阻塞队列
参考:
http://www.cnblogs.com/dolphin0520/p/3932906.html
http://endual.iteye.com/blog/1412212
https://blog.csdn.net/javazejian/article/details/77410889?locationNum=1&fps=1
https://blog.csdn.net/fuyuwei2015/article/details/72716753
http://ifeve.com/java-blocking-queue/
在前面我们接触的队列都是非阻塞队列,比如PriorityQueue、LinkedList(LinkedList是双向链表,它实现了Dequeue接口)。
使用非阻塞队列的时候有一个很大问题就是:它不会对当前线程产生阻塞,那么在面对类似消费者-生产者的模型时,就必须额外地实现同步策略以及线程间唤醒策略,这个实现起来就非常麻烦。但是有了阻塞队列就不一样了,它会对当前线程产生阻塞,比如一个线程从一个空的阻塞队列中取元素,此时线程会被阻塞直到阻塞队列中有了元素。当队列中有元素后,被阻塞的线程会自动被唤醒(不需要我们编写代码去唤醒)。这样提供了极大的方便性。
本文先讲述一下java.util.concurrent包下提供主要的几种阻塞队列,然后分析了阻塞队列和非阻塞队列的中的各个方法,接着分析了阻塞队列的实现原理,最后给出了一个实际例子和几个使用场景。
一.几种主要的阻塞队列
二.阻塞队列中的方法 VS 非阻塞队列中的方法
三.阻塞队列的实现原理
四.示例和使用场景
若有不正之处请多多谅解,并欢迎批评指正。
请尊重作者劳动成果,转载请标明原文链接:
http://www.cnblogs.com/dolphin0520/p/3932906.html
一.几种主要的阻塞队列
自从Java 1.5之后,在java.util.concurrent包下提供了若干个阻塞队列,主要有以下几个:
ArrayBlockingQueue:基于数组实现的一个阻塞队列,在创建ArrayBlockingQueue对象时必须制定容量大小。并且可以指定公平性与非公平性,默认情况下为非公平的,即不保证等待时间最长的队列最优先能够访问队列。
LinkedBlockingQueue:基于链表实现的一个阻塞队列,在创建LinkedBlockingQueue对象时如果不指定容量大小,则默认大小为Integer.MAX_VALUE。
PriorityBlockingQueue:以上2种队列都是先进先出队列,而PriorityBlockingQueue却不是,它会按照元素的优先级对元素进行排序,按照优先级顺序出队,每次出队的元素都是优先级最高的元素。注意,此阻塞队列为无界阻塞队列,即容量没有上限(通过源码就可以知道,它没有容器满的信号标志),前面2种都是有界队列。
DelayQueue:基于PriorityQueue,一种延时阻塞队列,DelayQueue中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。DelayQueue也是一个无界队列,因此往队列中插入数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。
二.阻塞队列中的方法 VS 非阻塞队列中的方法
1.非阻塞队列中的几个主要方法:
add(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则会抛出异常;
remove():移除队首元素,若移除成功,则返回true;如果移除失败(队列为空),则会抛出异常;
offer(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则返回false;
poll():移除并获取队首元素,若成功,则返回队首元素;否则返回null;
peek():获取队首元素,若成功,则返回队首元素;否则返回null
对于非阻塞队列,一般情况下建议使用offer、poll和peek三个方法,不建议使用add和remove方法。因为使用offer、poll和peek三个方法可以通过返回值判断操作成功与否,而使用add和remove方法却不能达到这样的效果。注意,非阻塞队列中的方法都没有进行同步措施。
2.阻塞队列中的几个主要方法:
阻塞队列包括了非阻塞队列中的大部分方法,上面列举的5个方法在阻塞队列中都存在,但是要注意这5个方法在阻塞队列中都进行了同步措施。除此之外,阻塞队列提供了另外4个非常有用的方法:
put(E e)
take()
offer(E e,long timeout, TimeUnit unit)
poll(long timeout, TimeUnit unit)
put方法用来向队尾存入元素,如果队列满,则等待;
take方法用来从队首取元素,如果队列为空,则等待;
offer方法用来向队尾存入元素,如果队列满,则等待一定的时间,当时间期限达到时,如果还没有插入成功,则返回false;否则返回true;
poll方法用来从队首取元素,如果队列空,则等待一定的时间,当时间期限达到时,如果取到,则返回null;否则返回取得的元素;
三.阻塞队列的实现原理
前面谈到了非阻塞队列和阻塞队列中常用的方法,下面来探讨阻塞队列的实现原理,本文以ArrayBlockingQueue为例,其他阻塞队列实现原理可能和ArrayBlockingQueue有一些差别,但是大体思路应该类似,有兴趣的朋友可自行查看其他阻塞队列的实现源码。
首先看一下ArrayBlockingQueue类中的几个成员变量:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class ArrayBlockingQueue<E> extends AbstractQueue<E>implements BlockingQueue<E>, java.io.Serializable {private static final long serialVersionUID = -817911632652898426L;/** The queued items */private final E[] items;/** items index for next take, poll or remove */private int takeIndex;/** items index for next put, offer, or add. */private int putIndex;/** Number of items in the queue */private int count;/** Concurrency control uses the classic two-condition algorithm* found in any textbook.*//** Main lock guarding all access */private final ReentrantLock lock;/** Condition for waiting takes */private final Condition notEmpty;/** Condition for waiting puts */private final Condition notFull;} |
可以看出,ArrayBlockingQueue中用来存储元素的实际上是一个数组,takeIndex和putIndex分别表示队首元素和队尾元素的下标,count表示队列中元素的个数。
lock是一个可重入锁,notEmpty和notFull是等待条件。
下面看一下ArrayBlockingQueue的构造器,构造器有三个重载版本:
|
1
2
3
4
5
6
7
8
|
public ArrayBlockingQueue(int capacity) {}public ArrayBlockingQueue(int capacity, boolean fair) {}public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) {} |
第一个构造器只有一个参数用来指定容量,第二个构造器可以指定容量和公平性,第三个构造器可以指定容量、公平性以及用另外一个集合进行初始化。
然后看它的两个关键方法的实现:put()和take():
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public void put(E e) throws InterruptedException { if (e == null) throw new NullPointerException(); final E[] items = this.items; final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { try { while (count == items.length) notFull.await(); } catch (InterruptedException ie) { notFull.signal(); // propagate to non-interrupted thread throw ie; } insert(e); } finally { lock.unlock(); }} |
从put方法的实现可以看出,它先获取了锁,并且获取的是可中断锁,然后判断当前元素个数是否等于数组的长度,如果相等,则调用notFull.await()进行等待,如果捕获到中断异常,则唤醒线程并抛出异常。
当被其他线程唤醒时,通过insert(e)方法插入元素,最后解锁。
我们看一下insert方法的实现:
|
1
2
3
4
5
6
|
private void insert(E x) { items[putIndex] = x; putIndex = inc(putIndex); ++count; notEmpty.signal();} |
它是一个private方法,插入成功后,通过notEmpty唤醒正在等待取元素的线程。
下面是take()方法的实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { try { while (count == 0) notEmpty.await(); } catch (InterruptedException ie) { notEmpty.signal(); // propagate to non-interrupted thread throw ie; } E x = extract(); return x; } finally { lock.unlock(); }} |
跟put方法实现很类似,只不过put方法等待的是notFull信号,而take方法等待的是notEmpty信号。在take方法中,如果可以取元素,则通过extract方法取得元素,下面是extract方法的实现:
|
1
2
3
4
5
6
7
8
9
|
private E extract() { final E[] items = this.items; E x = items[takeIndex]; items[takeIndex] = null; takeIndex = inc(takeIndex); --count; notFull.signal(); return x;} |
跟insert方法也很类似。
其实从这里大家应该明白了阻塞队列的实现原理,事实它和我们用Object.wait()、Object.notify()和非阻塞队列实现生产者-消费者的思路类似,只不过它把这些工作一起集成到了阻塞队列中实现。
四.示例和使用场景
下面先使用Object.wait()和Object.notify()、非阻塞队列实现生产者-消费者模式:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
public class Test { private int queueSize = 10; private PriorityQueue<Integer> queue = new PriorityQueue<Integer>(queueSize); public static void main(String[] args) { Test test = new Test(); Producer producer = test.new Producer(); Consumer consumer = test.new Consumer(); producer.start(); consumer.start(); } class Consumer extends Thread{ @Override public void run() { consume(); } private void consume() { while(true){ synchronized (queue) { while(queue.size() == 0){ try { System.out.println("队列空,等待数据"); queue.wait(); } catch (InterruptedException e) { e.printStackTrace(); queue.notify(); } } queue.poll(); //每次移走队首元素 queue.notify(); System.out.println("从队列取走一个元素,队列剩余"+queue.size()+"个元素"); } } } } class Producer extends Thread{ @Override public void run() { produce(); } private void produce() { while(true){ synchronized (queue) { while(queue.size() == queueSize){ try { System.out.println("队列满,等待有空余空间"); queue.wait(); } catch (InterruptedException e) { e.printStackTrace(); queue.notify(); } } queue.offer(1); //每次插入一个元素 queue.notify(); System.out.println("向队列取中插入一个元素,队列剩余空间:"+(queueSize-queue.size())); } } } }} |
这个是经典的生产者-消费者模式,通过阻塞队列和Object.wait()和Object.notify()实现,wait()和notify()主要用来实现线程间通信。
具体的线程间通信方式(wait和notify的使用)在后续问章中会讲述到。
下面是使用阻塞队列实现的生产者-消费者模式:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
public class Test { private int queueSize = 10; private ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<Integer>(queueSize); public static void main(String[] args) { Test test = new Test(); Producer producer = test.new Producer(); Consumer consumer = test.new Consumer(); producer.start(); consumer.start(); } class Consumer extends Thread{ @Override public void run() { consume(); } private void consume() { while(true){ try { queue.take(); System.out.println("从队列取走一个元素,队列剩余"+queue.size()+"个元素"); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Producer extends Thread{ @Override public void run() { produce(); } private void produce() { while(true){ try { queue.put(1); System.out.println("向队列取中插入一个元素,队列剩余空间:"+(queueSize-queue.size())); } catch (InterruptedException e) { e.printStackTrace(); } } } }} |
有没有发现,使用阻塞队列代码要简单得多,不需要再单独考虑同步和线程间通信的问题。
在并发编程中,一般推荐使用阻塞队列,这样实现可以尽量地避免程序出现意外的错误。
阻塞队列使用最经典的场景就是socket客户端数据的读取和解析,读取数据的线程不断将数据放入队列,然后解析线程不断从队列取数据解析。还有其他类似的场景,只要符合生产者-消费者模型的都可以使用阻塞队列。
参考资料:
《Java编程实战》
http://ifeve.com/java-blocking-queue/
http://endual.iteye.com/blog/1412212
http://blog.csdn.net/zzp_403184692/article/details/8021615
http://www.cnblogs.com/juepei/p/3922401.html
我们在平时的时候使用的是队列,指定好个数以后,如果放的数据超过了队列设定的个数的时候会报错误的。那么多线程中,有一个阻塞队列的叫arrayBlockQueue。这个类是对queue在多线程中使用的扩展,也就是说,当作为临界资源的时候,这个队列是安全,存放数据如果超过了队列设定好的初始的数据的时候,放入数据的线程将会被等待着的。
下面来看例子。
场景模拟:
现在有两个线程,一个线程往队列里面添加数据,一个是将队列里面的数据取出来并且删掉数据。当然,放数据的线程要速度快点,这样才能够模拟出来队列里面存放的数据的个数会超过队列起先设定好的初始的个数吧。存放的线程是每个 5 秒钟放一个数据,取得话是每个10秒钟 取一次,下面是代码 三个类:
main类
- package endual;
- import java.util.concurrent.ArrayBlockingQueue;
- import java.util.concurrent.ExecutorService;
- import java.util.concurrent.Executors;
- /**
- * 阻塞对列,往对立里面添加元素
- * 一个由数组支持的有界阻塞队列。此队列按 FIFO(先进先出)
- * 原则对元素进行排序。队列的头部 是在队列中存在时间最长的元素。
- * 队列的尾部 是在队列中存在时间最短的元素。新元素插入到队列的尾部,
- * 队列检索操作则是从队列头部开始获得元素。
- *
- *题目:
- *两个操作队列,一个队列是取数据,一个队列是放数据,如果一个线程取放数据过快,那么对立会阻塞,
- *线程也会进行等待着的
- *
- *
- */
- public class ArrayBlockQueueApp {
- public static void main(String[] args) {
- ArrayBlockQueueApp app = new ArrayBlockQueueApp() ;
- app.mian() ;
- }
- private void mian() {
- ExecutorService es = Executors.newCachedThreadPool() ;
- ArrayBlockingQueue<String> abq = new ArrayBlockingQueue<String>(10) ;
- ThreadGet t1 = new ThreadGet(abq);
- Thread t2 = new Thread(new ThreadPut(abq)) ;
- es.execute(t1) ;
- es.execute(t2) ;
- }
- }
get线程类
- package endual;
- import java.util.concurrent.ArrayBlockingQueue;
- public class ThreadGet extends Thread{
- ArrayBlockingQueue<String> abq = null ;
- public ThreadGet(ArrayBlockingQueue<String> abq) {
- this.abq = abq ;
- }
- public void run(){
- while (true) {
- try {
- Thread.sleep(10000) ;
- System.out.println("我要从队列中取数据了");
- String msg = abq.remove() ;
- System.out.println("队列里面取得的数据是:" + msg + " 队列中还的数据个数还有的 :" + abq.size());
- } catch (InterruptedException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }//每个十秒钟会进行拿数据出来的
- }
- }
- }
取数据的线程类:
- package endual;
- import java.util.concurrent.ArrayBlockingQueue;
- public class ThreadPut implements Runnable{
- private ArrayBlockingQueue<String> abq = null ;
- public ThreadPut (ArrayBlockingQueue<String> abq) {
- this.abq = abq ;
- }
- public void run() {
- while (true) {
- try {
- System.out.println("我要向队列里面存放数据了");
- Thread.sleep(5000) ;
- abq.put("1") ;
- System.out.println("当前的队列里面存放的数据的个数是:" + abq.size());
- } catch (InterruptedException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- } //向队列里面存放数据
- }
- }
- }
下面是测试的结果:
- 我要向队列里面存放数据了
- 当前的队列里面存放的数据的个数是:1
- 我要向队列里面存放数据了
- 我要从队列中取数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :0
- 当前的队列里面存放的数据的个数是:1
- 我要向队列里面存放数据了
- 当前的队列里面存放的数据的个数是:2
- 我要向队列里面存放数据了
- 当前的队列里面存放的数据的个数是:3
- 我要向队列里面存放数据了
- 我要从队列中取数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :2
- 当前的队列里面存放的数据的个数是:3
- 我要向队列里面存放数据了
- 我要从队列中取数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :2
- 当前的队列里面存放的数据的个数是:3
- 我要向队列里面存放数据了
- 当前的队列里面存放的数据的个数是:4
- 我要向队列里面存放数据了
- 当前的队列里面存放的数据的个数是:5
- 我要向队列里面存放数据了
- 我要从队列中取数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :4
- 当前的队列里面存放的数据的个数是:5
- 我要向队列里面存放数据了
- 当前的队列里面存放的数据的个数是:6
- 我要向队列里面存放数据了
- 我要从队列中取数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :5
- 当前的队列里面存放的数据的个数是:6
- 我要向队列里面存放数据了
- 当前的队列里面存放的数据的个数是:7
- 我要向队列里面存放数据了
- 我要从队列中取数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :6
- 当前的队列里面存放的数据的个数是:7
- 我要向队列里面存放数据了
- 当前的队列里面存放的数据的个数是:8
- 我要向队列里面存放数据了
- 我要从队列中取数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :7
- 当前的队列里面存放的数据的个数是:8
- 我要向队列里面存放数据了
- 当前的队列里面存放的数据的个数是:9
- 我要向队列里面存放数据了
- 我要从队列中取数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :8
- 当前的队列里面存放的数据的个数是:9
- 我要向队列里面存放数据了
- 当前的队列里面存放的数据的个数是:10
- 我要向队列里面存放数据了
- 我要从队列中取数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :9
- 当前的队列里面存放的数据的个数是:10
- 我要向队列里面存放数据了
- 我要从队列中取数据了
- 当前的队列里面存放的数据的个数是:10
- 我要向队列里面存放数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :10
- 我要从队列中取数据了
- 当前的队列里面存放的数据的个数是:10
- 我要向队列里面存放数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :10
- 我要从队列中取数据了
- 当前的队列里面存放的数据的个数是:10
- 我要向队列里面存放数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :10
- 我要从队列中取数据了
- 当前的队列里面存放的数据的个数是:10
- 我要向队列里面存放数据了
- 队列里面取得的数据是:1 队列中还的数据个数还有的 :10
我们从结果中可以看出来,当队列里面的数据达到10个的时候,存放数据的线程在存放的时候将等待队列少的位子,不会像队列里面的数据少于10个的时候,存放数据是无需等待的,5秒钟到了就马上放进去。而到了10个数据的时候,存放的那个现在到了5秒钟的时候,还必须在等待位子,因为队列中还是10个位子,只有当取数据的线程取出数据以后,空出来的位子后马上就添加进去了的
阻塞队列概要
阻塞队列与我们平常接触的普通队列(LinkedList或ArrayList等)的最大不同点,在于阻塞队列支出阻塞添加和阻塞删除方法。
-
阻塞添加
所谓的阻塞添加是指当阻塞队列元素已满时,队列会阻塞加入元素的线程,直队列元素不满时才重新唤醒线程执行元素加入操作。 -
阻塞删除
阻塞删除是指在队列元素为空时,删除队列元素的线程将被阻塞,直到队列不为空再执行删除操作(一般都会返回被删除的元素)
由于Java中的阻塞队列接口BlockingQueue继承自Queue接口,因此先来看看阻塞队列接口为我们提供的主要方法
public interface BlockingQueue<E> extends Queue<E> {
//将指定的元素插入到此队列的尾部(如果立即可行且不会超过该队列的容量)
//在成功时返回 true,如果此队列已满,则抛IllegalStateException。
boolean add(E e);
//将指定的元素插入到此队列的尾部(如果立即可行且不会超过该队列的容量)
// 将指定的元素插入此队列的尾部,如果该队列已满,
//则在到达指定的等待时间之前等待可用的空间,该方法可中断
boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;
//将指定的元素插入此队列的尾部,如果该队列已满,则一直等到(阻塞)。
void put(E e) throws InterruptedException;
//获取并移除此队列的头部,如果没有元素则等待(阻塞),
//直到有元素将唤醒等待线程执行该操作
E take() throws InterruptedException;
//获取并移除此队列的头部,在指定的等待时间前一直等到获取元素, //超过时间方法将结束
E poll(long timeout, TimeUnit unit) throws InterruptedException;
//从此队列中移除指定元素的单个实例(如果存在)。
boolean remove(Object o);
}
//除了上述方法还有继承自Queue接口的方法
//获取但不移除此队列的头元素,没有则跑异常NoSuchElementException
E element();
//获取但不移除此队列的头;如果此队列为空,则返回 null。
E peek();
//获取并移除此队列的头,如果此队列为空,则返回 null。
E poll();这里我们把上述操作进行分类
-
插入方法:
- add(E e) : 添加成功返回true,失败抛IllegalStateException异常
- offer(E e) : 成功返回 true,如果此队列已满,则返回 false。
- put(E e) :将元素插入此队列的尾部,如果该队列已满,则一直阻塞
-
删除方法:
- remove(Object o) :移除指定元素,成功返回true,失败返回false
- poll() : 获取并移除此队列的头元素,若队列为空,则返回 null
- take():获取并移除此队列头元素,若没有元素则一直阻塞。
-
检查方法
- element() :获取但不移除此队列的头元素,没有元素则抛异常
- peek() :获取但不移除此队列的头;若队列为空,则返回 null。
阻塞队列的对元素的增删查操作主要就是上述的三类方法,通常情况下我们都是通过这3类方法操作阻塞队列,了解完阻塞队列的基本方法后,下面我们将分析阻塞队列中的两个实现类ArrayBlockingQueue和LinkedBlockingQueue的简单使用和实现原理,其中实现原理是这篇文章重点分析的内容。
ArrayBlockingQueue的基本使用
ArrayBlockingQueue 是一个用数组实现的有界阻塞队列,其内部按先进先出的原则对元素进行排序,其中put方法和take方法为添加和删除的阻塞方法,下面我们通过ArrayBlockingQueue队列实现一个生产者消费者的案例,通过该案例简单了解其使用方式
这里写代码片代码比较简单, Consumer 消费者和 Producer 生产者,通过ArrayBlockingQueue 队列获取和添加元素,其中消费者调用了take()方法获取元素当队列没有元素就阻塞,生产者调用put()方法添加元素,当队列满时就阻塞,通过这种方式便实现生产者消费者模式。比直接使用等待唤醒机制或者Condition条件队列来得更加简单。执行代码,打印部分Log如下
package com.zejian.concurrencys.Queue;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.TimeUnit;
/**
* Created by wuzejian on 2017/8/13
*/
public class ArrayBlockingQueueDemo {
private final static ArrayBlockingQueue<Apple> queue= new ArrayBlockingQueue<>(1);
public static void main(String[] args){
new Thread(new Producer(queue)).start();
new Thread(new Producer(queue)).start();
new Thread(new Consumer(queue)).start();
new Thread(new Consumer(queue)).start();
}
}
class Apple {
public Apple(){
}
}
/**
* 生产者线程
*/
class Producer implements Runnable{
private final ArrayBlockingQueue<Apple> mAbq;
Producer(ArrayBlockingQueue<Apple> arrayBlockingQueue){
this.mAbq = arrayBlockingQueue;
}
@Override
public void run() {
while (true) {
Produce();
}
}
private void Produce(){
try {
Apple apple = new Apple();
mAbq.put(apple);
System.out.println("生产:"+apple);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 消费者线程
*/
class Consumer implements Runnable{
private ArrayBlockingQueue<Apple> mAbq;
Consumer(ArrayBlockingQueue<Apple> arrayBlockingQueue){
this.mAbq = arrayBlockingQueue;
}
@Override
public void run() {
while (true){
try {
TimeUnit.MILLISECONDS.sleep(1000);
comsume();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private void comsume() throws InterruptedException {
Apple apple = mAbq.take();
System.out.println("消费Apple="+apple);
}
}生产:com.zejian.concurrencys.Queue.Apple@109967f
消费Apple=com.zejian.concurrencys.Queue.Apple@109967f
生产:com.zejian.concurrencys.Queue.Apple@269a77
生产:com.zejian.concurrencys.Queue.Apple@1ce746e
消费Apple=com.zejian.concurrencys.Queue.Apple@269a77
消费Apple=com.zejian.concurrencys.Queue.Apple@1ce746e
........有点需要注意的是ArrayBlockingQueue内部的阻塞队列是通过重入锁ReenterLock和Condition条件队列实现的,所以ArrayBlockingQueue中的元素存在公平访问与非公平访问的区别,对于公平访问队列,被阻塞的线程可以按照阻塞的先后顺序访问队列,即先阻塞的线程先访问队列。而非公平队列,当队列可用时,阻塞的线程将进入争夺访问资源的竞争中,也就是说谁先抢到谁就执行,没有固定的先后顺序。创建公平与非公平阻塞队列代码如下:
//默认非公平阻塞队列
ArrayBlockingQueue queue = new ArrayBlockingQueue(2);
//公平阻塞队列
ArrayBlockingQueue queue1 = new ArrayBlockingQueue(2,true);
//构造方法源码
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}其他方法如下:
//自动移除此队列中的所有元素。
void clear()
//如果此队列包含指定的元素,则返回 true。
boolean contains(Object o)
//移除此队列中所有可用的元素,并将它们添加到给定collection中。
int drainTo(Collection<? super E> c)
//最多从此队列中移除给定数量的可用元素,并将这些元素添加到给定collection 中。
int drainTo(Collection<? super E> c, int maxElements)
//返回在此队列中的元素上按适当顺序进行迭代的迭代器。
Iterator<E> iterator()
//返回队列还能添加元素的数量
int remainingCapacity()
//返回此队列中元素的数量。
int size()
//返回一个按适当顺序包含此队列中所有元素的数组。
Object[] toArray()
//返回一个按适当顺序包含此队列中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。
<T> T[] toArray(T[] a)ArrayBlockingQueue的实现原理剖析
ArrayBlockingQueue原理概要
ArrayBlockingQueue的内部是通过一个可重入锁ReentrantLock和两个Condition条件对象来实现阻塞,这里先看看其内部成员变量
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** 存储数据的数组 */
final Object[] items;
/**获取数据的索引,主要用于take,poll,peek,remove方法 */
int takeIndex;
/**添加数据的索引,主要用于 put, offer, or add 方法*/
int putIndex;
/** 队列元素的个数 */
int count;
/** 控制并非访问的锁 */
final ReentrantLock lock;
/**notEmpty条件对象,用于通知take方法队列已有元素,可执行获取操作 */
private final Condition notEmpty;
/**notFull条件对象,用于通知put方法队列未满,可执行添加操作 */
private final Condition notFull;
/**
迭代器
*/
transient Itrs itrs = null;
}从成员变量可看出,ArrayBlockingQueue内部确实是通过数组对象items来存储所有的数据,值得注意的是ArrayBlockingQueue通过一个ReentrantLock来同时控制添加线程与移除线程的并非访问,这点与LinkedBlockingQueue区别很大(稍后会分析)。而对于notEmpty条件对象则是用于存放等待或唤醒调用take方法的线程,告诉他们队列已有元素,可以执行获取操作。同理notFull条件对象是用于等待或唤醒调用put方法的线程,告诉它们,队列未满,可以执行添加元素的操作。takeIndex代表的是下一个方法(take,poll,peek,remove)被调用时获取数组元素的索引,putIndex则代表下一个方法(put, offer, or add)被调用时元素添加到数组中的索引。图示如下

ArrayBlockingQueue的(阻塞)添加的实现原理
//add方法实现,间接调用了offer(e)
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
//offer方法
public boolean offer(E e) {
checkNotNull(e);//检查元素是否为null
final ReentrantLock lock = this.lock;
lock.lock();//加锁
try {
if (count == items.length)//判断队列是否满
return false;
else {
enqueue(e);//添加元素到队列
return true;
}
} finally {
lock.unlock();
}
}
//入队操作
private void enqueue(E x) {
//获取当前数组
final Object[] items = this.items;
//通过putIndex索引对数组进行赋值
items[putIndex] = x;
//索引自增,如果已是最后一个位置,重新设置 putIndex = 0;
if (++putIndex == items.length)
putIndex = 0;
count++;//队列中元素数量加1
//唤醒调用take()方法的线程,执行元素获取操作。
notEmpty.signal();
}这里的add方法和offer方法实现比较简单,其中需要注意的是enqueue(E x)方法,其方法内部通过putIndex索引直接将元素添加到数组items中,这里可能会疑惑的是当putIndex索引大小等于数组长度时,需要将putIndex重新设置为0,这是因为当前队列执行元素获取时总是从队列头部获取,而添加元素从中从队列尾部获取所以当队列索引(从0开始)与数组长度相等时,下次我们就需要从数组头部开始添加了,如下图演示
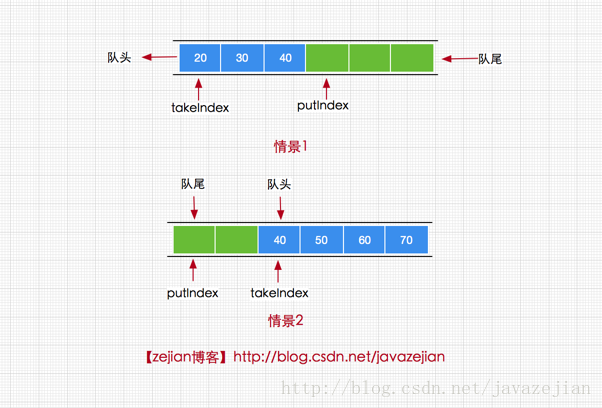
ok~,接着看put方法,它是一个阻塞添加的方法,
//put方法,阻塞时可中断
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();//该方法可中断
try {
//当队列元素个数与数组长度相等时,无法添加元素
while (count == items.length)
//将当前调用线程挂起,添加到notFull条件队列中等待唤醒
notFull.await();
enqueue(e);//如果队列没有满直接添加。。
} finally {
lock.unlock();
}
}put方法是一个阻塞的方法,如果队列元素已满,那么当前线程将会被notFull条件对象挂起加到等待队列中,直到队列有空档才会唤醒执行添加操作。但如果队列没有满,那么就直接调用enqueue(e)方法将元素加入到数组队列中。到此我们对三个添加方法即put,offer,add都分析完毕,其中offer,add在正常情况下都是无阻塞的添加,而put方法是阻塞添加。这就是阻塞队列的添加过程。说白了就是当队列满时通过条件对象Condtion来阻塞当前调用put方法的线程,直到线程又再次被唤醒执行。总得来说添加线程的执行存在以下两种情况,一是,队列已满,那么新到来的put线程将添加到notFull的条件队列中等待,二是,有移除线程执行移除操作,移除成功同时唤醒put线程,如下图所示
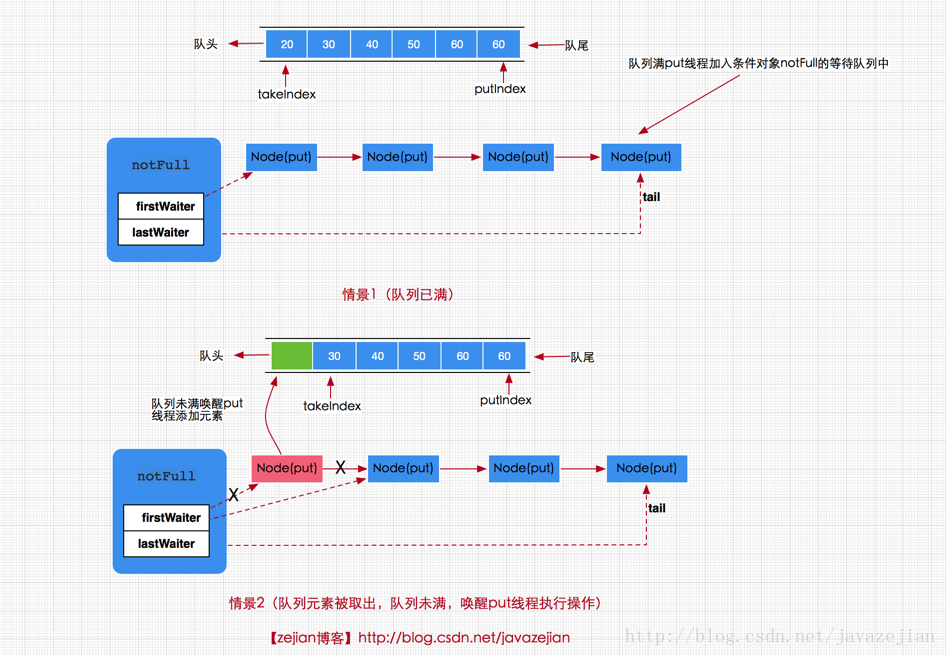
ArrayBlockingQueue的(阻塞)移除实现原理
关于删除先看poll方法,该方法获取并移除此队列的头元素,若队列为空,则返回 null
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//判断队列是否为null,不为null执行dequeue()方法,否则返回null
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
//删除队列头元素并返回
private E dequeue() {
//拿到当前数组的数据
final Object[] items = this.items;
@SuppressWarnings("unchecked")
//获取要删除的对象
E x = (E) items[takeIndex];
将数组中takeIndex索引位置设置为null
items[takeIndex] = null;
//takeIndex索引加1并判断是否与数组长度相等,
//如果相等说明已到尽头,恢复为0
if (++takeIndex == items.length)
takeIndex = 0;
count--;//队列个数减1
if (itrs != null)
itrs.elementDequeued();//同时更新迭代器中的元素数据
//删除了元素说明队列有空位,唤醒notFull条件对象添加线程,执行添加操作
notFull.signal();
return x;
}poll(),获取并删除队列头元素,队列没有数据就返回null,内部通过dequeue()方法删除头元素,注释很清晰,这里不重复了。接着看remove(Object o)方法
public boolean remove(Object o) {
if (o == null) return false;
//获取数组数据
final Object[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lock();//加锁
try {
//如果此时队列不为null,这里是为了防止并发情况
if (count > 0) {
//获取下一个要添加元素时的索引
final int putIndex = this.putIndex;
//获取当前要被删除元素的索引
int i = takeIndex;
//执行循环查找要删除的元素
do {
//找到要删除的元素
if (o.equals(items[i])) {
removeAt(i);//执行删除
return true;//删除成功返回true
}
//当前删除索引执行加1后判断是否与数组长度相等
//若为true,说明索引已到数组尽头,将i设置为0
if (++i == items.length)
i = 0;
} while (i != putIndex);//继承查找
}
return false;
} finally {
lock.unlock();
}
}
//根据索引删除元素,实际上是把删除索引之后的元素往前移动一个位置
void removeAt(final int removeIndex) {
final Object[] items = this.items;
//先判断要删除的元素是否为当前队列头元素
if (removeIndex == takeIndex) {
//如果是直接删除
items[takeIndex] = null;
//当前队列头元素加1并判断是否与数组长度相等,若为true设置为0
if (++takeIndex == items.length)
takeIndex = 0;
count--;//队列元素减1
if (itrs != null)
itrs.elementDequeued();//更新迭代器中的数据
} else {
//如果要删除的元素不在队列头部,
//那么只需循环迭代把删除元素后面的所有元素往前移动一个位置
//获取下一个要被添加的元素的索引,作为循环判断结束条件
final int putIndex = this.putIndex;
//执行循环
for (int i = removeIndex;;) {
//获取要删除节点索引的下一个索引
int next = i + 1;
//判断是否已为数组长度,如果是从数组头部(索引为0)开始找
if (next == items.length)
next = 0;
//如果查找的索引不等于要添加元素的索引,说明元素可以再移动
if (next != putIndex) {
items[i] = items[next];//把后一个元素前移覆盖要删除的元
i = next;
} else {
//在removeIndex索引之后的元素都往前移动完毕后清空最后一个元素
items[i] = null;
this.putIndex = i;
break;//结束循环
}
}
count--;//队列元素减1
if (itrs != null)
itrs.removedAt(removeIndex);//更新迭代器数据
}
notFull.signal();//唤醒添加线程
}remove(Object o)方法的删除过程相对复杂些,因为该方法并不是直接从队列头部删除元素。首先线程先获取锁,再一步判断队列count>0,这点是保证并发情况下删除操作安全执行。接着获取下一个要添加源的索引putIndex以及takeIndex索引 ,作为后续循环的结束判断,因为只要putIndex与takeIndex不相等就说明队列没有结束。然后通过while循环找到要删除的元素索引,执行removeAt(i)方法删除,在removeAt(i)方法中实际上做了两件事,一是首先判断队列头部元素是否为删除元素,如果是直接删除,并唤醒添加线程,二是如果要删除的元素并不是队列头元素,那么执行循环操作,从要删除元素的索引removeIndex之后的元素都往前移动一个位置,那么要删除的元素就被removeIndex之后的元素替换,从而也就完成了删除操作。接着看take()方法,是一个阻塞方法,直接获取队列头元素并删除。
//从队列头部删除,队列没有元素就阻塞,可中断
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();//中断
try {
//如果队列没有元素
while (count == 0)
//执行阻塞操作
notEmpty.await();
return dequeue();//如果队列有元素执行删除操作
} finally {
lock.unlock();
}
}take方法其实很简单,有就删除没有就阻塞,注意这个阻塞是可以中断的,如果队列没有数据那么就加入notEmpty条件队列等待(有数据就直接取走,方法结束),如果有新的put线程添加了数据,那么put操作将会唤醒take线程,执行take操作。图示如下
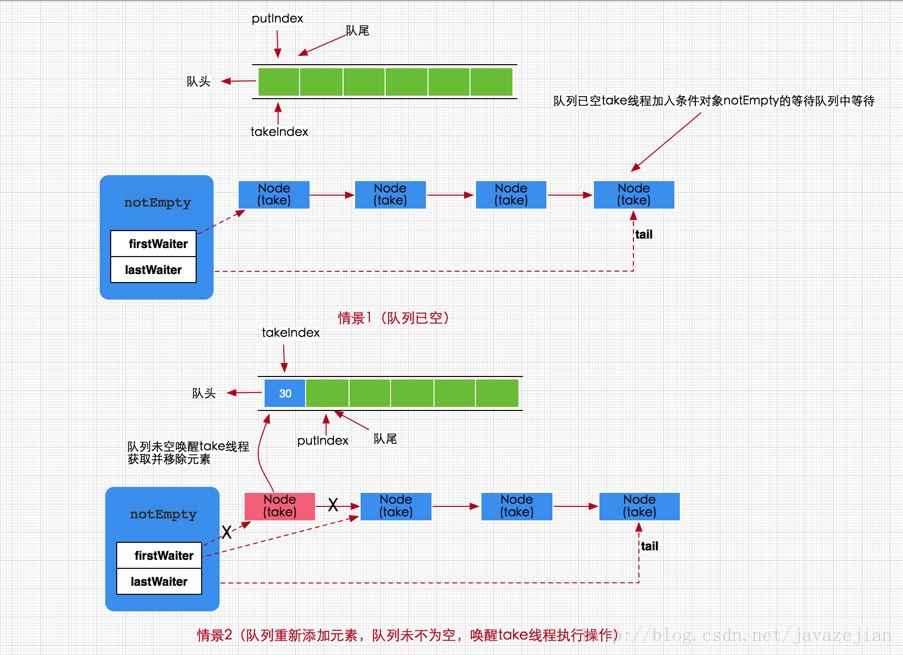
public E peek() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//直接返回当前队列的头元素,但不删除
return itemAt(takeIndex); // null when queue is empty
} finally {
lock.unlock();
}
}
final E itemAt(int i) {
return (E) items[i];
}peek方法非常简单,直接返回当前队列的头元素但不删除任何元素。ok~,到此对于ArrayBlockingQueue的主要方法就分析完了。
LinkedBlockingQueue的基本概要
LinkedBlockingQueue是一个由链表实现的有界队列阻塞队列,但大小默认值为Integer.MAX_VALUE,所以我们在使用LinkedBlockingQueue时建议手动传值,为其提供我们所需的大小,避免队列过大造成机器负载或者内存爆满等情况。其构造函数如下
//默认大小为Integer.MAX_VALUE
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
//创建指定大小为capacity的阻塞队列
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
//创建大小默认值为Integer.MAX_VALUE的阻塞队列并添加c中的元素到阻塞队列
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
putLock.lock(); // Never contended, but necessary for visibility
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
count.set(n);
} finally {
putLock.unlock();
}
}从源码看,有三种方式可以构造LinkedBlockingQueue,通常情况下,我们建议创建指定大小的LinkedBlockingQueue阻塞队列。LinkedBlockingQueue队列也是按 FIFO(先进先出)排序元素。队列的头部是在队列中时间最长的元素,队列的尾部 是在队列中时间最短的元素,新元素插入到队列的尾部,而队列执行获取操作会获得位于队列头部的元素。在正常情况下,链接队列的吞吐量要高于基于数组的队列(ArrayBlockingQueue),因为其内部实现添加和删除操作使用的两个ReenterLock来控制并发执行,而ArrayBlockingQueue内部只是使用一个ReenterLock控制并发,因此LinkedBlockingQueue的吞吐量要高于ArrayBlockingQueue。注意LinkedBlockingQueue和ArrayBlockingQueue的API几乎是一样的,但它们的内部实现原理不太相同,这点稍后会分析。使用LinkedBlockingQueue,我们同样也能实现生产者消费者模式。只需把前面ArrayBlockingQueue案例中的阻塞队列对象换成LinkedBlockingQueue即可。这里限于篇幅就不贴重复代码了。接下来我们重点分析LinkedBlockingQueue的内部实现原理,最后我们将对ArrayBlockingQueue和LinkedBlockingQueue 做总结,阐明它们间的不同之处。
LinkedBlockingQueue的实现原理剖析
原理概论
LinkedBlockingQueue是一个基于链表的阻塞队列,其内部维持一个基于链表的数据队列,实际上我们对LinkedBlockingQueue的API操作都是间接操作该数据队列,这里我们先看看LinkedBlockingQueue的内部成员变量
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/**
* 节点类,用于存储数据
*/
static class Node<E> {
E item;
/**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head.next
* - null, meaning there is no successor (this is the last node)
*/
Node<E> next;
Node(E x) { item = x; }
}
/** 阻塞队列的大小,默认为Integer.MAX_VALUE */
private final int capacity;
/** 当前阻塞队列中的元素个数 */
private final AtomicInteger count = new AtomicInteger();
/**
* 阻塞队列的头结点
*/
transient Node<E> head;
/**
* 阻塞队列的尾节点
*/
private transient Node<E> last;
/** 获取并移除元素时使用的锁,如take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** notEmpty条件对象,当队列没有数据时用于挂起执行删除的线程 */
private final Condition notEmpty = takeLock.newCondition();
/** 添加元素时使用的锁如 put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** notFull条件对象,当队列数据已满时用于挂起执行添加的线程 */
private final Condition notFull = putLock.newCondition();
}从上述可看成,每个添加到LinkedBlockingQueue队列中的数据都将被封装成Node节点,添加的链表队列中,其中head和last分别指向队列的头结点和尾结点。与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制,也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。这里再次强调如果没有给LinkedBlockingQueue指定容量大小,其默认值将是Integer.MAX_VALUE,如果存在添加速度大于删除速度时候,有可能会内存溢出,这点在使用前希望慎重考虑。至于LinkedBlockingQueue的实现原理图与ArrayBlockingQueue是类似的,除了对添加和移除方法使用单独的锁控制外,两者都使用了不同的Condition条件对象作为等待队列,用于挂起take线程和put线程。
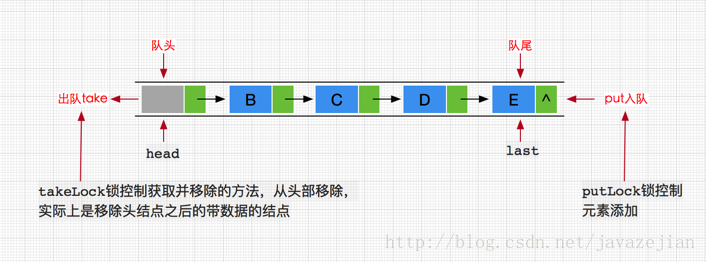
ok~,下面我们看看其其内部添加过程和删除过程是如何实现的。
添加方法的实现原理
对于添加方法,主要指的是add,offer以及put,这里先看看add方法和offer方法的实现
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}- 1
- 2
- 3
- 4
- 5
- 6
从源码可以看出,add方法间接调用的是offer方法,如果add方法添加失败将抛出IllegalStateException异常,添加成功则返回true,那么下面我们直接看看offer的相关方法实现
public boolean offer(E e) {
//添加元素为null直接抛出异常
if (e == null) throw new NullPointerException();
//获取队列的个数
final AtomicInteger count = this.count;
//判断队列是否已满
if (count.get() == capacity)
return false;
int c = -1;
//构建节点
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
//再次判断队列是否已满,考虑并发情况
if (count.get() < capacity) {
enqueue(node);//添加元素
c = count.getAndIncrement();//拿到当前未添加新元素时的队列长度
//如果容量还没满
if (c + 1 < capacity)
notFull.signal();//唤醒下一个添加线程,执行添加操作
}
} finally {
putLock.unlock();
}
// 由于存在添加锁和消费锁,而消费锁和添加锁都会持续唤醒等到线程,因此count肯定会变化。
//这里的if条件表示如果队列中还有1条数据
if (c == 0)
signalNotEmpty();//如果还存在数据那么就唤醒消费锁
return c >= 0; // 添加成功返回true,否则返回false
}
//入队操作
private void enqueue(Node<E> node) {
//队列尾节点指向新的node节点
last = last.next = node;
}
//signalNotEmpty方法
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
//唤醒获取并删除元素的线程
notEmpty.signal();
} finally {
takeLock.unlock();
}
}这里的Offer()方法做了两件事,第一件事是判断队列是否满,满了就直接释放锁,没满就将节点封装成Node入队,然后再次判断队列添加完成后是否已满,不满就继续唤醒等到在条件对象notFull上的添加线程。第二件事是,判断是否需要唤醒等到在notEmpty条件对象上的消费线程。这里我们可能会有点疑惑,为什么添加完成后是继续唤醒在条件对象notFull上的添加线程而不是像ArrayBlockingQueue那样直接唤醒notEmpty条件对象上的消费线程?而又为什么要当if (c == 0)时才去唤醒消费线程呢?
-
唤醒添加线程的原因,在添加新元素完成后,会判断队列是否已满,不满就继续唤醒在条件对象notFull上的添加线程,这点与前面分析的ArrayBlockingQueue很不相同,在ArrayBlockingQueue内部完成添加操作后,会直接唤醒消费线程对元素进行获取,这是因为ArrayBlockingQueue只用了一个ReenterLock同时对添加线程和消费线程进行控制,这样如果在添加完成后再次唤醒添加线程的话,消费线程可能永远无法执行,而对于LinkedBlockingQueue来说就不一样了,其内部对添加线程和消费线程分别使用了各自的ReenterLock锁对并发进行控制,也就是说添加线程和消费线程是不会互斥的,所以添加锁只要管好自己的添加线程即可,添加线程自己直接唤醒自己的其他添加线程,如果没有等待的添加线程,直接结束了。如果有就直到队列元素已满才结束挂起,当然offer方法并不会挂起,而是直接结束,只有put方法才会当队列满时才执行挂起操作。注意消费线程的执行过程也是如此。这也是为什么LinkedBlockingQueue的吞吐量要相对大些的原因。
-
为什么要判断
if (c == 0)时才去唤醒消费线程呢,这是因为消费线程一旦被唤醒是一直在消费的(前提是有数据),所以c值是一直在变化的,c值是添加完元素前队列的大小,此时c只可能是0或c>0,如果是c=0,那么说明之前消费线程已停止,条件对象上可能存在等待的消费线程,添加完数据后应该是c+1,那么有数据就直接唤醒等待消费线程,如果没有就结束啦,等待下一次的消费操作。如果c>0那么消费线程就不会被唤醒,只能等待下一个消费操作(poll、take、remove)的调用,那为什么不是条件c>0才去唤醒呢?我们要明白的是消费线程一旦被唤醒会和添加线程一样,一直不断唤醒其他消费线程,如果添加前c>0,那么很可能上一次调用的消费线程后,数据并没有被消费完,条件队列上也就不存在等待的消费线程了,所以c>0唤醒消费线程得意义不是很大,当然如果添加线程一直添加元素,那么一直c>0,消费线程执行的换就要等待下一次调用消费操作了(poll、take、remove)。
移除方法的实现原理
关于移除的方法主要是指remove和poll以及take方法,下面一一分析
public boolean remove(Object o) {
if (o == null) return false;
fullyLock();//同时对putLock和takeLock加锁
try {
//循环查找要删除的元素
for (Node<E> trail = head, p = trail.next;
p != null;
trail = p, p = p.next) {
if (o.equals(p.item)) {//找到要删除的节点
unlink(p, trail);//直接删除
return true;
}
}
return false;
} finally {
fullyUnlock();//解锁
}
}
//两个同时加锁
void fullyLock() {
putLock.lock();
takeLock.lock();
}
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}remove方法删除指定的对象,这里我们可能会诧异,为什么同时对putLock和takeLock加锁?这是因为remove方法删除的数据的位置不确定,为了避免造成并非安全问题,所以需要对2个锁同时加锁。
public E poll() {
//获取当前队列的大小
final AtomicInteger count = this.count;
if (count.get() == 0)//如果没有元素直接返回null
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
//判断队列是否有数据
if (count.get() > 0) {
//如果有,直接删除并获取该元素值
x = dequeue();
//当前队列大小减一
c = count.getAndDecrement();
//如果队列未空,继续唤醒等待在条件对象notEmpty上的消费线程
if (c > 1)
notEmpty.signal();
}
} finally {
takeLock.unlock();
}
//判断c是否等于capacity,这是因为如果满说明NotFull条件对象上
//可能存在等待的添加线程
if (c == capacity)
signalNotFull();
return x;
}
private E dequeue() {
Node<E> h = head;//获取头结点
Node<E> first = h.next; 获取头结的下一个节点(要删除的节点)
h.next = h; // help GC//自己next指向自己,即被删除
head = first;//更新头结点
E x = first.item;//获取删除节点的值
first.item = null;//清空数据,因为first变成头结点是不能带数据的,这样也就删除队列的带数据的第一个节点
return x;
}poll方法也比较简单,如果队列没有数据就返回null,如果队列有数据,那么就取出来,如果队列还有数据那么唤醒等待在条件对象notEmpty上的消费线程。然后判断if (c == capacity)为true就唤醒添加线程,这点与前面分析if(c==0)是一样的道理。因为只有可能队列满了,notFull条件对象上才可能存在等待的添加线程。
public E take() throws InterruptedException {
E x;
int c = -1;
//获取当前队列大小
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();//可中断
try {
//如果队列没有数据,挂机当前线程到条件对象的等待队列中
while (count.get() == 0) {
notEmpty.await();
}
//如果存在数据直接删除并返回该数据
x = dequeue();
c = count.getAndDecrement();//队列大小减1
if (c > 1)
notEmpty.signal();//还有数据就唤醒后续的消费线程
} finally {
takeLock.unlock();
}
//满足条件,唤醒条件对象上等待队列中的添加线程
if (c == capacity)
signalNotFull();
return x;
}take方法是一个可阻塞可中断的移除方法,主要做了两件事,一是,如果队列没有数据就挂起当前线程到 notEmpty条件对象的等待队列中一直等待,如果有数据就删除节点并返回数据项,同时唤醒后续消费线程,二是尝试唤醒条件对象notFull上等待队列中的添加线程。 到此关于remove、poll、take的实现也分析完了,其中只有take方法具备阻塞功能。remove方法则是成功返回true失败返回false,poll方法成功返回被移除的值,失败或没数据返回null。下面再看看两个检查方法,即peek和element
//构造方法,head 节点不存放数据
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
public E element() {
E x = peek();//直接调用peek
if (x != null)
return x;
else
throw new NoSuchElementException();//没数据抛异常
}
public E peek() {
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
//获取头结节点的下一个节点
Node<E> first = head.next;
if (first == null)
return null;//为null就返回null
else
return first.item;//返回值
} finally {
takeLock.unlock();
}
}从代码来看,head头结节点在初始化时是本身不带数据的,仅仅作为头部head方便我们执行链表的相关操作。peek返回直接获取头结点的下一个节点返回其值,如果没有值就返回null,有值就返回节点对应的值。element方法内部调用的是peek,有数据就返回,没数据就抛异常。下面我们最后来看两个根据时间阻塞的方法,比较有意思,利用的Conditin来实现的。
//在指定时间内阻塞添加的方法,超时就结束
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (e == null) throw new NullPointerException();
//将时间转换成纳秒
long nanos = unit.toNanos(timeout);
int c = -1;
//获取锁
final ReentrantLock putLock = this.putLock;
//获取当前队列大小
final AtomicInteger count = this.count;
//锁中断(如果需要)
putLock.lockInterruptibly();
try {
//判断队列是否满
while (count.get() == capacity) {
if (nanos <= 0)
return false;
//如果队列满根据阻塞的等待
nanos = notFull.awaitNanos(nanos);
}
//队列没满直接入队
enqueue(new Node<E>(e));
c = count.getAndIncrement();
//唤醒条件对象上等待的线程
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
//唤醒消费线程
if (c == 0)
signalNotEmpty();
return true;
}对于这个offer方法,我们重点来看看阻塞的这段代码
//判断队列是否满
while (count.get() == capacity) {
if (nanos <= 0)
return false;
//如果队列满根据阻塞的等待
nanos = notFull.awaitNanos(nanos);
}
//CoditionObject(Codition的实现类)中的awaitNanos方法
public final long awaitNanos(long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//这里是将当前添加线程封装成NODE节点加入Condition的等待队列中
//注意这里的NODE是AQS的内部类Node
Node node = addConditionWaiter();
//加入等待,那么就释放当前线程持有的锁
int savedState = fullyRelease(node);
//计算过期时间
final long deadline = System.nanoTime() + nanosTimeout;
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (nanosTimeout <= 0L) {
transferAfterCancelledWait(node);
break;
}
//主要看这里!!由于是while 循环,这里会不断判断等待时间
//nanosTimeout 是否超时
//static final long spinForTimeoutThreshold = 1000L;
if (nanosTimeout >= spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);//挂起线程
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
//重新计算剩余等待时间,while循环中继续判断下列公式
//nanosTimeout >= spinForTimeoutThreshold
nanosTimeout = deadline - System.nanoTime();
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return deadline - System.nanoTime();
}awaitNanos方法中,根据传递进来的时间计算超时阻塞nanosTimeout,然后通过while循环中判断nanosTimeout >= spinForTimeoutThreshold 该公式是否成立,当其为true时则说明超时时间nanosTimeout 还未到期,再次计算nanosTimeout = deadline - System.nanoTime();即nanosTimeout ,持续判断,直到nanosTimeout 小于spinForTimeoutThreshold结束超时阻塞操作,方法也就结束。这里的spinForTimeoutThreshold其实更像一个经验值,因为非常短的超时等待无法做到十分精确,因此采用了spinForTimeoutThreshold这样一个临界值。offer(E e, long timeout, TimeUnit unit)方法内部正是利用这样的Codition的超时等待awaitNanos方法实现添加方法的超时阻塞操作。同样对于poll(long timeout, TimeUnit unit)方法也是一样的道理。
LinkedBlockingQueue和ArrayBlockingQueue迥异
通过上述的分析,对于LinkedBlockingQueue和ArrayBlockingQueue的基本使用以及内部实现原理我们已较为熟悉了,这里我们就对它们两间的区别来个小结
1.队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE),对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
2.数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
3.由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
4.两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
定义
支持阻塞的插入方法:意思是当队列满时,队列会阻塞插入元素的线程,直到队列不满。支持阻塞的移除方法:意思是在队列为空时,获取元素的线程会等待队列变为非空。
阻塞队列常用于生产者和消费者的场景,生产者是向队列里添加元素的线程,消费者是从队列里取元素的线程。阻塞队列就是生产者用来存放元素、消费者用来获取元素的容器。
ArrayBlockingQueue
由数组组成的有界阻塞队列。
一个建立在数组之上被BlockingQueue绑定的阻塞队列。这个队列元素顺序是先进先出。队列的头部是在队列中待的时间最长的元素。队列的尾部是再队列中待的时间最短的元素。新的元素会被插入到队列尾部,并且队列从队列头部获取元素。这是一个典型的绑定缓冲,在这个缓冲区中,有一个固定大小的数组持有生产者插入的数据,并且消费者会提取这些数据。一旦这个类被创建,那么这个数组的容量将不能再被改变。尝试使用put操作给一个满队列插入元素将导致这个操作被阻塞;尝试从空队列中取元素也会被阻塞。
这个类推荐了一个可选的公平策略来排序等待的生产者和消费者线程。默认的,这个顺序是不确定的。但是队列会使用公平的设置true来使线程按照先进先出顺序访问。通常公平性会减少吞吐量但是却减少了可变性以及避免了线程饥饿。
ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true);源码分析
/**
*capacity指定队列的大小
*fair指定是否公平
*/
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
// 这两个notEmpty和notFull参数实际上是Condition,而Condition可以把它看做一个阻塞信号
// Condition的子类ConditionObject(是AbstractQueuedSynchronizer的内部类)拥有两个方法signal和
// signalAll方法,前一个方法是唤醒队列中得第一个线程,而signalAll是唤醒队列中得所有等待线程,
// 但是只有一个等待的线程会被选择,这两个方法可以看做notify和notifyAll的变体。
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
在这个阻塞队列的insert和remove方法中都会被调用signal来唤醒等待线程,在put方法中,如果队列已经满了,则会调用await方法来,直到队列有空位,才会调用insert方法插入元素。源代码如下:
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 线程可以被打断
lock.lockInterruptibly();
try {
// 如果队列满进行等待
while (count == items.length)
notFull.await();
insert(e);
} finally {
lock.unlock();
}
}
private void insert(E x) {
items[putIndex] = x;
putIndex = inc(putIndex);
++count;
notEmpty.signal();
}
如果不想在队列满了之后,再插入元素被阻塞,提供了offer方法,这个offer方法有重载方法,调用offer(E e)方法时,如果队列已经满了,那么会直接返回一个false,如果没有满,则直接调用insert插入到队列中;调用offer(E e, long timeout, TimeUnit unit)方法时,会在队列满了之后阻塞队列,但是这里可以由开发人员设置超时时间,如果超时时队列还是满的,则会以false返回。源码如下所示
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
checkNotNull(e);
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length) {
if (nanos <= 0)
return false;
nanos = notFull.awaitNanos(nanos);
}
insert(e);
return true;
} finally {
lock.unlock();
}
}
public boolean offer(E e) {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
if (count == items.length)
return false;
else {
insert(e);
return true;
}
} finally {
lock.unlock();
}
}
插入数据有阻塞和非阻塞之分,那么提取数据也肯定就有阻塞与非阻塞之分了。
其中take方法是个阻塞方法,当队列为空时,就被阻塞,源码如下:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return extract();
} finally {
lock.unlock();
}
}
方法poll是重载方法,跟offer相对,也有基础方法和超时方法之分。
在这个类中还提供了peek方法来提取数据。下面看看pool的源码
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return (count == 0) ? null : extract();
} finally {
lock.unlock();
}
}
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0) {
if (nanos <= 0)
return null;
nanos = notEmpty.awaitNanos(nanos);
}
return extract();
} finally {
lock.unlock();
}
}
再来看看这个类中得迭代器。这个类中的迭代器是线程安全的,因为在实现的next和remove方法中都加了lock了
private class Itr implements Iterator<E> {
private int remaining; // Number of elements yet to be returned
private int nextIndex; // Index of element to be returned by next
private E nextItem; // Element to be returned by next call to next
private E lastItem; // Element returned by last call to next
private int lastRet; // Index of last element returned, or -1 if none
Itr() {
final ReentrantLock lock = ArrayBlockingQueue.this.lock;
lock.lock();
try {
lastRet = -1;
if ((remaining = count) > 0)
nextItem = itemAt(nextIndex = takeIndex);
} finally {
lock.unlock();
}
}
public boolean hasNext() {
return remaining > 0;
}
public E next() {
final ReentrantLock lock = ArrayBlockingQueue.this.lock;
lock.lock(); //锁定
try {
if (remaining <= 0)
throw new NoSuchElementException();
lastRet = nextIndex;
E x = itemAt(nextIndex); // check for fresher value
if (x == null) {
x = nextItem; // we are forced to report old value
lastItem = null; // but ensure remove fails
}
else
lastItem = x;
while (--remaining > 0 && // skip over nulls
(nextItem = itemAt(nextIndex = inc(nextIndex))) == null)
;
return x;
} finally {
lock.unlock();
}
}
public void remove() {
final ReentrantLock lock = ArrayBlockingQueue.this.lock;
lock.lock();
try {
int i = lastRet;
if (i == -1)
throw new IllegalStateException();
lastRet = -1;
E x = lastItem;
lastItem = null;
// only remove if item still at index
if (x != null && x == items[i]) {
boolean removingHead = (i == takeIndex);
removeAt(i);
if (!removingHead)
nextIndex = dec(nextIndex);
}
} finally {
lock.unlock();
}
}
}
总结
1.一旦创建,则容量不能再改动
2.这个类是线程安全的,并且迭代器也是线程安全的
3.这个类的put和take方法分别会在队列满了和队列空了之后被阻塞操作。
4.这个类提供了offer和poll方法来插入和提取元素,而不会在队列满了或者队列为空时阻塞操作。
5.这个队列的锁默认是不公平策略,即唤醒线程的顺序是不确定的。
LinkedBlockingQueue
一个由链表结构组成的有界阻塞队列。链表是单向链表,而不是双向链表
ArrayBlockingQueue只有1个锁,添加数据和删除数据的时候只能有1个被执行,不允许并行执行。而LinkedBlockingQueue有2个锁,放锁和拿锁,添加数据和删除数据是可以并行进行的,当然添加数据和删除数据的时候只能有1个线程各自执行。
LinkedBlockingQueue入队方法:add、offer、put方法。
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
public boolean offer(E e) {
if (e == null) throw new NullPointerException(); // 不允许空元素
final AtomicInteger count = this.count;
if (count.get() == capacity) // 如果容量满了,返回false
return false;
int c = -1;
Node<E> node = new Node(e); // 容量没满,以新元素构造节点
final ReentrantLock putLock = this.putLock;
putLock.lock(); // 放锁加锁,保证调用offer方法的时候只有1个线程
try {
if (count.get() < capacity) { // 再次判断容量是否已满,因为可能拿锁在进行消费数据,没满的话继续执行
enqueue(node); // 节点添加到链表尾部
c = count.getAndIncrement(); // 元素个数+1
if (c + 1 < capacity) // 如果容量还没满
notFull.signal(); // 在放锁的条件对象notFull上唤醒正在等待的线程,表示可以再次往队列里面加数据了,队列还没满
}
} finally {
putLock.unlock(); // 释放放锁,让其他线程可以调用offer方法
}
if (c == 0) // 由于存在放锁和拿锁,这里可能拿锁一直在消费数据,count会变化。这里的if条件表示如果队列中还有1条数据
signalNotEmpty(); // 在拿锁的条件对象notEmpty上唤醒正在等待的1个线程,表示队列里还有1条数据,可以进行消费
return c >= 0; // 添加成功返回true,否则返回false
}
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException(); // 不允许空元素
int c = -1;
Node<E> node = new Node(e); // 以新元素构造节点
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly(); // 放锁加锁,保证调用put方法的时候只有1个线程
try {
while (count.get() == capacity) { // 如果容量满了
notFull.await(); // 阻塞并挂起当前线程
}
enqueue(node); // 节点添加到链表尾部
c = count.getAndIncrement(); // 元素个数+1
if (c + 1 < capacity) // 如果容量还没满
notFull.signal(); // 在放锁的条件对象notFull上唤醒正在等待的线程,表示可以再次往队列里面加数据了,队列还没满
} finally {
putLock.unlock(); // 释放放锁,让其他线程可以调用put方法
}
if (c == 0) // 由于存在放锁和拿锁,这里可能拿锁一直在消费数据,count会变化。这里的if条件表示如果队列中还有1条数据
signalNotEmpty(); // 在拿锁的条件对象notEmpty上唤醒正在等待的1个线程,表示队列里还有1条数据,可以进行消费
}
ArrayBlockingQueue中放入数据阻塞的时候,需要消费数据才能唤醒。而LinkedBlockingQueue中放入数据阻塞的时候,因为它内部有2个锁,可以并行执行放入数据和消费数据,不仅在消费数据的时候进行唤醒插入阻塞的线程,同时在插入的时候如果容量还没满,也会唤醒插入阻塞的线程。
LinkedBlockingQueue出队方法:poll、take、remove方法
public E poll() {
final AtomicInteger count = this.count;
if (count.get() == 0) // 如果元素个数为0
return null; // 返回null
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock(); // 拿锁加锁,保证调用poll方法的时候只有1个线程
try {
if (count.get() > 0) { // 判断队列里是否还有数据
x = dequeue(); // 删除头结点
c = count.getAndDecrement(); // 元素个数-1
if (c > 1) // 如果队列里还有元素
notEmpty.signal(); // 在拿锁的条件对象notEmpty上唤醒正在等待的线程,表示队列里还有数据,可以再次消费
}
} finally {
takeLock.unlock(); // 释放拿锁,让其他线程可以调用poll方法
}
if (c == capacity) // 由于存在放锁和拿锁,这里可能放锁一直在添加数据,count会变化。这里的if条件表示如果队列中还可以再插入数据
signalNotFull(); // 在放锁的条件对象notFull上唤醒正在等待的1个线程,表示队列里还能再次添加数据
return x;
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly(); // 拿锁加锁,保证调用take方法的时候只有1个线程
try {
while (count.get() == 0) { // 如果队列里已经没有元素了
notEmpty.await(); // 阻塞并挂起当前线程
}
x = dequeue(); // 删除头结点
c = count.getAndDecrement(); // 元素个数-1
if (c > 1) // 如果队列里还有元素
notEmpty.signal(); // 在拿锁的条件对象notEmpty上唤醒正在等待的线程,表示队列里还有数据,可以再次消费
} finally {
takeLock.unlock(); // 释放拿锁,让其他线程可以调用take方法
}
if (c == capacity) // 由于存在放锁和拿锁,这里可能放锁一直在添加数据,count会变化。这里的if条件表示如果队列中还可以再插入数据
signalNotFull(); // 在放锁的条件对象notFull上唤醒正在等待的1个线程,表示队列里还能再次添加数据
return x;
}
public boolean remove(Object o) {
if (o == null) return false;
fullyLock(); // remove操作要移动的位置不固定,2个锁都需要加锁
try {
for (Node<E> trail = head, p = trail.next; // 从链表头结点开始遍历
p != null;
trail = p, p = p.next) {
if (o.equals(p.item)) { // 判断是否找到对象
unlink(p, trail); // 修改节点的链接信息,同时调用notFull的signal方法
return true;
}
}
return false;
} finally {
fullyUnlock(); // 2个锁解锁
}
}
LinkedBlockingQueue的take方法对于没数据的情况下会阻塞,poll方法删除链表头结点,remove方法删除指定的对象。需要注意的是remove方法由于要删除的数据的位置不确定,需要2个锁同时加锁
PriorityBlockingQueue
一个支持优先级排序的无界阻塞队列。
PriorityBlockingQueue通过使用堆这种数据结构实现将队列中的元素按照某种排序规则进行排序,从而改变先进先出的队列顺序,提供开发者改变队列中元素的顺序的能力。队列中的元素必须是可比较的,即实现Comparable接口,或者在构建函数时提供可对队列元素进行比较的Comparator对象。堆是一种二叉树结构,堆的根元素是整个树的最大值或者最小值(称为大顶堆或者小顶堆),同时堆的每个子树都是满足堆的树结构。由于堆的顶部是最大值或者最小值,所以每次从堆获取数据都是直接获取堆顶元素,然后再将堆调整成堆结构。
入队方法:
此处虽然PriorityBlockingQueue是阻塞队列,但是其并没有阻塞的入队方法,因为该队列是无界的,所以入队是不会阻塞的。
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();// 加锁
try {
// 通过PriorityQueue入队一个元素
boolean ok = q.offer(e);
assert ok;
// 唤醒等在notEmpty上的线程
notEmpty.signal();
return true;
} finally {
lock.unlock();
}
}
offer()方法正如在结构介绍中提到的通过组合的方式,通过外部加锁内部直接调用PriorityQueue的offer()方法。所以主要的工作在PriorityQueue内部
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
// 内部使用数组保存队列的元素,所以如果队列的大小超过数组的长度,则需要进行扩容
// 扩容的标准是:<64扩大2倍,>=64则扩大1.5倍
if (i >= queue.length)
grow(i + 1);
size = i + 1;
// i==0表示队列目前没有元素,则直接将带插入元素添加到数组即可
if (i == 0)
queue[0] = e;
else
// 将带插入元素添加到队列的最后一个元素,然后自下而上调整堆
siftUp(i, e);
return true;
}
private void siftUp(int k, E x) {
// 两者逻辑一样,只是采用的比较方式不同而已
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
private void siftUpUsingComparator(int k, E x) {
// 循环,直到根元素
while (k > 0) {
// 寻找k的父元素下标,固定规则
int parent = (k - 1) >>> 1;
Object e = queue[parent];
// 如果x >= e,即子节点>=父节点,则直接退出循环
// 解释:自下而上一般出现在插入元素时调用,插入元素是插入到队列的最后,则需要将该元素调整到合适的位置
// 即从队列的最后往上调整堆,直到不小于其父节点为止,相当于冒泡
if (comparator.compare(x, (E) e) >= 0)
break;
// 如果当前节点<其父节点,则将其与父节点进行交换,并继续往上访问父节点
queue[k] = e;
k = parent;
}
queue[k] = x;
}
入队时通过调用ReentrantLock.lock()进行加锁,然后调用PriorityQueue.offer()方法进行入队操作,最后通过Condition.signal()唤醒等待其上的线程。PriorityQueue.offer()方法将元素插入到队列的最后,然后自上而下调整堆
出队方法
poll(long, TimeUnit)是poll()的阻塞版本,同时take()是无限阻塞版poll()(即无期限阻塞,直到获取到数据),通过Condition.awaitNanos()实现阻塞
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
// 此处不同于其他非阻塞方法,调用了ReentrantLock的lockInterruptibly()方法,考虑了当前线程是否被打断
lock.lockInterruptibly();
try {
// 循环,直到获取到元素,或者到达等待时间
for (;;) {
// 从PriorityQueue获取一个元素,该方法不会阻塞
E x = q.poll();
if (x != null)
return x;
// 此处的nanos会因为每次调用Condition.awaitNanos而减少,如果<0则说明累计等待时间已达到设定的等待时间
if (nanos <= 0)
return null;
try {
// Condition.awaitNanos指定等待时间,但是有可能会被“虚假唤醒”(参考API),导致等待时间未满,返回值即剩余的等待时间
// 所以需要在外层进行循环,每次等待的时候是上次剩余的时间
nanos = notEmpty.awaitNanos(nanos);
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
throw ie;
}
}
} finally {
lock.unlock();
}
}
PriorityQueue.poll()
public E poll() {
// size==0队列为0,直接返回null
if (size == 0)
return null;
int s = --size;
modCount++;
// 出队总是将数组的第一个元素进行出队,
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
// 同时将队列的最后一个元素放到第一个位置,然后自上而下调整堆
siftDown(0, x);
return result;
}
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
private void siftDownUsingComparator(int k, E x) {
// 由于堆是一个二叉树,所以size/2是树中的最后一个非叶子节点
// 如果k是叶子节点,那么其无子节点,则不需要再往下调整堆
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = queue[child];
// 右节点
int right = child + 1;
// 找出两个子节点以及父节点中较小的一个
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
// 如果父节点最小,则无需继续往下调整堆
if (comparator.compare(x, (E) c) <= 0)
break;
// 否则将父节点与两个子节点中较小的一个交换,然后往下继续调整
queue[k] = c;
k = child;
}
queue[k] = x;
}
public boolean remove(Object o) {
// 在队列中查询元素,返回待删除元素在队列中的位置
int i = indexOf(o);
if (i == -1)
return false;
else {
// 删除指定位置的元素
removeAt(i);
return true;
}
}
private E removeAt(int i) {
assert i >= 0 && i < size;
modCount++;
int s = --size;
if (s == i) // removed last element
queue[i] = null;
else {
// 删除最后一个元素,将最后一个元素放到i的位置,然后从i开始上而下调整堆
E moved = (E) queue[s];
queue[s] = null;
siftDown(i, moved);
// 如果queue[i] == moved说明未发生调整,那么则需要自下而上调整堆
if (queue[i] == moved) {
siftUp(i, moved);
if (queue[i] != moved)
return moved;
}
}
return null;
}
当删除堆中的一个元素时,将堆的最后一个元素移动到被删除的位置,然后将最后一个位置值为NULL,当把最后一个元素移动到堆中的某个位置时,这时首先需要从该位置开始自上而下的调整堆,如果该位置的元素在调整时发生变化,即堆有变化,则说明该元素是大于其子节点的,那么该节点就不可能小于其上的父节点(因为堆的结构是传递性的,即子节点小于父节点,其孙子节点同时小于其父节点),所以就不需要再向上调整了;但是如果未发生变化,则说明该位置的节点小于其子节点,那么就无法保证其一定比父节点大,所以需要从该节点开始自上而下的调整堆
DelayQueue
一个使用优先级队列实现的无界阻塞队列。
DelayQueue是一个支持延时获取元素的无界阻塞队列。队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。
DelayQueue非常有用,可以将DelayQueue运用在以下应用场景。
缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
定时任务调度:使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,比如TimerQueue就是使用DelayQueue实现的。
1、如何实现delayed接口
DelayQueue队列的元素必须实现Delayed接口。我们可以参考ScheduledThreadPoolExecutor里ScheduledFutureTask类的实现,一共有三步。
第一步:在对象创建的时候,初始化基本数据。使用time记录当前对象延迟到什么时候可以使用,使用sequenceNumber来标识元素在队列中的先后顺序。代码如下。
private static final AtomicLong sequencer = new AtomicLong(0);
ScheduledFutureTask(Runnable r, V result, long ns, long period) {
super(r, result);
this.time = ns;
this.period = period;
this.sequenceNumber = sequencer.getAndIncrement();
}
第二步:实现getDelay方法,该方法返回当前元素还需要延时多长时间,单位是纳秒,代码如下
public long getDelay(TimeUnit unit) {
return unit.convert(time - now(), TimeUnit.NANOSECONDS);
}
通过构造函数可以看出延迟时间参数ns的单位是纳秒,自己设计的时候最好使用纳秒,因为实现getDelay()方法时可以指定任意单位,一旦以秒或分作为单位,而延时时间又精确不到纳秒就麻烦了。使用时请注意当time小于当前时间时,getDelay会返回负数
第三步:实现compareTo方法来指定元素的顺序。例如,让延时时间最长的放在队列的末尾。实现代码如下。
public int compareTo(Delayed other) {
if (other == this) // compare zero ONLY if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<> x = (ScheduledFutureTask<>)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long d = (getDelay(TimeUnit.NANOSECONDS) -
other.getDelay(TimeUnit.NANOSECONDS));
return (d == 0) 0 : ((d < 0) -1 : 1);
}
2、如何实现延时阻塞队列
元素没有达到延时时间,就阻塞当前线程
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null) {
if (nanos <= 0)
return null;
else
nanos = available.awaitNanos(nanos);
} else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay <= 0)
return q.poll();
if (nanos <= 0)
return null;
if (nanos < delay || leader != null)
nanos = available.awaitNanos(nanos);
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
long timeLeft = available.awaitNanos(delay);
nanos -= delay - timeLeft;
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}
代码中的变量leader是一个等待获取队列头部元素的线程。如果leader不等于空,表示已经有线程在等待获取队列的头元素。所以,使用await()方法让当前线程等待信号。如果leader等于空,则把当前线程设置成leader,并使用awaitNanos()方法让当前线程等待接收信号或等待delay时间
SynchronousQueue
一个不存储元素的阻塞队列。
SynchronousQueue是一个不存储元素的阻塞队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。它支持公平访问队列。默认情况下线程采用非公平性策略访问队列。使用以下构造方法可以创建公平性访问的SynchronousQueue,如果设置为true,则等待的线程会采用先进先出的
顺序访问队列。
public SynchronousQueue(boolean fair) {
transferer = fair new TransferQueue() : new TransferStack();
}
SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合传递性场景。SynchronousQueue的吞吐量高于LinkedBlockingQueue和ArrayBlockingQueue,感觉使用的场景不多,这里就不详细介绍了。
LinkedTransferQueue
一个由链表结构组成的无界阻塞队列。
LinkedTransferQueue是一个由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻
塞队列,LinkedTransferQueue多了tryTransfer和transfer方法。
(1)transfer方法
如果当前有消费者正在等待接收元素(消费者使用take()方法或带时间限制的poll()方法时),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer方法会将元素存放在队列的tail节点,并等到该元素被消费者消费了才返回。transfer方法的关键代码如下。
Node pred = tryAppend(s, haveData);
return awaitMatch(s, pred, e, (how == TIMED), nanos);
第一行代码是试图把存放当前元素的s节点作为tail节点。第二行代码是让CPU自旋等待消费者消费元素。因为自旋会消耗CPU,所以自旋一定的次数后使用Thread.yield()方法来暂停当前正在执行的线程,并执行其他线程。
(2)tryTransfer方法
tryTransfer方法是用来试探生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回false。和transfer方法的区别是tryTransfer方法无论消费者是否接收,方法立即返回,而transfer方法是必须等到消费者消费了才返回。对于带有时间限制的tryTransfer(E e,long timeout,TimeUnit unit)方法,试图把生产者传入的元素直接传给消费者,但是如果没有消费者消费该元素则等待指定的时间再返回,如果超时还没消费元素,则返回false,如果在超时时间内消费了元素,则返回true。
LinkedBlockingDeque
一个由链表结构组成的双向阻塞队列。LinkedBlockingDeque是一个由链表结构组成的双向阻塞队列。所谓双向队列指的是可以从队列的两端插入和移出元素。双向队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列,LinkedBlockingDeque多了addFirst、
addLast、offerFirst、offerLast、peekFirst和peekLast等方法,以First单词结尾的方法,表示插入、获取(peek)或移除双端队列的第一个元素。以Last单词结尾的方法,表示插入、获取或移除双端队列的最后一个元素。另外,插入方法add等同于addLast,移除方法remove等效于removeFirst。但是take方法却等同于takeFirst,不知道是不是JDK的bug,使用时还是用带有First和Last后缀的方法更清楚。
1. 什么是阻塞队列?
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
阻塞队列提供了四种处理方法:
| 方法处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
- 抛出异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出IllegalStateException(“Queue full”)异常。当队列为空时,从队列里获取元素时会抛出NoSuchElementException异常 。
- 返回特殊值:插入方法会返回是否成功,成功则返回true。移除方法,则是从队列里拿出一个元素,如果没有则返回null
- 一直阻塞:当阻塞队列满时,如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里take元素,队列也会阻塞消费者线程,直到队列可用。
- 超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出。
2. Java里的阻塞队列
JDK7提供了7个阻塞队列。分别是
- ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
- PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
- DelayQueue:一个使用优先级队列实现的无界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
ArrayBlockingQueue
ArrayBlockingQueue是一个用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证访问者公平的访问队列,所谓公平访问队列是指阻塞的所有生产者线程或消费者线程,当队列可用时,可以按照阻塞的先后顺序访问队列,即先阻塞的生产者线程,可以先往队列里插入元素,先阻塞的消费者线程,可以先从队列里获取元素。通常情况下为了保证公平性会降低吞吐量。我们可以使用以下代码创建一个公平的阻塞队列:
1 |
ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true); |
访问者的公平性是使用可重入锁实现的,代码如下:
1 |
public ArrayBlockingQueue(int capacity, boolean fair) { |
2 |
if (capacity <= 0) |
3 |
throw new IllegalArgumentException(); |
4 |
this.items = new Object[capacity]; |
5 |
lock = new ReentrantLock(fair); |
6 |
notEmpty = lock.newCondition(); |
7 |
notFull = lock.newCondition(); |
8 |
} |
LinkedBlockingQueue
LinkedBlockingQueue是一个用链表实现的有界阻塞队列。此队列的默认和最大长度为Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。
PriorityBlockingQueue
PriorityBlockingQueue是一个支持优先级的无界队列。默认情况下元素采取自然顺序排列,也可以通过比较器comparator来指定元素的排序规则。元素按照升序排列。
DelayQueue
DelayQueue是一个支持延时获取元素的无界阻塞队列。队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。我们可以将DelayQueue运用在以下应用场景:
- 缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
- 定时任务调度。使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如TimerQueue就是使用DelayQueue实现的。
队列中的Delayed必须实现compareTo来指定元素的顺序。比如让延时时间最长的放在队列的末尾。实现代码如下:
01 |
public int compareTo(Delayed other) { |
02 |
if (other == this) // compare zero ONLY if same object |
03 |
return 0; |
04 |
if (other instanceof ScheduledFutureTask) { |
05 |
ScheduledFutureTask x = (ScheduledFutureTask)other; |
06 |
long diff = time - x.time; |
07 |
if (diff < 0) |
08 |
return -1; |
09 |
else if (diff > 0) |
10 |
return 1; |
11 |
else if (sequenceNumber < x.sequenceNumber) |
12 |
return -1; |
13 |
else |
14 |
return 1; |
15 |
} |
16 |
long d = (getDelay(TimeUnit.NANOSECONDS) - |
17 |
other.getDelay(TimeUnit.NANOSECONDS)); |
18 |
return (d == 0) ? 0 : ((d < 0) ? -1 : 1); |
19 |
} |
如何实现Delayed接口
我们可以参考ScheduledThreadPoolExecutor里ScheduledFutureTask类。这个类实现了Delayed接口。首先:在对象创建的时候,使用time记录前对象什么时候可以使用,代码如下:
1 |
ScheduledFutureTask(Runnable r, V result, long ns, long period) { |
2 |
super(r, result); |
3 |
this.time = ns; |
4 |
this.period = period; |
5 |
this.sequenceNumber = sequencer.getAndIncrement(); |
6 |
} |
然后使用getDelay可以查询当前元素还需要延时多久,代码如下:
public long getDelay(TimeUnit unit) {
return unit.convert(time - now(), TimeUnit.NANOSECONDS);
}
通过构造函数可以看出延迟时间参数ns的单位是纳秒,自己设计的时候最好使用纳秒,因为getDelay时可以指定任意单位,一旦以纳秒作为单位,而延时的时间又精确不到纳秒就麻烦了。使用时请注意当time小于当前时间时,getDelay会返回负数。
如何实现延时队列
延时队列的实现很简单,当消费者从队列里获取元素时,如果元素没有达到延时时间,就阻塞当前线程。
1 |
long delay = first.getDelay(TimeUnit.NANOSECONDS); |
2 |
if (delay <= 0) |
3 |
return q.poll(); |
4 |
else if (leader != null) |
5 |
available.await(); |
SynchronousQueue
SynchronousQueue是一个不存储元素的阻塞队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合于传递性场景,比如在一个线程中使用的数据,传递给另外一个线程使用,SynchronousQueue的吞吐量高于LinkedBlockingQueue 和 ArrayBlockingQueue。
LinkedTransferQueue
LinkedTransferQueue是一个由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻塞队列LinkedTransferQueue多了tryTransfer和transfer方法。
transfer方法。如果当前有消费者正在等待接收元素(消费者使用take()方法或带时间限制的poll()方法时),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer方法会将元素存放在队列的tail节点,并等到该元素被消费者消费了才返回。transfer方法的关键代码如下:
1 |
Node pred = tryAppend(s, haveData); |
2 |
return awaitMatch(s, pred, e, (how == TIMED), nanos); |
第一行代码是试图把存放当前元素的s节点作为tail节点。第二行代码是让CPU自旋等待消费者消费元素。因为自旋会消耗CPU,所以自旋一定的次数后使用Thread.yield()方法来暂停当前正在执行的线程,并执行其他线程。
tryTransfer方法。则是用来试探下生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回false。和transfer方法的区别是tryTransfer方法无论消费者是否接收,方法立即返回。而transfer方法是必须等到消费者消费了才返回。
对于带有时间限制的tryTransfer(E e, long timeout, TimeUnit unit)方法,则是试图把生产者传入的元素直接传给消费者,但是如果没有消费者消费该元素则等待指定的时间再返回,如果超时还没消费元素,则返回false,如果在超时时间内消费了元素,则返回true。
LinkedBlockingDeque
LinkedBlockingDeque是一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两端插入和移出元素。双端队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列,LinkedBlockingDeque多了addFirst,addLast,offerFirst,offerLast,peekFirst,peekLast等方法,以First单词结尾的方法,表示插入,获取(peek)或移除双端队列的第一个元素。以Last单词结尾的方法,表示插入,获取或移除双端队列的最后一个元素。另外插入方法add等同于addLast,移除方法remove等效于removeFirst。但是take方法却等同于takeFirst,不知道是不是Jdk的bug,使用时还是用带有First和Last后缀的方法更清楚。在初始化LinkedBlockingDeque时可以初始化队列的容量,用来防止其再扩容时过渡膨胀。另外双向阻塞队列可以运用在“工作窃取”模式中。
3. 阻塞队列的实现原理
如果队列是空的,消费者会一直等待,当生产者添加元素时候,消费者是如何知道当前队列有元素的呢?如果让你来设计阻塞队列你会如何设计,让生产者和消费者能够高效率的进行通讯呢?让我们先来看看JDK是如何实现的。
使用通知模式实现。所谓通知模式,就是当生产者往满的队列里添加元素时会阻塞住生产者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。通过查看JDK源码发现ArrayBlockingQueue使用了Condition来实现,代码如下:
01 |
private final Condition notFull; |
02 |
private final Condition notEmpty; |
03 |
04 |
public ArrayBlockingQueue(int capacity, boolean fair) { |
05 |
//省略其他代码 |
06 |
notEmpty = lock.newCondition(); |
07 |
notFull = lock.newCondition(); |
08 |
} |
09 |
10 |
public void put(E e) throws InterruptedException { |
11 |
checkNotNull(e); |
12 |
final ReentrantLock lock = this.lock; |
13 |
lock.lockInterruptibly(); |
14 |
try { |
15 |
while (count == items.length) |
16 |
notFull.await(); |
17 |
insert(e); |
18 |
} finally { |
19 |
lock.unlock(); |
20 |
} |
21 |
} |
22 |
23 |
public E take() throws InterruptedException { |
24 |
final ReentrantLock lock = this.lock; |
25 |
lock.lockInterruptibly(); |
26 |
try { |
27 |
while (count == 0) |
28 |
notEmpty.await(); |
29 |
return extract(); |
30 |
} finally { |
31 |
lock.unlock(); |
32 |
} |
33 |
} |
34 |
35 |
private void insert(E x) { |
36 |
items[putIndex] = x; |
37 |
putIndex = inc(putIndex); |
38 |
++count; |
39 |
notEmpty.signal(); |
40 |
} |
当我们往队列里插入一个元素时,如果队列不可用,阻塞生产者主要通过LockSupport.park(this);来实现
01 |
public final void await() throws InterruptedException { |
02 |
if (Thread.interrupted()) |
03 |
throw new InterruptedException(); |
04 |
Node node = addConditionWaiter(); |
05 |
int savedState = fullyRelease(node); |
06 |
int interruptMode = 0; |
07 |
while (!isOnSyncQueue(node)) { |
08 |
LockSupport.park(this); |
09 |
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) |
10 |
break; |
11 |
} |
12 |
if (acquireQueued(node, savedState) && interruptMode != THROW_IE) |
13 |
interruptMode = REINTERRUPT; |
14 |
if (node.nextWaiter != null) // clean up if cancelled |
15 |
unlinkCancelledWaiters(); |
16 |
if (interruptMode != 0) |
17 |
18 |
reportInterruptAfterWait(interruptMode); |
19 |
} |
继续进入源码,发现调用setBlocker先保存下将要阻塞的线程,然后调用unsafe.park阻塞当前线程。
1 |
public static void park(Object blocker) { |
2 |
Thread t = Thread.currentThread(); |
3 |
setBlocker(t, blocker); |
4 |
unsafe.park(false, 0L); |
5 |
setBlocker(t, null); |
6 |
} |
unsafe.park是个native方法,代码如下:
1 |
public native void park(boolean isAbsolute, long time); |
park这个方法会阻塞当前线程,只有以下四种情况中的一种发生时,该方法才会返回。
- 与park对应的unpark执行或已经执行时。注意:已经执行是指unpark先执行,然后再执行的park。
- 线程被中断时。
- 如果参数中的time不是零,等待了指定的毫秒数时。
- 发生异常现象时。这些异常事先无法确定。
我们继续看一下JVM是如何实现park方法的,park在不同的操作系统使用不同的方式实现,在linux下是使用的是系统方法pthread_cond_wait实现。实现代码在JVM源码路径src/os/linux/vm/os_linux.cpp里的 os::PlatformEvent::park方法,代码如下:
01 |
void os::PlatformEvent::park() { |
02 |
int v ; |
03 |
for (;;) { |
04 |
v = _Event ; |
05 |
if (Atomic::cmpxchg (v-1, &_Event, v) == v) break ; |
06 |
} |
07 |
guarantee (v >= 0, "invariant") ; |
08 |
if (v == 0) { |
09 |
// Do this the hard way by blocking ... |
10 |
int status = pthread_mutex_lock(_mutex); |
11 |
assert_status(status == 0, status, "mutex_lock"); |
12 |
guarantee (_nParked == 0, "invariant") ; |
13 |
++ _nParked ; |
14 |
while (_Event < 0) { |
15 |
status = pthread_cond_wait(_cond, _mutex); |
16 |
// for some reason, under 2.7 lwp_cond_wait() may return ETIME ... |
17 |
// Treat this the same as if the wait was interrupted |
18 |
if (status == ETIME) { status = EINTR; } |
19 |
assert_status(status == 0 || status == EINTR, status, "cond_wait"); |
20 |
} |
21 |
-- _nParked ; |
22 |
23 |
// In theory we could move the ST of 0 into _Event past the unlock(), |
24 |
// but then we'd need a MEMBAR after the ST. |
25 |
_Event = 0 ; |
26 |
status = pthread_mutex_unlock(_mutex); |
27 |
assert_status(status == 0, status, "mutex_unlock"); |
28 |
} |
29 |
guarantee (_Event >= 0, "invariant") ; |
30 |
} |
31 |
32 |
} |
pthread_cond_wait是一个多线程的条件变量函数,cond是condition的缩写,字面意思可以理解为线程在等待一个条件发生,这个条件是一个全局变量。这个方法接收两个参数,一个共享变量_cond,一个互斥量_mutex。而unpark方法在linux下是使用pthread_cond_signal实现的。park 在windows下则是使用WaitForSingleObject实现的。
当队列满时,生产者往阻塞队列里插入一个元素,生产者线程会进入WAITING (parking)状态。我们可以使用jstack dump阻塞的生产者线程看到这点:
1 |
"main" prio=5 tid=0x00007fc83c000000 nid=0x10164e000 waiting on condition [0x000000010164d000] |
2 |
java.lang.Thread.State: WAITING (parking) |
3 |
at sun.misc.Unsafe.park(Native Method) |
4 |
- parking to wait for <0x0000000140559fe8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) |
5 |
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:186) |
6 |
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2043) |
7 |
at java.util.concurrent.ArrayBlockingQueue.put(ArrayBlockingQueue.java:324) |
8 |
at blockingqueue.ArrayBlockingQueueTest.main(ArrayBlockingQueueTest.java:11) |