audi.getColor().equalsIgnoreCase("silver")){
System.out.println("We have silver audi in garage!");
} else {
System.out.println("Sorry, there is no silver audi, but we called you a taxi");
}好的,车库里没有找到银色奥迪,只好打车了!
使用 Vavr Option
Vavr OptionOption提供了另一种解决办法。首先,在项目中添加依赖,(使用 Maven)安装 Vavr:
<dependency>
<groupId>io.vavr</groupId>
<artifactId>vavr</artifactId>
<version>0.10.2</version>
</dependency>简而言之,Vavr 提供了类似的 API 新建 Option 实例。可以从 nullable 新建 Option 实例,像下面这样:
Option<Car> nothing = Option.of(repository.findCarById("T 543 KK"));
也可以用 none 静态方法创建一个empty容器:
Option<Car> nullable = Option.none();
此外,还有一种方法可以用 Java Optional 新建 Option。看下面这段代码:
Option<Car> result = Option.ofOptional(repository.findCarByIdWithOptional("5C9 9984"));
使用 Vavr Option,可以使用与 Optional相同的 API 来完成上述任务。例如,设置默认值:
Option<Car> result = Option.ofOptional(repository.findCarByIdWithOptional("5C9 9984"));
Car skoda = result.getOrElse(new Car("skoda", "5E2 4232", "pink"));
System.out.println(skoda);或者,请求的数据不存在时可以抛出异常:
Option<Car> nullable = Option.none();
Assertions.assertThrows(NoSuchElementException.class, ()->{
nullable.getOrElseThrow(()->new NoSuchElementException());
});另外,当数据不可用时,可以执行以下操作:
nullable.onEmpty(()->{
///runnable
});如何根据数据是否存在来执行相应操作,类似 Optional 中 ifPresent?有几种实现方式。与 Optional 中 isPresent 类似,在 Option 中对应的方法称为 isDefined:
if (result.isDefined()){
// 实现功能
}然而,使用 Option能摆脱 if-else。是否可以用Optional相同的方式完成?使用 peek 操作:
result.peek(val -> System.out.println(val)).onEmpty(() -> System.out.println("Result is missed"));
此外,Vavr Option还提供了一些其他非常有用的方法,在函数式编程上比Optional类效果更好。因此,建议您花一些时间来探索 Vavr Option javadocs尝试使用这些API。我会持续跟进一些类似 map、narrow、isLazy 和 when 这样有趣的功能。
另外,Option只是 Vavr 开发库的一部分,其中还包含了许多其他关联类。不考虑这些类直接与 Optional 比较是不对的。接下来我会继续编写 Vavr 主题的系列文章,介绍 Vavr 相关技术例如 Try、Collections 和 Streams。敬请关注!
总结
本文中,我们讨论了 Java Optional 类。Optional 并不是什么新概念,像 Haskell、Scala这样的函数式编程语言已经提供了实现。调用方法后,返回值未知或者不存在(比如 null)的情况下,Optional 非常有用。然后,介绍了 Optional API,并设计了一个汽车搜索示例进行说明。最后,介绍了 Optional 的另一种替代方案 Vavr Option 并通过示例进行了介绍。
Vavr User Guide中英对照版
Vavr User Guide(Vavr用户指南)
Daniel Dietrich, Robert Winkler - Version 0.9.2,2018-10-01
0. Vavr
Vavr是Java 8 的对象函数式扩展,目标是减少代码行数,提高代码质量,提供了持久化集合、错误处理函数式抽象、模式匹配等等。
Vavr 融合了面向对象编程的强大功能,具有功能编程的优雅性和坚固性。 最有趣的部分是拥有功能丰富且持久的集合库,可以与 Java 的标准集合顺利集成。
1. Introduction(简介)
Vavr (formerly called Javaslang) is a functional library for Java 8+ that provides persistent data types and functional control structures.
Vavr(以前称为Javaslang)是Java 8+的函数库,它提供持久数据类型和函数式控制结构。
1.1. Functional Data Structures in Java 8 with Vavr
Java 8’s lambdas (λ) empower us to create wonderful API’s. They incredibly increase the expressiveness of the language.
Java 8的lambdas (λ)使我们能够创建出色的API。 他们令人难以置信地增加了语言的表现力。
Vavr leveraged lambdas to create various new features based on functional patterns. One of them is a functional collection library that is intended to be a replacement for Java’s standard collections.
Vavr 利用lambdas基于函数式模式创建各种新功能。 其中之一是函数式集合库,旨在替代Java的标准集合。
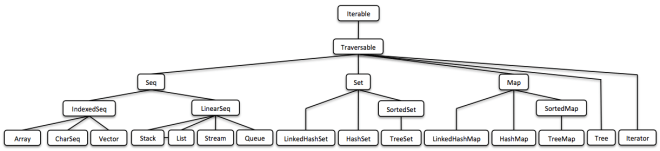 (This is just a bird’s view, you will find a human-readable version below.) (这只是一个鸟览视图,你会在下面找到一个可读的版本。)
(This is just a bird’s view, you will find a human-readable version below.) (这只是一个鸟览视图,你会在下面找到一个可读的版本。)
1.2. Functional Programming
Before we deep-dive into the details about the data structures I want to talk about some basics. This will make it clear why I created Vavr and specifically new Java collections.
在我们深入研究有关数据结构的细节之前,我想谈谈一些基础知识。 这将清楚地表明我为什么创建Vavr以及特别是新的Java集合。
1.2.1. Side-Effects(副作用)
Java applications are typically plentiful of side-effects. They mutate some sort of state, maybe the outer world. Common side effects are changing objects or variables in place, printing to the console, writing to a log file or to a database. Side-effects are considered harmful if they affect the semantics of our program in an undesirable way.
Java应用程序通常有很多副作用。 他们改变某种状态,也许是外部世界。 常见的副作用是更改对象或变量,打印到控制台,写入日志文件或数据库。 如果副作用以不合需要的方式影响我们程序的语义,则认为它们是有害的。
For example, if a function throws an exception and this exception is interpreted, it is considered as side-effect that affects our program. Furthermore exceptions are like non-local goto-statements. They break the normal control-flow. However, real-world applications do perform side-effects.
例如,如果函数抛出异常并且此异常被解释,则将其视为影响我们的程序的副作用。 此外异常就像非本地goto语句。 它们打破了正常的控制流程。 但是,实际应用程序确实会产生副作用。
int divide(int dividend, int divisor) {
// throws if divisor is zero
return dividend / divisor;
}
In a functional setting we are in the favorable situation to encapsulate the side-effect in a Try:
在函数设设置中,我们处于有利的情况下将副作用封装在Try中:
// = Success(result) or Failure(exception)
Try<Integer> divide(Integer dividend, Integer divisor) {
return Try.of(() -> dividend / divisor);
}
This version of divide does not throw any exception anymore. We made the possible failure explicit by using the type Try.
这个版本的除法不再抛出任何异常。 我们使用Try类型明确了可能的失败。
1.2.2. Referential Transparency
A function, or more generally an expression, is called referentially transparent if a call can be replaced by its value without affecting the behavior of the program. Simply spoken, given the same input the output is always the same.
如果可以用其值替换调用而不影响程序的行为,则函数或更一般地称为表达式称为引用透明。 简单地说,给定相同的输入,输出总是相同的。
// not referentially transparent
Math.random();
// referentially transparent
Math.max(1, 2);
A function is called pure if all expressions involved are referentially transparent. An application composed of pure functions will most probably just work if it compiles. We are able to reason about it. Unit tests are easy to write and debugging becomes a relict of the past.
如果涉及的所有表达式都是引用透明的,则函数称为pure。 如果编译,由纯函数组成的应用程序很可能只是工作。 我们能够解释它。 单元测试很容易编写,调试成为过去的遗留问题。
1.2.3. Thinking in Values
Rich Hickey, the creator of Clojure, gave a great talk about The Value of Values. The most interesting values are immutablevalues. The main reason is that immutable values
Clojure的创建者Rich Hickey对价值的价值进行了精彩的讨论。 最有趣的值是immutable值。 主要原因是不可变的价值观
- are inherently thread-safe and hence do not need to be synchronized
本质上是线程安全的,因此不需要同步 - are stable regarding equals and hashCode and thus are reliable hash keys
关于* equals 和 hashCode *是稳定的,因此是可靠的散列键 - do not need to be cloned
不需要克隆 - behave type-safe when used in unchecked covariant casts (Java-specific)
在unchecked covariant casts中使用时表现类型安全(特定于Java) The key to a better Java is to use immutable values paired with referentially transparent functions.
更好的Java的关键是使用immutable values与referentially透明函数配对。
Vavr provides the necessary controls and collections to accomplish this goal in every-day Java programming.
Vavr提供必要的控制和[collections](https:// static .javadoc.io / io.vavr / vavr / 0.9.2 / io / vavr / collection / package-summary.html)在日常Java编程中实现这一目标.
1.3. Data Structures in a Nutshell
Vavr’s collection library comprises of a rich set of functional data structures built on top of lambdas. The only interface they share with Java’s original collections is Iterable. The main reason is that the mutator methods of Java’s collection interfaces do not return an object of the underlying collection type.
Vavr的集合库包含一组构建在lambdas之上的丰富的函数式数据结构。 他们与Java的原始集合共享的唯一接口是Iterable。 主要原因是Java集合接口的mutator方法不返回底层集合类型的对象。
We will see why this is so essential by taking a look at the different types of data structures.
我们将通过研究不同类型的数据结构来了解为什么这是如此重要。
1.3.1. Mutable Data Structures
Java is an object-oriented programming language. We encapsulate state in objects to achieve data hiding and provide mutator methods to control the state. The Java collections framework (JCF) is built upon this idea.
Java是一种面向对象的编程语言. 我们将状态封装在对象中以实现数据隐藏,并提供mutator方法来控制状态. Java集合框架(JCF)建立在这个想法之上.
interface Collection<E> {
// removes all elements from this collection
void clear();
}
Today I comprehend a void return type as a smell. It is evidence that side-effects take place, state is mutated. Sharedmutable state is an important source of failure, not only in a concurrent setting.
今天我理解一个* void *返回类型作为气味. 有证据表明副作用发生了,状态发生了变异. 共享可变状态是一个重要的失败源,不仅仅是在并发设置中.
1.3.2. Immutable Data Structures
Immutable data structures cannot be modified after their creation. In the context of Java they are widely used in the form of collection wrappers.
Immutable数据结构在创建后无法修改。 在Java的上下文中,它们以集合包装器的形式被广泛使用。
List<String> list = Collections.unmodifiableList(otherList);
// Boom!
list.add("why not?");
There are various libraries that provide us with similar utility methods. The result is always an unmodifiable view of the specific collection. Typically it will throw at runtime when we call a mutator method.
有各种库为我们提供类似的实用方法。 结果始终是特定集合的不可修改的视图。 通常,当我们调用mutator方法时,它将在运行时抛出。
1.3.3. Persistent Data Structures
A persistent data structure does preserve the previous version of itself when being modified and is therefore effectivelyimmutable. Fully persistent data structures allow both updates and queries on any version.
持久数据结构在修改时会保留其自身的先前版本,因此有效不可变. 完全持久的数据结构允许对任何版本进行更新和查询.
Many operations perform only small changes. Just copying the previous version wouldn’t be efficient. To save time and memory, it is crucial to identify similarities between two versions and share as much data as possible.
许多操作只执行很小的更改。 只是复制以前的版本效率不高。 为了节省时间和内存,确定两个版本之间的相似性并尽可能多地共享数据至关重要。
This model does not impose any implementation details. Here come functional data structures into play.
此模型不会强加任何实现细节。 这里有函数式数据结构发挥作用。
1.4. Functional Data Structures
Also known as purely functional data structures, these are immutable and persistent. The methods of functional data structures are referentially transparent.
也称为纯函数式数据结构,这些是不可变和持久的. 函数式数据结构的方法是引用透明的.
Vavr features a wide range of the most-commonly used functional data structures. The following examples are explained in-depth.
Vavr具有广泛的最常用函数式数据结构。 以下示例将进行深入解释。
1.4.1. Linked List
One of the most popular and also simplest functional data structures is the (singly) linked List. It has a head element and a tail List. A linked List behaves like a Stack which follows the last in, first out (LIFO) method.
最受欢迎且最简单的函数式数据结构之一是(单链接)列表. 它有一个* head 元素和一个 tail * List. 链接列表的行为类似于后进先出(LIFO)方法的堆栈.
In Vavr we instantiate a List like this:
在Vavr中,我们实例化一个像这样的List:
// = List(1, 2, 3)
List<Integer> list1 = List.of(1, 2, 3);
Each of the List elements forms a separate List node. The tail of the last element is Nil, the empty List.
每个List元素形成一个单独的List节点。 最后一个元素的尾部是Nil,即空列表。
 This enables us to share elements across different versions of the List.
This enables us to share elements across different versions of the List.
这使我们能够跨List的不同版本共享元素。
// = List(0, 2, 3)
List<Integer> list2 = list1.tail().prepend(0);
The new head element 0 is linked to the tail of the original List. The original List remains unmodified.
新的head元素0 链接到原始List的尾部。 原始清单保持不变。
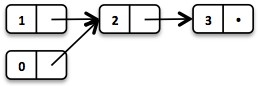 These operations take place in constant time, in other words they are independent of the List size. Most of the other operations take linear time. In Vavr this is expressed by the interface LinearSeq, which we may already know from Scala.
These operations take place in constant time, in other words they are independent of the List size. Most of the other operations take linear time. In Vavr this is expressed by the interface LinearSeq, which we may already know from Scala.
这些操作以恒定时间进行,换句话说,它们与列表大小无关。 大多数其他操作需要线性时间。 在Vavr中,这由LinearSeq接口表示,我们可能已经从Scala中知道了。
If we need data structures that are queryable in constant time, Vavr offers Array and Vector. Both have random accesscapabilities.
如果我们需要在恒定时间内可查询的数据结构,Vavr会提供Array和Vector。 两者都具有随机访问功能。
The Array type is backed by a Java array of objects. Insert and remove operations take linear time. Vector is in-between Array and List. It performs well in both areas, random access and modification.
Array类型由Java对象数组支持。 插入和删除操作需要线性时间。 矢量是介于数组和列表之间。 它在两个领域都表现良好,随机访问和修改。
In fact the linked List can also be used to implement a Queue data structure.
实际上,链接List也可用于实现Queue数据结构。
1.4.2. Queue
A very efficient functional Queue can be implemented based on two linked Lists. The front List holds the elements that are dequeued, the rear List holds the elements that are enqueued. Both operations enqueue and dequeue perform in O(1).
可以基于两个链接列表实现非常有效的函数式队列。 * front * List包含出列的元素,* rear * List包含入队的元素。 两个操作在O(1)中排队和出列。
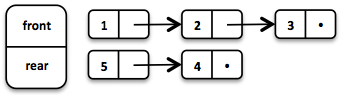
Queue<Integer> queue = Queue.of(1, 2, 3)
.enqueue(4)
.enqueue(5);
The initial Queue is created of three elements. Two elements are enqueued on the rear List.
初始队列由三个元素组成。 rear的List中有两个元素。
 If the front List runs out of elements when dequeueing, the rear List is reversed and becomes the new front List.
If the front List runs out of elements when dequeueing, the rear List is reversed and becomes the new front List.
如果front List在出列时用完了元素,则rear List将反转并成为新的前列表。
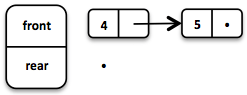 When dequeueing an element we get a pair of the first element and the remaining Queue. It is necessary to return the new version of the Queue because functional data structures are immutable and persistent. The original Queue is not affected.
When dequeueing an element we get a pair of the first element and the remaining Queue. It is necessary to return the new version of the Queue because functional data structures are immutable and persistent. The original Queue is not affected.
当一个元素出列时,我们得到一对第一个元素和剩余的Queue。 有必要返回新版本的Queue,因为函数式数据结构是不可变的和持久的。 原始队列不受影响。
Queue<Integer> queue = Queue.of(1, 2, 3);
// = (1, Queue(2, 3))
Tuple2<Integer, Queue<Integer>> dequeued =
queue.dequeue();
What happens when the Queue is empty? Then dequeue() will throw a NoSuchElementException. To do it the functional way we would rather expect an optional result.
当队列为空时会发生什么? 然后dequeue()将抛出NoSuchElementException。 要做到函数式方式我们宁愿期待一个可选的结果。
// = Some((1, Queue()))
Queue.of(1).dequeueOption();
// = None
Queue.empty().dequeueOption();
An optional result may be further processed, regardless if it is empty or not.
可以进一步处理可选结果,无论它是否为空。
// = Queue(1)
Queue<Integer> queue = Queue.of(1);
// = Some((1, Queue()))
Option<Tuple2<Integer, Queue<Integer>>> dequeued =
queue.dequeueOption();
// = Some(1)
Option<Integer> element = dequeued.map(Tuple2::_1);
// = Some(Queue())
Option<Queue<Integer>> remaining =
dequeued.map(Tuple2::_2);
1.4.3. Sorted Set
Sorted Sets are data structures that are more frequently used than Queues. We use binary search trees to model them in a functional way. These trees consist of nodes with up to two children and values at each node.
排序Set是比队列更频繁使用的数据结构。 我们使用二叉搜索树以函数式方式对它们进行建模。 这些树由最多两个子节点和每个节点的值组成。
We build binary search trees in the presence of an ordering, represented by an element Comparator. All values of the left subtree of any given node are strictly less than the value of the given node. All values of the right subtree are strictly greater.
我们在排序的情况下构建二元搜索树,由元素Comparator表示。 任何给定节点的左子树的所有值都严格小于给定节点的值。 右子树的所有值都严格更大。
// = TreeSet(1, 2, 3, 4, 6, 7, 8)
SortedSet<Integer> xs = TreeSet.of(6, 1, 3, 2, 4, 7, 8);
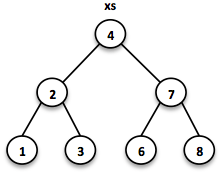 Searches on such trees run in O(log n) time. We start the search at the root and decide if we found the element. Because of the total ordering of the values we know where to search next, in the left or in the right branch of the current tree.
Searches on such trees run in O(log n) time. We start the search at the root and decide if we found the element. Because of the total ordering of the values we know where to search next, in the left or in the right branch of the current tree.
对这些树的搜索在O(log n)时间内运行。 我们从根开始搜索并决定是否找到了元素。 由于值的总排序,我们知道接下来要搜索的位置,在当前树的左侧或右侧分支中。
// = TreeSet(1, 2, 3);
SortedSet<Integer> set = TreeSet.of(2, 3, 1, 2);
// = TreeSet(3, 2, 1);
Comparator<Integer> c = (a, b) -> b - a;
SortedSet<Integer> reversed = TreeSet.of(c, 2, 3, 1, 2);
Most tree operations are inherently recursive. The insert function behaves similarly to the search function. When the end of a search path is reached, a new node is created and the whole path is reconstructed up to the root. Existing child nodes are referenced whenever possible. Hence the insert operation takes O(log n) time and space.
大多数树操作本质上是递归。 插入函数的行为与搜索功能类似。 到达搜索路径的末尾时,将创建一个新节点,并将整个路径重建到根目录。 尽可能引用现有子节点。 因此,插入操作需要O(log n)时间和空间。
// = TreeSet(1, 2, 3, 4, 5, 6, 7, 8)
SortedSet<Integer> ys = xs.add(5);
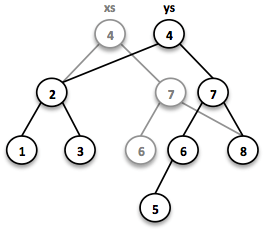 In order to maintain the performance characteristics of a binary search tree it needs to be kept balanced. All paths from the root to a leaf need to have roughly the same length.
In order to maintain the performance characteristics of a binary search tree it needs to be kept balanced. All paths from the root to a leaf need to have roughly the same length.
为了保持二叉搜索树的性能特征,需要保持平衡。 从根到叶子的所有路径都需要具有大致相同的长度。
In Vavr we implemented a binary search tree based on a Red/Black Tree. It uses a specific coloring strategy to keep the tree balanced on inserts and deletes. To read more about this topic please refer to the book Purely Functional Data Structures by Chris Okasaki.
在Vavr中,我们基于红/黑树实现了二叉搜索树. 它使用特定的着色策略来保持树在插入和删除时保持平衡. 要阅读有关此主题的更多信息,请参阅Chris Okasaki的书Purely Functional Data Structures.
1.5. State of the Collections(集合的状态)
Generally we are observing a convergence of programming languages. Good features make it, other disappear. But Java is different, it is bound forever to be backward compatible. That is a strength but also slows down evolution.
通常,我们正在观察编程语言的融合。 好的功能使用它,其他消失。 但是Java是不同的,它永远是向后兼容的。 这是一种力量,但也减缓了进化。
Lambda brought Java and Scala closer together, yet they are still so different. Martin Odersky, the creator of Scala, recently mentioned in his BDSBTB 2015 keynote the state of the Java 8 collections.
Lambda使Java和Scala更加紧密,但它们仍然如此不同. Scala的创建者Martin Odersky最近在他的BDSBTB 2015主题演讲中提到了Java 8集合的状态.
He described Java’s Stream as a fancy form of an Iterator. The Java 8 Stream API is an example of a lifted collection. What it does is to define a computation and link it to a specific collection in another excplicit step.
他将Java的Stream描述为Iterator的一种奇特形式。 Java 8 Stream API是* lifted 集合的一个示例。 它的作用是定义一个计算并将其链接*到另一个重复步骤中的特定集合。
// i + 1
i.prepareForAddition()
.add(1)
.mapBackToInteger(Mappers.toInteger())
This is how the new Java 8 Stream API works. It is a computational layer above the well known Java collections.
这就是新的Java 8 Stream API的工作方式。 它是众所周知的Java集合之上的计算层。
// = ["1", "2", "3"] in Java 8
Arrays.asList(1, 2, 3)
.stream()
.map(Object::toString)
.collect(Collectors.toList())
Vavr is greatly inspired by Scala. This is how the above example should have been in Java 8.
Vavr受到了Scala的极大启发。 这就是上面的例子应该如何在Java 8中。
// = Stream("1", "2", "3") in Vavr
Stream.of(1, 2, 3).map(Object::toString)
Within the last year we put much effort into implementing the Vavr collection library. It comprises the most widely used collection types.
在过去的一年里,我们付出了很多努力来实现Vavr集合库。 它包含最广泛使用的集合类型。
1.5.1. Seq
We started our journey by implementing sequential types. We already described the linked List above. Stream, a lazy linked List, followed. It allows us to process possibly infinite long sequences of elements.
我们通过实现顺序类型开始了我们的旅程 我们已经描述了上面的链表。 流,一个懒惰的链接列表,紧随其后。 它允许我们处理可能无限长的元素序列。
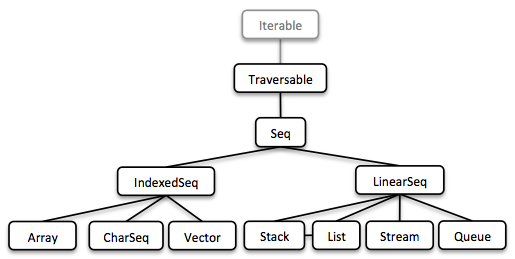 All collections are Iterable and hence could be used in enhanced for-statements.
All collections are Iterable and hence could be used in enhanced for-statements.
所有集合都是可迭代的,因此可以用于增强的for语句。
for (String s : List.of("Java", "Advent")) {
// side effects and mutation
}
We could accomplish the same by internalizing the loop and injecting the behavior using a lambda.
我们可以通过内化循环并使用lambda注入行为来完成相同的操作。
List.of("Java", "Advent").forEach(s -> {
// side effects and mutation
});
Anyway, as we previously saw we prefer expressions that return a value over statements that return nothing. By looking at a simple example, soon we will recognize that statements add noise and divide what belongs together.
无论如何,正如我们之前看到的那样,我们更喜欢表达式返回值而不返回任何语句。 通过一个简单的例子,我们很快就会认识到语句会增加噪音并将所有属性分开。
String join(String... words) {
StringBuilder builder = new StringBuilder();
for(String s : words) {
if (builder.length() > 0) {
builder.append(", ");
}
builder.append(s);
}
return builder.toString();
}
The Vavr collections provide us with many functions to operate on the underlying elements. This allows us to express things in a very concise way.
Vavr集合为我们提供了许多功能来操作底层元素。 这使我们能够以非常简洁的方式表达事物。
String join(String... words) {
return List.of(words)
.intersperse(", ")
.foldLeft(new StringBuilder(), StringBuilder::append)
.toString();
}
Most goals can be accomplished in various ways using Vavr. Here we reduced the whole method body to fluent function calls on a List instance. We could even remove the whole method and directly use our List to obtain the computation result.
大多数目标都可以使用Vavr以各种方式完成。 这里我们将整个方法体简化为List实例上的流畅函数调用。 我们甚至可以删除整个方法并直接使用List来获得计算结果。
List.of(words).mkString(", ");
In a real world application we are now able to drastically reduce the number of lines of code and hence lower the risk of bugs.
在现实世界的应用程序中,我们现在能够大幅减少代码行数,从而降低错误风险。
1.5.2. Set and Map
Sequences are great. But to be complete, a collection library also needs different types of Sets and Maps.
序列很棒。 但要完成,集合库还需要不同类型的集合和映射。
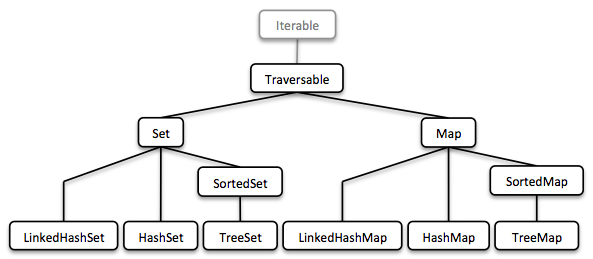 We described how to model sorted Sets with binary tree structures. A sorted Map is nothing else than a sorted Set containing key-value pairs and having an ordering for the keys.
We described how to model sorted Sets with binary tree structures. A sorted Map is nothing else than a sorted Set containing key-value pairs and having an ordering for the keys.
我们描述了如何使用二叉树结构对排序集进行建模。 有序映射只不过是包含键值对的排序集合,并且具有键的排序。
The HashMap implementation is backed by a Hash Array Mapped Trie (HAMT). Accordingly the HashSet is backed by a HAMT containing key-key pairs.
HashMap实现由Hash Array Mapped Trie(HAMT)支持。 因此,HashSet由包含密钥对的HAMT支持。
Our Map does not have a special Entry type to represent key-value pairs. Instead we use Tuple2 which is already part of Vavr. The fields of a Tuple are enumerated.
我们的Map不具有特殊的条目类型来表示键值对。 相反,我们使用已经是Vavr一部分的Tuple2。 列举了元组的字段。
// = (1, "A")
Tuple2<Integer, String> entry = Tuple.of(1, "A");
Integer key = entry._1;
String value = entry._2;
Maps and Tuples are used throughout Vavr. Tuples are inevitable to handle multi-valued return types in a general way.
Vavr中使用了Map和元组。 元组不可避免地以一般方式处理多值返回类型。
// = HashMap((0, List(2, 4)), (1, List(1, 3)))
List.of(1, 2, 3, 4).groupBy(i -> i % 2);
// = List((a, 0), (b, 1), (c, 2))
List.of('a', 'b', 'c').zipWithIndex();
At Vavr, we explore and test our library by implementing the 99 Euler Problems. It is a great proof of concept. Please don’t hesitate to send pull requests.
在Vavr,我们通过实现99 Euler Problems来探索和测试我们的库。 这是一个很好的概念证明。 请不要犹豫,发送拉请求。
2. Getting started
Projects that include Vavr need to target Java 1.8 at minimum.
包含Vavr的项目需要至少以Java 1.8为目标。
The .jar is available at Maven Central.
.jar可在t Maven Central获得。
2.1. Gradle
dependencies {
compile "io.vavr:vavr:0.9.2"
}
2.2. Maven
<dependencies>
<dependency>
<groupId>io.vavr</groupId>
<artifactId>vavr</artifactId>
<version>0.9.2</version>
</dependency>
</dependencies>
2.3. Standalone
Because Vavr does not depend on any libraries (other than the JVM) you can easily add it as standalone .jar to your classpath.
因为Vavr不依赖于任何库(JVM除外),所以可以轻松地将它作为独立的.jar添加到类路径中。
2.4. Snapshots
Developer versions can be found here.
可以在此处找到开发人员版本。
2.4.1. Gradle
Add the additional snapshot repository to your build.gradle:
将快照存储库添加到build.gradle:
repositories {
(...)
maven { url "https://oss.sonatype.org/content/repositories/snapshots" }
}
2.4.2. Maven
Ensure that your ~/.m2/settings.xml contains the following:
确保您的〜/ .m2 / settings.xml包含以下内容:
<profiles>
<profile>
<id>allow-snapshots</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<repositories>
<repository>
<id>snapshots-repo</id>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</profile>
</profiles>
3. Usage Guide
Vavr comes along with well-designed representations of some of the most basic types which apparently are missing or rudimentary in Java: Tuple, Value and λ. In Vavr, everything is built upon these three basic building blocks:
Vavr伴随着一些最基本类型的精心设计,这些类型在Java中显然是缺失或低级的:Tuple, Value and λ。 在Vavr中,一切都建立在这三个基本构建块之上:
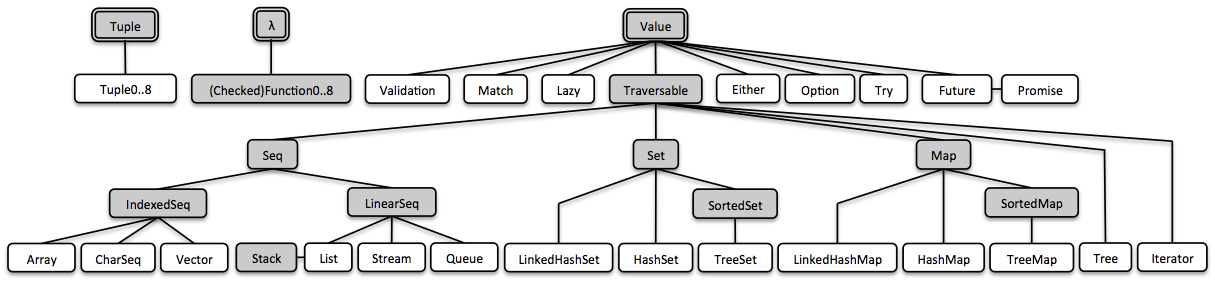
3.1. Tuples(元组)
Java is missing a general notion of tuples. A Tuple combines a fixed number of elements together so that they can be passed around as a whole. Unlike an array or list, a tuple can hold objects with different types, but they are also immutable.
Java缺少元组的一般概念。 元组将固定数量的元素组合在一起,以便它们可以作为一个整体传递。 与数组或列表不同,元组可以保存具有不同类型的对象,但它们也是不可变的。 Tuples are of type Tuple1, Tuple2, Tuple3 and so on. There currently is an upper limit of 8 elements. To access elements of a tuple t, you can use method t._1 to access the first element, t._2 to access the second, and so on.
元组是Tuple1,Tuple2,Tuple3等类型。 目前有8个元素的上限。 要访问元组t的元素,可以使用方法t._1来访问第一个元素,t._2来访问第二个元素,依此类推。
3.1.1. Create a tuple(创建元组)
Here is an example of how to create a tuple holding a String and an Integer:
以下是如何创建包含String和Integer的元组的示例:
// (Java, 8)
Tuple2<String, Integer> java8 = Tuple.of("Java", 8); //(1)
// "Java"
String s = java8._1; //(2)
// 8
Integer i = java8._2; //(3)
- (1) A tuple is created via the static factory method
Tuple.of() 通过静态工厂方法Tuple.of()创建一个元组- (2) Get the 1st element of this tuple.
获得这个元组的第一个元素。- (3) Get the 2nd element of this tuple.
获得这个元组的第二个元素。
3.1.2. Map a tuple component-wise
The component-wise map evaluates a function per element in the tuple, returning another tuple.
分量方式的Map计算元组中每个元素的函数,返回另一个元组。
// (vavr, 1)
Tuple2<String, Integer> that = java8.map(
s -> s.substring(2) + "vr",
i -> i / 8
);
3.1.3. Map a tuple using one mapper
It is also possible to map a tuple using one mapping function.
还可以使用一个映射函数映射元组。
// (vavr, 1)
Tuple2<String, Integer> that = java8.map(
(s, i) -> Tuple.of(s.substring(2) + "vr", i / 8)
);
3.1.4. Transform a tuple
Transform creates a new type based on the tuple’s contents.
Transform根据元组的内容创建一个新类型。
// "vavr 1"
String that = java8.apply(
(s, i) -> s.substring(2) + "vr " + i / 8
);
3.2. Functions
Functional programming is all about values and transformation of values using functions. Java 8 just provides a Function which accepts one parameter and a BiFunction which accepts two parameters. Vavr provides functions up to a limit of 8 parameters. The functional interfaces are of called Function0, Function1, Function2, Function3 and so on. If you need a function which throws a checked exception you can use CheckedFunction1, CheckedFunction2 and so on.
函数式编程是关于使用函数的值和值的转换。 Java 8只提供了一个接受一个参数的Function和一个接受两个参数的BiFunction。 Vavr提供的功能最多可达8个参数。 功能接口称为“Function0,Function1,Function2,Function3”等。 如果需要一个抛出已检查异常的函数,可以使用CheckedFunction1,CheckedFunction2等。 The following lambda expression creates a function to sum two integers:
以下lambda表达式创建一个函数来对两个整数求和:
// sum.apply(1, 2) = 3
Function2<Integer, Integer, Integer> sum = (a, b) -> a + b;
This is a shorthand for the following anonymous class definition:
这是以下匿名类定义的简写:
Function2<Integer, Integer, Integer> sum = new Function2<Integer, Integer, Integer>() {
@Override
public Integer apply(Integer a, Integer b) {
return a + b;
}
};
You can also use the static factory method Function3.of(…) to a create a function from any method reference.
您还可以使用静态工厂方法Function3.of(...)从任何方法引用创建函数。
Function3<String, String, String, String> function3 =
Function3.of(this::methodWhichAccepts3Parameters);
In fact Vavr functional interfaces are Java 8 functional interfaces on steroids. They also provide features like:
事实上,Vavr函数式接口是建造在Java 8的函数式接口上。 它们还提供以下功能:
- Composition 组成
- Lifting 吊装
- Currying 柯里化
- Memoization 记忆化
3.2.1. Composition(组合)
You can compose functions. In mathematics, function composition is the application of one function to the result of another to produce a third function. For instance, the functions f : X → Y and g : Y → Z can be composed to yield a function h: g(f(x)) which maps X → Z. You can use either andThen:
你可以组合函数。 在数学中,函数组合是将一个函数应用于另一个函数以产生第三个函数。 例如,函数f:X→Y和g:Y→Z可以被组合以产生映射X→Z的函数h:g(f(x))。你可以使用andThen`
Function1<Integer, Integer> plusOne = a -> a + 1;
Function1<Integer, Integer> multiplyByTwo = a -> a * 2;
Function1<Integer, Integer> add1AndMultiplyBy2 = plusOne.andThen(multiplyByTwo);
then(add1AndMultiplyBy2.apply(2)).isEqualTo(6);
or compose:
Function1<Integer, Integer> add1AndMultiplyBy2 = multiplyByTwo.compose(plusOne);
then(add1AndMultiplyBy2.apply(2)).isEqualTo(6);
3.2.2. Lifting(提升)
You can lift a partial function into a total function that returns an Option result. The term partial function comes from mathematics. A partial function from X to Y is a function f: X′ → Y, for some subset X′ of X. It generalizes the concept of a function f: X → Y by not forcing f to map every element of X to an element of Y. That means a partial function works properly only for some input values. If the function is called with a disallowed input value, it will typically throw an exception.
您可以将部分函数提升为返回“Option”结果的total函数。 术语部分函数来自数学。 从X到Y的部分函数是函数f:X'→Y,对于X的某个子集X'。它通过不强制f将X的每个元素映射到元素Y来概括函数f:X→Y的概念。 这意味着部分功能仅适用于某些输入值。 如果使用不允许的输入值调用该函数,则通常会抛出异常。
The following method divide is a partial function that only accepts non-zero divisors.
以下方法divide是一个只接受非零除数的部分函数。
Function2<Integer, Integer, Integer> divide = (a, b) -> a / b;
We use lift to turn divide into a total function that is defined for all inputs.
我们使用lift将divide转换为为所有输入定义的总函数。
Function2<Integer, Integer, Option<Integer>> safeDivide = Function2.lift(divide);
// = None
Option<Integer> i1 = safeDivide.apply(1, 0); //(1)
// = Some(2)
Option<Integer> i2 = safeDivide.apply(4, 2); //(2)
- (1) A lifted function returns
Noneinstead of throwing an exception, if the function is invoked with disallowed input values. 如果使用不允许的输入值调用函数,则提升函数返回“无”而不是抛出异常。- (2) A lifted function returns
Some, if the function is invoked with allowed input values. 如果使用允许的输入值调用函数,则提升函数将返回“Some”。
The following method sum is a partial function that only accepts positive input values.
以下方法sum是仅接受正输入值的部分函数。
int sum(int first, int second) {
if (first < 0 || second < 0) {
throw new IllegalArgumentException("Only positive integers are allowed"); //(1)
}
return first + second;
}
- (1) The function
sumthrows anIllegalArgumentExceptionfor negative input values. 函数sum为负输入值抛出IllegalArgumentException。
We may lift the sum method by providing the methods reference.
我们可以通过提供方法参考来解除sum方法。
Function2<Integer, Integer, Option<Integer>> sum = Function2.lift(this::sum);
// = None
Option<Integer> optionalResult = sum.apply(-1, 2); //(1)
- (1) The lifted function catches the
IllegalArgumentExceptionand maps it toNone. 提升函数捕获IllegalArgumentException并将其映射到None。
3.2.3. Partial application(部分申请)
Partial application allows you to derive a new function from an existing one by fixing some values. You can fix one or more parameters, and the number of fixed parameters defines the arity of the new function such that new arity = (original arity - fixed parameters). The parameters are bound from left to right.
部分申请允许您通过固定某些值从现有函数派生新函数。 你可以固定一个或多个参数,固定参数的数量定义新函数的参数数量,使得new arity =(original arity - fixed parameters)。 参数从左到右绑定。
Function2<Integer, Integer, Integer> sum = (a, b) -> a + b;
Function1<Integer, Integer> add2 = sum.apply(2); //(1)
then(add2.apply(4)).isEqualTo(6);
- (1) The first parameter
ais fixed to the value 2.
第一个参数a固定为值2。
This can be demonstrated by fixing the first three parameters of a Function5, resulting in a Function2.
这可以通过固定Function5的前三个参数来演示,从而产生Function2。
Function5<Integer, Integer, Integer, Integer, Integer, Integer> sum = (a, b, c, d, e) -> a + b + c + d + e;
Function2<Integer, Integer, Integer> add6 = sum.apply(2, 3, 1); //(1)
then(add6.apply(4, 3)).isEqualTo(13);
(1) The
a,bandcparameters are fixed to the values 2, 3 and 1 respectively.a,b和c参数分别固定为值2,3和1。
Partial application differs from Currying, as will be explored in the relevant section.
部分申请与Currying不同,将在相关章节中进行探讨。
3.2.4. Currying(柯里化)
Currying is a technique to partially apply a function by fixing a value for one of the parameters, resulting in a Function1function that returns a Function1.
Currying是一种通过固定其中一个参数的值来部分应用函数的技术,从而产生一个返回Function1的Function1函数。
When a Function2 is curried, the result is indistinguishable from the partial application of a Function2 because both result in a 1-arity function.
当Function2被curried时,结果与Function2的partial application无法区分,因为两者都会产生1-arity函数。
Function2<Integer, Integer, Integer> sum = (a, b) -> a + b;
Function1<Integer, Integer> add2 = sum.curried().apply(2); //(1)
then(add2.apply(4)).isEqualTo(6);
- (1) The first parameter
ais fixed to the value 2.
第一个参数a固定为值2。
You might notice that, apart from the use of .curried(), this code is identical to the 2-arity given example in Partial application. With higher-arity functions, the difference becomes clear.
您可能会注意到,除了使用.curried()之外,此代码与Partial application中的2-arity给出示例相同。只是 具有更高的功能,差异变得清晰。
Function3<Integer, Integer, Integer, Integer> sum = (a, b, c) -> a + b + c;
final Function1<Integer, Function1<Integer, Integer>> add2 = sum.curried().apply(2); //(1)
then(add2.apply(4).apply(3)).isEqualTo(9); //(2)
- (1) Note the presence of additional functions in the parameters.
请注意参数中是否存在其他功能。- (2) Further calls to
applyreturns anotherFunction1, apart from the final call.
除了最终调用之外,对apply的进一步调用返回另一个Function1。
3.2.5. Memoization(记忆化)
Memoization is a form of caching. A memoized function executes only once and then returns the result from a cache.
记忆化是一种缓存形式。 memoized函数只执行一次,然后从缓存中返回结果。 The following example calculates a random number on the first invocation and returns the cached number on the second invocation.
以下示例在第一次调用时计算随机数,并在第二次调用时返回缓存的数字。
Function0<Double> hashCache =
Function0.of(Math::random).memoized();
double randomValue1 = hashCache.apply();
double randomValue2 = hashCache.apply();
then(randomValue1).isEqualTo(randomValue2);
3.3. Values
In a functional setting we see a value as a kind of normal form, an expression which cannot be further evaluated. In Java we express this by making the state of an object final and call it immutable.
在函数式设置中,我们将value视为一种普通形式,这是一个无法进一步计算的表达式。 在Java中,我们通过使对象的状态为final并将其称为immutable来表达这一点。
Vavr’s functional Value abstracts over immutable objects. Efficient write operations are added by sharing immutable memory between instances. What we get is thread-safety for free!
Vavr的函数式Value对不可变对象进行抽象。 通过在实例之间共享不可变内存来添加高效的写入操作。 我们免费得到的是线程安全的!
3.3.1. Option
Option is a monadic container type which represents an optional value. Instances of Option are either an instance of Some or the None.
Option是一个monadic(一元的)容器类型,表示可选值。 Option的实例是Some或None的实例。
// optional *value*, no more nulls
Option<T> option = Option.of(...);
If you’re coming to Vavr after using Java’s Optional class, there is a crucial difference. In Optional, a call to .map that results in a null will result in an empty Optional. In Vavr, it would result in a Some(null) that can then lead to a NullPointerException.
如果你在使用Java的Optional类之后来到Vavr,那就有一个至关重要的区别。 在Optional中,调用.map导致null将导致空Optional。 在Vavr中,它会导致Some(null)然后导致NullPointerException。
Using Optional, this scenario is valid.
使用Optional,这种情况是有效的。
Optional<String> maybeFoo = Optional.of("foo"); //(1)
then(maybeFoo.get()).isEqualTo("foo");
Optional<String> maybeFooBar = maybeFoo.map(s -> (String)null) //(2)
.map(s -> s.toUpperCase() + "bar");
then(maybeFooBar.isPresent()).isFalse();
- (1) The option is
Some("foo")
Option的值是Some(“foo”)- (2) The resulting option becomes empty here
结果Option在此处变为空
Using Vavr’s Option, the same scenario will result in a NullPointerException.
使用Vavr的Option,相同的场景将导致NullPointerException。
Option<String> maybeFoo = Option.of("foo"); //(1)
then(maybeFoo.get()).isEqualTo("foo");
try {
maybeFoo.map(s -> (String)null) (2)
.map(s -> s.toUpperCase() + "bar"); (3)
Assert.fail();
} catch (NullPointerException e) {
// this is clearly not the correct approach
}
- (1) The option is
Some("foo")
Option的值是Some(“foo”)- (2) The resulting option is
Some(null)
Option的值是Some(“null”)- (3) The call to
s.toUpperCase()is invoked on anull
对s.toUpperCase()的调用是在null上调用的
This seems like Vavr’s implementation is broken, but in fact it’s not - rather, it adheres to the requirement of a monad to maintain computational context when calling .map. In terms of an Option, this means that calling .map on a Some will result in a Some, and calling .map on a None will result in a None. In the Java Optional example above, that context changed from a Some to a None.
这看起来像Vavr的实现被破坏了,但事实上并非如此 - 相反,它坚持monad在调用.map时维护计算上下文的要求。 就Option来说,这意味着在Some上调用.map将导致Some,在None上调用.map将导致None。 在上面的JavaOptional示例中,该上下文从Some变为None。
This may seem to make Option useless, but it actually forces you to pay attention to possible occurrences of null and deal with them accordingly instead of unknowingly accepting them. The correct way to deal with occurrences of null is to use flatMap.
这似乎使Option无用,但它实际上迫使你注意可能出现的null并相应地处理它们而不是在不知不觉中接受它们。 处理null出现的正确方法是使用flatMap。
Option<String> maybeFoo = Option.of("foo"); //(1)
then(maybeFoo.get()).isEqualTo("foo");
Option<String> maybeFooBar = maybeFoo.map(s -> (String)null) //(2)
.flatMap(s -> Option.of(s) //(3)
.map(t -> t.toUpperCase() + "bar"));
then(maybeFooBar.isEmpty()).isTrue();
- (1) The option is
Some("foo")- (2) The resulting option is
Some(null)- (3)
s, which isnull, becomesNone
Alternatively, move the .flatMap to be co-located with the the possibly null value.
或者,将.flatMap移动到与可能的'null`值位于同一位置。
Option<String> maybeFoo = Option.of("foo"); //(1)
then(maybeFoo.get()).isEqualTo("foo");
Option<String> maybeFooBar = maybeFoo.flatMap(s -> Option.of((String)null)) (2)
.map(s -> s.toUpperCase() + "bar");
then(maybeFooBar.isEmpty()).isTrue();
- (1) The option is
Some("foo")- (2) The resulting option is
None
This is explored in more detail on the Vavr blog.
这在Vavr博客上有更详细的探讨。
3.3.2. Try
Try is a monadic container type which represents a computation that may either result in an exception, or return a successfully computed value. It’s similar to, but semantically different from Either. Instances of Try, are either an instance of Success or Failure.
Try是一个monadic(一元的)容器类型,表示可能导致异常或返回成功计算值的计算。 它与“Either”类似,但在语义上不同。 Try的实例是“成功”或“失败”的实例。
// no need to handle exceptions
Try.of(() -> bunchOfWork()).getOrElse(other);
import static io.vavr.API.*; // $, Case, Match
import static io.vavr.Predicates.*; // instanceOf
A result = Try.of(this::bunchOfWork)
.recover(x -> Match(x).of(
Case($(instanceOf(Exception_1.class)), t -> somethingWithException(t)),
Case($(instanceOf(Exception_2.class)), t -> somethingWithException(t)),
Case($(instanceOf(Exception_n.class)), t -> somethingWithException(t))
))
.getOrElse(other);
3.3.3. Lazy
Lazy is a monadic container type which represents a lazy evaluated value. Compared to a Supplier, Lazy is memoizing, i.e. it evaluates only once and therefore is referentially transparent.
Lazy是一个monadic(一元的)容器类型,表示惰性求值。 与Supplier相比,Lazy正在进行记忆,即它仅评估一次,因此是引用透明的。
Lazy<Double> lazy = Lazy.of(Math::random);
lazy.isEvaluated(); // = false
lazy.get(); // = 0.123 (random generated)
lazy.isEvaluated(); // = true
lazy.get(); // = 0.123 (memoized)
Since version 2.0.0 you may also create a real lazy value (works only with interfaces):
从版本2.0.0开始,您还可以创建一个真正的延迟值(仅适用于接口):
CharSequence chars = Lazy.val(() -> "Yay!", CharSequence.class);
3.3.4. Either
Either represents a value of two possible types. An Either is either a Left or a Right. If the given Either is a Right and projected to a Left, the Left operations have no effect on the Right value. If the given Either is a Left and projected to a Right, the Right operations have no effect on the Left value. If a Left is projected to a Left or a Right is projected to a Right, the operations have an effect.
Eitjer代表两种可能类型的值。 一个要么是Left,要么是Right。 如果给定的Either是Right并且投影到Left,则Left操作对Right值没有影响。 如果给定的Either是Left并且投影到Right,则Right操作对Left值没有影响。 如果将Left投影到Left或Right投影到Right,则操作会生效。
Example: A compute() function, which results either in an Integer value (in the case of success) or in an error message of type String (in the case of failure). By convention the success case is Right and the failure is Left.
示例:compute()函数,其结果为Integer值(在成功的情况下)或在String类型的错误消息中(在失败的情况下)。 按照惯例,成功案例是正确的,失败是左派。
Either<String,Integer> value = compute().right().map(i -> i * 2).toEither();
If the result of compute() is Right(1), the value is Right(2).
如果compute()的结果为Right(1),则值为Right(2)。
If the result of compute() is Left("error"), the value is Left("error").
如果compute()的结果为Left(“error”),则值为Left(“error”)。
3.3.5. Future
A Future is a computation result that becomes available at some point. All operations provided are non-blocking. The underlying ExecutorService is used to execute asynchronous handlers, e.g. via onComplete(…).
Future是在某些时候可用的计算结果。 提供的所有操作都是非阻塞的。 底层的ExecutorService用于执行异步处理程序,例如 通过onComplete(...)。
A Future has two states: pending and completed.
Future有两种状态:待定和完成。
Pending: The computation is ongoing. Only a pending future may be completed or cancelled.
Pending: 计算正在进行中。 只有未决定的future可能会完成或取消。
Completed: The computation finished successfully with a result, failed with an exception or was cancelled.
**Completed:**计算结果成功完成,异常失败或被取消。
Callbacks may be registered on a Future at each point of time. These actions are performed as soon as the Future is completed. An action which is registered on a completed Future is immediately performed. The action may run on a separate Thread, depending on the underlying ExecutorService. Actions which are registered on a cancelled Future are performed with the failed result.
可以在每个时间点在Future上注册回调。 一旦Future完成,就会执行这些操作。 立即执行在已完成的Future上注册的动作。 该操作可以在单独的Thread上运行,具体取决于底层的ExecutorService。 在取消的Future上注册的操作将使用失败的结果执行。
// future *value*, result of an async calculation
Future<T> future = Future.of(...);
3.3.6. Validation
The Validation control is an applicative functor and facilitates accumulating errors. When trying to compose Monads, the combination process will short circuit at the first encountered error. But 'Validation' will continue processing the combining functions, accumulating all errors. This is especially useful when doing validation of multiple fields, say a web form, and you want to know all errors encountered, instead of one at a time.
Validation控制是一个applicative functor,有助于累积错误。 当尝试组合Monads时,组合过程将在第一次遇到错误时短路。 但'Validation'将继续处理组合功能,累积所有错误。 这在对多个字段(例如Web表单)进行验证时非常有用,并且您希望知道遇到的所有错误,而不是一次一个。
Example: We get the fields 'name' and 'age' from a web form and want to create either a valid Person instance, or return the list of validation errors.
示例:我们从Web表单中获取字段'name'和'age',并希望创建有效的Person实例,或者返回验证错误列表。
PersonValidator personValidator = new PersonValidator();
// Valid(Person(John Doe, 30))
Validation<Seq<String>, Person> valid = personValidator.validatePerson("John Doe", 30);
// Invalid(List(Name contains invalid characters: '!4?', Age must be greater than 0))
Validation<Seq<String>, Person> invalid = personValidator.validatePerson("John? Doe!4", -1);
A valid value is contained in a Validation.Valid instance, a list of validation errors is contained in a Validation.Invalid instance.
有效值包含在Validation.Valid实例中,验证错误列表包含在Validation.Invalid实例中。
The following validator is used to combine different validation results to one Validation instance.
以下validator用于将不同的验证结果组合到一个“Validation”实例。
class PersonValidator {
private static final String VALID_NAME_CHARS = "[a-zA-Z ]";
private static final int MIN_AGE = 0;
public Validation<Seq<String>, Person> validatePerson(String name, int age) {
return Validation.combine(validateName(name), validateAge(age)).ap(Person::new);
}
private Validation<String, String> validateName(String name) {
return CharSeq.of(name).replaceAll(VALID_NAME_CHARS, "").transform(seq -> seq.isEmpty()
? Validation.valid(name)
: Validation.invalid("Name contains invalid characters: '"
+ seq.distinct().sorted() + "'"));
}
private Validation<String, Integer> validateAge(int age) {
return age < MIN_AGE
? Validation.invalid("Age must be at least " + MIN_AGE)
: Validation.valid(age);
}
}
If the validation succeeds, i.e. the input data is valid, then an instance of Person is created of the given fields name and age.
如果验证成功,即输入数据有效,则创建给定字段'name'和'age'的'Person'实例。
class Person {
public final String name;
public final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person(" + name + ", " + age + ")";
}
}
3.4. Collections
Much effort has been put into designing an all-new collection library for Java which meets the requirements of functional programming, namely immutability.
为设计一个全新的Java集合库已经付出了很多努力,它满足了函数式编程的要求,即不变性。
Java’s Stream lifts a computation to a different layer and links to a specific collection in another explicit step. With Vavr we don’t need all this additional boilerplate.
Java Stream将计算提升到不同的层,并在另一个显式步骤中链接到特定的集合。 使用Vavr,我们不需要所有这些额外的样板。
The new collections are based on java.lang.Iterable, so they leverage the sugared iteration style.
新集合基于java.lang.Iterable,因此它们利用了加糖的迭代样式。
// 1000 random numbers
for (double random : Stream.continually(Math::random).take(1000)) {
...
}
TraversableOnce has a huge amount of useful functions to operate on the collection. Its API is similar to java.util.stream.Stream but more mature.TraversableOnce具有大量有用的功能来操作集合。 它的API类似于java.util.stream.Stream,但更成熟。
3.4.1. List
Vavr’s List is an immutable linked list. Mutations create new instances. Most operations are performed in linear time. Consequent operations are executed one by one.
Vavr的List是一个不可变的链表。 突变创建新实例。 大多数操作都是以线性时间执行的。 后续操作逐个执行。
Java 8
Arrays.asList(1, 2, 3).stream().reduce((i, j) -> i + j);
IntStream.of(1, 2, 3).sum();
Vavr
// io.vavr.collection.List
List.of(1, 2, 3).sum();
3.4.2. Stream
The io.vavr.collection.Stream implementation is a lazy linked list. Values are computed only when needed. Because of its laziness, most operations are performed in constant time. Operations are intermediate in general and executed in a single pass.io.vavr.collection.Stream实现是一个惰性链表。 仅在需要时计算值。 由于它的懒惰,大多数操作是在恒定的时间内执行的。 操作通常是中间的,并且一次性执行。
The stunning thing about streams is that we can use them to represent sequences that are (theoretically) infinitely long.
关于Streams的惊人之处在于我们可以使用它们来表示(理论上)无限长的序列。
// 2, 4, 6, ...
Stream.from(1).filter(i -> i % 2 == 0);
3.4.3. Performance Characteristics(性能特点)
| head() | tail() | get(int) | update(int, T) | prepend(T) | append(T) | |
|---|---|---|---|---|---|---|
| Array | const | linear | const | const | linear | linear |
| CharSeq | const | linear | const | linear | linear | linear |
| Iterator | const | const | — | — | — | — |
| List | const | const | linear | linear | const | linear |
| Queue | const | consta | linear | linear | const | const |
| PriorityQueue | log | log | — | — | log | log |
| Stream | const | const | linear | linear | constlazy | constlazy |
| Vector | consteff | consteff | const eff | const eff | const eff | const eff |
| contains/Key | add/put | remove | min | |
|---|---|---|---|---|
| HashMap | consteff | consteff | consteff | linear |
| HashSet | consteff | consteff | consteff | linear |
| LinkedHashMap | consteff | consteff | linear | linear |
| LinkedHashSet | consteff | consteff | linear | linear |
| Tree | log | log | log | log |
| TreeMap | log | log | log | log |
| TreeSet | log | log | log | log |
Legend(说明):
- const — constant time 恒定时间
- consta — amortized constant time, few operations may take longer 摊销的时间很长,很少有业务可能需要更长时间
- consteff — effectively constant time, depending on assumptions like distribution of hash keys 有效的恒定时间,取决于散列键分布等假设
- constlazy — lazy constant time, the operation is deferred 懒惰的常量时间,操作被推迟
- log — logarithmic time 对数时间
- linear — linear time 线性时间
3.5. Property Checking(属性检查)
Property checking (also known as property testing) is a truly powerful way to test properties of our code in a functional way. It is based on generated random data, which is passed to a user defined check function.
属性检查(也称为属性测试)是一种以功能方式测试代码属性的真正强大的方法。 它基于生成的随机数据,传递给用户定义的检查功能。
Vavr has property testing support in its io.vavr:vavr-test module, so make sure to include that in order to use it in your tests.
Vavr在其io.vavr:vavr-test模块中具有属性测试支持,因此请确保包含它以便在测试中使用它。
Arbitrary<Integer> ints = Arbitrary.integer();
// square(int) >= 0: OK, passed 1000 tests.
Property.def("square(int) >= 0")
.forAll(ints)
.suchThat(i -> i * i >= 0)
.check()
.assertIsSatisfied();
Generators of complex data structures are composed of simple generators.
复杂数据结构的生成器由简单的生成器组成。
3.6. Pattern Matching(模式匹配)
Scala has native pattern matching, one of the advantages over plain Java. The basic syntax is close to Java’s switch:
Scala具有本机模式匹配,是plain Java的优势之一。 基本语法接近Java的开关:
val s = i match {
case 1 => "one"
case 2 => "two"
case _ => "?"
}
Notably match is an expression, it yields a result. Furthermore it offers
值得注意的是* match *是一个表达式,它产生一个结果。 此外,它提供
- named parameters
case i: Int ⇒ "Int " + i命名参数case i: Int ⇒ "Int " + i - object deconstruction
case Some(i) ⇒ i对象解构case Some(i) ⇒ i - guards
case Some(i) if i > 0 ⇒ "positive " + i守护case Some(i) if i > 0 ⇒ "positive " + i - multiple conditions
case "-h" | "--help" ⇒ displayHelp多个条件case"-h"| " - help"⇒displayHelp - compile-time checks for exhaustiveness 编译时检查详尽无遗
Pattern matching is a great feature that saves us from writing stacks of if-then-else branches. It reduces the amount of code while focusing on the relevant parts.
模式匹配是一个很好的功能,可以使我们免于编写if-then-else分支的堆栈。 它在关注相关部分的同时减少了代码量。
3.6.1. The Basics of Match for Java(Java的匹配基础知识)
Vavr provides a match API that is close to Scala’s match. It is enabled by adding the following import to our application:
Vavr提供了一个接近Scala的MatchAPI。 通过将以下导入添加到我们的应用程序来启用它:
import static io.vavr.API.*;
Having the static methods Match, Case and the atomic patterns * 拥有静态方法Match*,Case和atomic patterns
$()- wildcard pattern 通配符模式$(value)- equals pattern 等于模式$(predicate)- conditional pattern 条件模式
in scope, the initial Scala example can be expressed like this:
在范围内,最初的Scala示例可以表示如下:
String s = Match(i).of(
Case($(1), "one"),
Case($(2), "two"),
Case($(), "?")
);
We use uniform upper-case method names because 'case' is a keyword in Java. This makes the API special. 我们使用统一的大写方法名称,因为'case'是Java中的关键字。 这使API变得特别。
Exhaustiveness(全面性)
The last wildcard pattern $() saves us from a MatchError which is thrown if no case matches.
最后一个通配符模式$()将我们从MatchError(如果没有大小写匹配则抛出它)中拯救出来。
Because we can’t perform exhaustiveness checks like the Scala compiler, we provide the possibility to return an optional result:
因为我们不能像Scala编译器那样执行穷举检查,所以我们提供了返回可选结果的可能性:
Option<String> s = Match(i).option(
Case($(0), "zero")
);
Syntactic Sugar(句法糖)
As already shown, Case allows to match conditional patterns.
如图所示,Case允许匹配条件模式。
Case($(predicate), ...)
Vavr offers a set of default predicates.
Vavr提供了一组默认谓词。
import static io.vavr.Predicates.*;
These can be used to express the initial Scala example as follows:
这些可用于表示初始Scala示例,如下所示:
String s = Match(i).of(
Case($(is(1)), "one"),
Case($(is(2)), "two"),
Case($(), "?")
);
Multiple Conditions(多个条件)
We use the isIn predicate to check multiple conditions:
我们使用isIn谓词来检查多个条件:
Case($(isIn("-h", "--help")), ...)
Performing Side-Effects(执行副作用)
Match acts like an expression, it results in a value. In order to perform side-effects we need to use the helper function runwhich returns Void:
匹配就像一个表达式,它会产生一个值。 为了执行副作用,我们需要使用辅助函数runwhich返回Void:
Match(arg).of(
Case($(isIn("-h", "--help")), o -> run(this::displayHelp)),
Case($(isIn("-v", "--version")), o -> run(this::displayVersion)),
Case($(), o -> run(() -> {
throw new IllegalArgumentException(arg);
}))
);
runis used to get around ambiguities and becausevoidisn’t a valid return value in Java.run用于解决歧义,因为void不是Java中的有效返回值。
Caution: run must not be used as direct return value, i.e. outside of a lambda body:
警告: run不能用作直接返回值,即在lambda体外:
// Wrong!
Case($(isIn("-h", "--help")), run(this::displayHelp))
Otherwise the Cases will be eagerly evaluated before the patterns are matched, which breaks the whole Match expression. Instead we use it within a lambda body:
否则,在模式匹配之前,将会先执行run,这会打破整个匹配表达式。 相反,我们在lambda体内使用它:
// Ok
Case($(isIn("-h", "--help")), o -> run(this::displayHelp))
As we can see, run is error prone if not used right. Be careful. We consider deprecating it in a future release and maybe we will also provide a better API for performing side-effects.
我们可以看到,如果没有正确使用,run很容易出错。 小心。 我们考虑在将来的版本中弃用它,也许我们还会为执行副作用提供更好的API。
Named Parameters(命名参数)
Vavr leverages lambdas to provide named parameters for matched values.
Vavr利用lambdas为匹配值提供命名参数。
Number plusOne = Match(obj).of(
Case($(instanceOf(Integer.class)), i -> i + 1),
Case($(instanceOf(Double.class)), d -> d + 1),
Case($(), o -> { throw new NumberFormatException(); })
);
So far we directly matched values using atomic patterns. If an atomic pattern matches, the right type of the matched object is inferred from the context of the pattern.
到目前为止,我们使用原子模式直接匹配值。 如果原子模式能匹配,则从模式的上下文推断出匹配对象的正确类型。
Next, we will take a look at recursive patterns that are able to match object graphs of (theoretically) arbitrary depth.
接下来,我们将看一下能够匹配(理论上)任意深度的对象图的递归模式。
Object Decomposition(对象分解)
In Java we use constructors to instantiate classes. We understand object decomposition as destruction of objects into their parts.
在Java中,我们使用构造函数来实例化类。 我们理解object decomposition作为对象的破坏到它们的部分。
While a constructor is a function which is applied to arguments and returns a new instance, a deconstructor is a function which takes an instance and returns the parts. We say an object is unapplied.
虽然构造函数是一个function,它applied参数并返回一个新实例,但解构函数是一个接受实例并返回零件的函数。 我们说对象是unapplied。
Object destruction is not necessarily a unique operation. For example, a LocalDate can be decomposed to
对象破坏不一定是唯一的操作。 例如,可以将LocalDate分解为
- the year, month and day components 年,月,日组成部分
- the long value representing the epoch milliseconds of the corresponding Instant 表示相应Instant的纪元毫秒的long值
- etc. 等等.
3.6.2. Patterns(模式)
In Vavr we use patterns to define how an instance of a specific type is deconstructed. These patterns can be used in conjunction with the Match API.
在Vavr中,我们使用模式来定义如何解构特定类型的实例。 这些模式可以与Match API结合使用。
Predefined Patterns(预定义模式)
For many Vavr types there already exist match patterns. They are imported via
对于许多Vavr类型,已经存在匹配模式。 它们是通过引进
import static io.vavr.Patterns.*;
For example we are now able to match the result of a Try:
例如,我们现在能够匹配Try的结果:
Match(_try).of(
Case($Success($()), value -> ...),
Case($Failure($()), x -> ...)
);
A first prototype of Vavr’s Match API allowed to extract a user-defined selection of objects from a match pattern. Without proper compiler support this isn’t practicable because the number of generated methods exploded exponentially. The current API makes the compromise that all patterns are matched but only the root patterns are decomposed.
Vavr的Match API的第一个原型允许从匹配模式中提取用户定义的对象选择。 如果没有适当的编译器支持,这是不切实际的,因为生成的方法的数量呈指数级增长。 当前的API做出了妥协,即所有模式都匹配,但只有根模式被分解。
Match(_try).of(
Case($Success(Tuple2($("a"), $())), tuple2 -> ...),
Case($Failure($(instanceOf(Error.class))), error -> ...)
);
Here the root patterns are Success and Failure. They are decomposed to Tuple2 and Error, having the correct generic types.
根模式是成功和失败。 它们被分解为Tuple2和Error,具有正确的泛型类型。
Deeply nested types are inferred according to the Match argument and not according to the matched patterns.
深度嵌套类型根据Match参数推断,not根据匹配模式推断。
User-Defined Patterns(用户定义的模式)
It is essential to be able to unapply arbitrary objects, including instances of final classes. Vavr does this in a declarative style by providing the compile time annotations @Patterns and @Unapply.
必须能够取消应用任意对象,包括最终类的实例。 Vavr通过提供编译时注释@ Patterns和@Unapply来以声明式方式执行此操作。
To enable the annotation processor the artifact vavr-match needs to be added as project dependency. 要启用注释处理器,需要将工件vavr-match添加为项目依赖项。
Note: Of course the patterns can be implemented directly without using the code generator. For more information take a look at the generated source.
注意:当然可以直接实现模式而无需使用代码生成器。 有关更多信息,请查看生成的源。
import io.vavr.match.annotation.*;
@Patterns
class My {
@Unapply
static <T> Tuple1<T> Optional(java.util.Optional<T> optional) {
return Tuple.of(optional.orElse(null));
}
}
The annotation processor places a file MyPatterns in the same package (by default in target/generated-sources). Inner classes are also supported. Special case: if the class name is $, the generated class name is just Patterns, without prefix.
注释处理器将文件MyPatterns放在同一个包中(默认情况下,在target/generated-sources中)。 内部类也受支持。 特殊情况:如果类名是$,则生成的类名称只是Patterns,没有前缀。
Guards(守护)
Now we are able to match Optionals using guards.
现在我们可以使用guards匹配Optionals。
Match(optional).of(
Case($Optional($(v -> v != null)), "defined"),
Case($Optional($(v -> v == null)), "empty")
);
The predicates could be simplified by implementing isNull and isNotNull.
通过实现isNull和isNotNull可以简化谓词。
And yes, extracting null is weird. Instead of using Java’s Optional give Vavr’s Option a try!
是的,提取null是很奇怪的。 不要使用Java的Optional来试试Vavr的选项!
Match(option).of(
Case($Some($()), "defined"),
Case($None(), "empty")
);
4. License(许可)
Copyright 2014-2018 Vavr, http://vavr.io
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.