Cisco转发方式
多层交换原理
CAM and TCAM Tables
CAM表(对应的是MAC地址表):内容可寻址内存,存二进制的哈希值(MAC地址,VLAN ID ,端口ID做哈希),后续的话根据哈希值做匹配转发,交换机处理的时候看的是CAM表项,保持高的转发速率
内容可寻址存储器(CAM)是一种专用于进行查表操作的硬件芯片
CAM表(交换机用的)二层转发;以二进制进行工作:
基于0和1进行匹配;没有bit即被忽略
hit返回结果,即接口
用于MAC地址的查找
(通过二进制匹配,找到一个匹配的MAC地址,通过指针匹配MAC地址找到出接口,将数据帧从出接口发出去)
TCAM表(路由器用的)(ternary content addressable memory)三层转发;以二进制进行工作:
基于0、1和X(不关心)
最长匹配返回hit
表的结构有pattern和相关掩码组成
用于查找三层路由(比如ACL的匹配就是放到TCAM表去查找的)

【延伸】路由表里面:Route/mask 掩码位都匹配上,路由才算匹配上,最长匹配,匹配上以后通过指针找出接口,快速匹配
***************************************************************************
思科设备的转发方式:
1、进程转发
2、快速转发
3、CEF(FIB):CISCO的快速转发,FIB工作在转发层面,由CEF生成,不仅管理着路由条目,还管理着邻接表,通过查一张表实现转发
三层交换机的主要功能:
包交换(同一VLAN)
包的路由(不同VLAN或广播域)
三层交换机同时具备二层和三层的功能,收到数据帧三层交换机如何判断是做二层处理还是三层处理?
看目的MAC地址是不是自己接口的MAC。如果数据帧的目的MAC地址是本接口MAC地址,需要做三层转发;如果不是做二层转发。
三层交换机的SVI接口(三层交换机的虚接口)有MAC地址吗?
SVI接口有MAC地址,在思科交换机上所有SVI接口用同一个MAC地址。交换机连了10个VLAN,MAC地址共用一个有影响吗?多个VLAN-interface用一个MAC地址没有问题
*************************************************************************
进程转发:
每个IP包都是由CPU处理的,通过查表找到出接口
【延伸】盒式的,在交换机上面端口号从1开始,路由器从0开始?
在交换机上,0是代表CPU的,如果报文需要发送给0端口,代表报文是需要交给CPU来处理,在进程交换年代,每一个报文都是需要通过CPU来处理的,CPU查表转发,每一个报文经过CPU处理,CPU压力会很大,速度会很慢。由于进程交换的缺陷,后续推出了快速交换的技术
快速交换技术(CPU需要处理一个流的第一个包的):还是需要CPU处理
一次交换,多次转发:第一个报文需要CPU处理,后续直接根据缓存表去做转发。处理完第一个报文以后,会在本地生成一个cache缓存,在缓存里面会缓存报文的元组哈希值,元组包括源目的IP,源目的端口,协议ID,后续会对元组做哈希,哈希以后和缓存做比对,如果一样说明来自同一个流,不用再去CPU做处理了,直接根据缓存表做转发就行。
思科里面快速交换:Routing Cache
首先,CPU处理,找到表项转发;同时,将对应 关系放到缓存里面,后续来自同一个流的报文查缓存做转发就可以了
接口下no ip cef(no ip route-cache cef),全局下需要开启CEF
怎么看一个包是否需要经过CPU处理,怎么判断?
一个IP包过来以后,元组一样就代表同一个流。先 查缓存,如果缓存里面没有一个对应的哈希值,就说明这个IP包不在这个缓存里面,就需要上传到CPU去处理,CPU处理之后就将这个元组放在cache里面这种方式叫做一次交换,多次转发
2500/2600低端路由器里面有快速转发
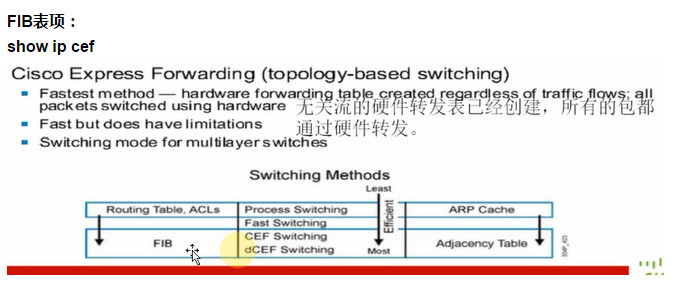
CEF转发(Cisco Express Fowarding):
思科快速转发技术,生成FIB表项,不需要CPU处理的,现在思科设备默认起的都是CEF转发:现在用的都是CEF转发,思科私有
在本地开启了CEF以后,会在本地接口板生成一张FIB表项,实际上是一个路由表的映射,在FIB表里面对路由条目进行了一个排序,同时关联了一个邻接表Adjacency Table。FIB表是工作在转发层面,而不是控制层面:分布式设备转发层面和控制层面分开的,FIB表在每一块接口板上都会存在,一个包接收以后,只会查当前接收板的FIB表项,通过FIB表项直接转发,而不会上传到CPU。
控制层面和转发层面分离开来,通过查一张表实现转发和二层封装
FIB表项:
show ip cef
框式设备:接口板都是独立的;0口插槽,1口插槽
GE 0/0/0/1这样的4位常见在框式设备
第一个0:单板槽位号
第二个0:子卡槽位号
第三个0:子卡上面插两个模块,模块的编号
第4个1:这块子卡模块上面的第一个接口
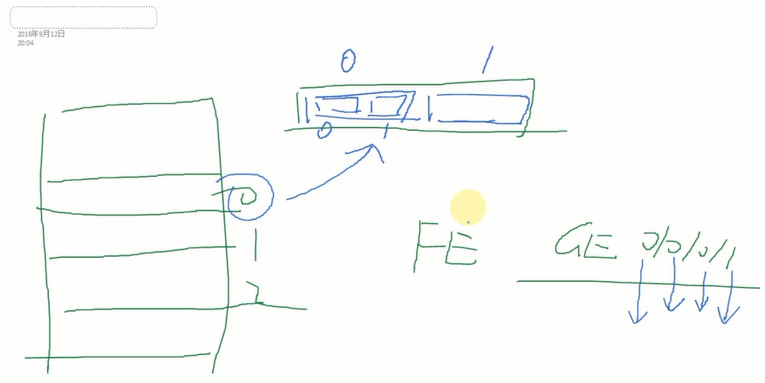
网板:在不同槽位上插不同接口板,0号板进来,1号板出去,叫做板间通讯,这时需要一块网板来支持
思科的45/65/72设备可以插路由板,交换板,防火墙的单板,只要设备支持就行
Netflow:运营商去分析哪些应用占了多少流量
CEF转发方式:
show ip cef 22.1.1.1 internal
通过这个命令行可以看到到达目的地和出接口是谁
show ip cef exact-route 12.1.1.1 2.2.2.2
可以看到出接口和下一跳
根据目标地址做哈希的,选择不同出接口
ip load-sharing ? \更改CEF的负载方式,默认是per-destination方式
per-destination 租包的
per-packet 租流的
show cef interface fast 0/0 \查看接口CEF负载方式
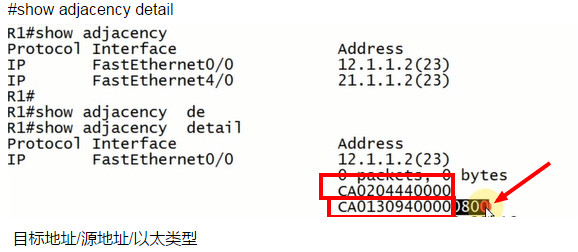
#show adjacency \看一个邻接表
#show adjacency detail
目标地址/源地址/以太类型
【实验验证】进程交换过程
实验结论:
1.CEF转发中,traceroute是租包的:有多个接口到达下一跳的话,每一个接口都会发送一个包;ping是租流的,走上面那条链路,另一条链路上的包个数基本不变
2.no ip cef ,进程转发中,若存在多个出接口,是租包的;会从接口上一个一个走
3.租流:根据源目的地址哈希来判断是不是一个流的;租包:每条链路传送一个包
*************************************************************************
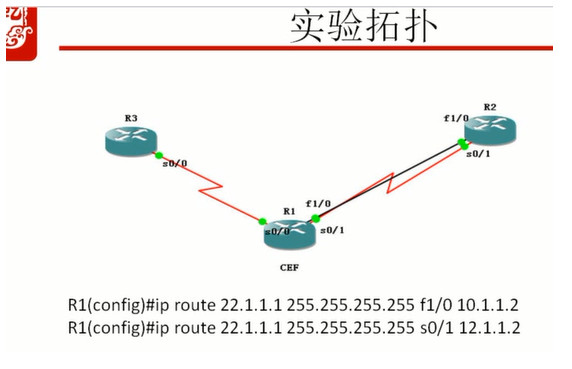
静态路由的负载:
负载分担:到达目的端有多个下一跳,下一跳转发的数据多少是不一样的
负载均衡:同样有多个下一跳,每条链路转发的数据的量是一样的
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">