参考:
https://www.cnblogs.com/developer_chan/p/9247185.html
https://www.cnblogs.com/chafanbusi/p/10647471.html
https://blog.csdn.net/fly_miqiqi/article/details/90348800
https://blog.csdn.net/dc2222333/article/details/78234649
MySQL高级知识(十六)——小表驱动大表
前言:本来小表驱动大表的知识应该在前面就讲解的,但是由于之前并没有学习数据批量插入,因此将其放在这里。在查询的优化中永远小表驱动大表。
1.为什么要小表驱动大表呢
类似循环嵌套
for(int i=5;.......)
{
for(int j=1000;......)
{}
}
如果小的循环在外层,对于数据库连接来说就只连接5次,进行5000次操作,如果1000在外,则需要进行1000次数据库连接,从而浪费资源,增加消耗。这就是为什么要小表驱动大表。
2.数据准备
根据MySQL高级知识(十)——批量插入数据脚本中的相应步骤在tb_dept_bigdata表中插入100条数据,在tb_emp_bigdata表中插入5000条数据。
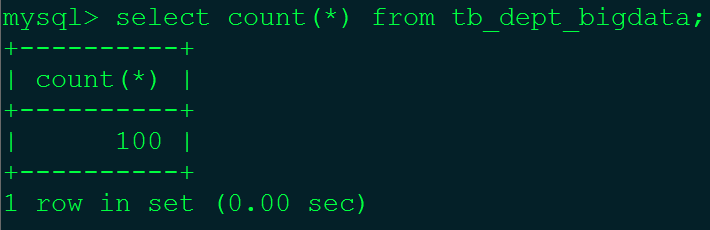
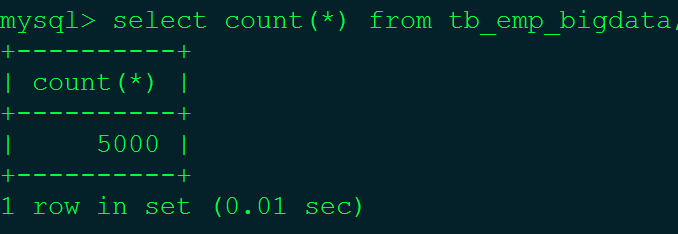
注:100个部门,5000个员工。tb_dept_bigdata(小表),tb_emp_bigdata(大表)。
3.案例演示
①当B表的数据集小于A表数据集时,用in优于exists。
select *from tb_emp_bigdata A where A.deptno in (select B.deptno from tb_dept_bigdata B)
B表为tb_dept_bigdata:100条数据,A表tb_emp_bigdata:5000条数据。
用in的查询时间为:

将上面sql转换成exists:
select *from tb_emp_bigdata A where exists(select 1 from tb_dept_bigdata B where B.deptno=A.deptno);
用exists的查询时间:

经对比可看到,在B表数据集小于A表的时候,用in要优于exists,当前的数据集并不大,所以查询时间相差并不多。
②当A表的数据集小于B表的数据集时,用exists优于in。
select *from tb_dept_bigdata A where A.deptno in(select B.deptno from tb_emp_bigdata B);
用in的查询时间为:

将上面sql转换成exists:
select *from tb_dept_bigdata A where exists(select 1 from tb_emp_bigdata B where B.deptno=A.deptno);
用exists的查询时间:

由于数据量并不是很大,因此对比并不是难么的强烈。
附上视频的结论截图:

4.总结
下面结论都是针对in或exists的。
in后面跟的是小表,exists后面跟的是大表。
简记:in小,exists大。
对于exists
select .....from table where exists(subquery);
可以理解为:将主查询的数据放入子查询中做条件验证,根据验证结果(true或false)来决定主查询的数据是否得以保留。
by Shawn Chen,2018.6.30日,下午。
相关内容
MySql 小表驱动大表
在了解之前要先了解对应语法 in 与 exist。
|
1
2
3
|
IN:select * from A where A.id in (select B.id from B) |
in后的括号的表达式结果要求先输出一列字段。与之前的搜索字段匹配,匹配到相同则返回对应行。
mysql的执行顺序是先执行子查询,然后执行主查询,用子查询的结果按条匹配主查询。
|
1
2
3
|
EXIST:select * from A where exists(select * from B where B.id= A.id) |
exist后的括号里则无输出要求,exist判断后面的结果集中有没有行,有行则返回外层查询对应的行。
ps所以exist还可以这样写: 用常量替换* ,反正是判断有没有行,不需要实际传回的数据。
select * from A where exist(select 1 from B where B.id= A.id)
mysql的执行顺序是先执行主查询,将主查询的数据放在子查询中做条件验证。
大体看来貌似exist的执行效率比in低,但其实exists子查询在底层做了优化,会忽略select清单,也并不会对每条数据进行对比。
比如这里有两张表
|
1
2
3
|
+--------+----------+| A.id | A.name | //500行+--------+----------+ |
|
1
2
3
|
+--------+----------+| B.id | B.name | //5000行+--------+----------+ |
在查询中最好使用小表驱动大表,因为在外层表循环内层的时候,会锁定外层表,如果大表在外,会锁定5k次 。
如果要求查询所有id相同的Aname 有两种查询方式
|
1
2
3
|
1.select A.name from A where A.id in(select B.id from B)2.select A.name from A where exists(select 1 from B where A.id = B.id) |
1.由B表驱动A表 会先执行子查询 大表驱动小表
2.由A表驱动B表 会先执行主查询 小表驱动大表
如果需求变为 查询所有id相同的Bname
|
1
2
3
|
1.select B.name from B where B.id in(select A.id from B)2.select B.name from B where exists(select 1 from A where A.id = B.id) |
1.小表驱动大表
2.大表驱动小表
小表驱动大表
1. 驱动表的定义

当进行多表连接查询时, [驱动表] 的定义为:
1)指定了过滤条件时,满足查询条件的记录行数少的表为[驱动表]
2)未指定过滤条件时,行数少的表为[驱动表](Important!)
2. 为何要 小表驱动大表??
通常来讲,不管Oracle还是Mysql,优化的目标都是尽可能的减少关联的 循环次数,保证小表驱动大表
例: user表10000条数据,class表20条数据
select * from user u left join class c u.userid=c.userid
这样则需要用user表循环10000次才能查询出来,而如果用class表驱动user表则只需要循环20次就能查询出来
分析:不管大表是驱动表还是小表是驱动表,比较次数永远是10000*20次啊???
小表驱动大表优势在哪???
优势在于: 1. 大表具有索引:查询大表时间是O(Log n)
2. 大表全表扫描:磁盘块查询速度快
了解MySQL联表查询中的驱动表,优化查询,以小表驱动大表
为什么要用小表驱动大表
1、驱动表的定义
当进行多表连接查询时, [驱动表] 的定义为:
1)指定了联接条件时,满足查询条件的记录行数少的表为[驱动表]
2)未指定联接条件时,行数少的表为[驱动表](Important!)
忠告:如果你搞不清楚该让谁做驱动表、谁 join 谁,请让 MySQL 运行时自行判断
既然“未指定联接条件时,行数少的表为[驱动表]”了,而且你也对自己写出的复杂的 Nested Loop Join 不太有把握(如下面的实例所示),就别指定谁 left/right join 谁了,请交给 MySQL优化器 运行时决定吧。
如果您对自己特别有信心
2、mysql关联查询的概念:
MySQL 表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。
例: user表10000条数据,class表20条数据
select * from user u left join class c u.userid=c.userid
这样则需要用user表循环10000次才能查询出来,而如果用class表驱动user表则只需要循环20次就能查询出来
例:
select * from class c left join user u c.userid=u.userid
小结果集驱动大结果集
de.cel 在2012年总结说,不管是你,还是 MySQL,优化的目标是尽可能减少JOIN中Nested Loop的循环次数。
以此保证:永远用小结果集驱动大结果集(Important)!