1.基本数据结构
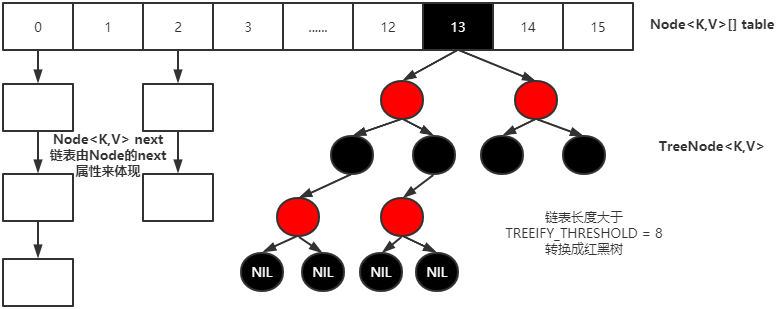
1. JDK1.7 数组 + 链表
2. JDK1.8 数组 + (链表 | 红黑树)
2.树化与退化
1.树化意义
1.红黑树用来避免Dos攻击,防止链表过长时性能下降,树化应该是偶然情况,是保底策略.
2.hash 表的查找,更新的时间复杂度是 O(1),而红黑树的查找,更新的时间复杂度是 O(log2n ),TreeNode 占用空间也比普通 Node 的大,如非必要,尽量还是使用链表
3.hash 值如果足够随机,则在 hash 表内按泊松分布,在负载因子 0.75 的情况下,长度超过 8 的链表出现概率是 0.00000006,树化阈值选择 8 就是为了让树化几率足够小
2.树化规则
1.当链表长度超过树化阈值8时,先尝试扩容来减少链表长度,如果数组容量已经 >= 64,才会进行树化.
3.退化规则
1. 情况1:在扩容时如果拆分树时,树元素 <= 6 则会退化链表
2. 情况2:在 remove 树节点时若 root 根节点,根节点的左右子节点或者孙节点只要有一个为 null 也会退化为链表.
3.索引计算
1.索引计算方法
1.首先,计算对象的hashCode()
2.再进行调用HashMap的hash()方法进行二次哈希 (二次哈希是为了综合高位数据,让哈希分布更为均匀)
3.最后 哈希结果 & (数组容量 - 1) 得到索引位置
2.数组容量为何是2的 n 次幂
1.计算索引时,如果是2的n次幂可以使用位于运算替代取模,效率更高.
2.扩容时 hash & 旧容量 == 0的元素留在原来位置,否则新位置 = 旧位置 + 旧容量
3.上述都是为了配合容量为2的 n 次幂时的优化手段,例如 HashTable的容量就不是2的 n 次幂,并不能说哪种设计更好.
4. put 与 扩容
1. put 流程
1.HashMap 是懒惰创建数组的,首次使用才创建数组
2.计算索引(桶下标)
3.如果桶下标还没人占用,创建 Node 占位返回
4.如果桶下标已经有人占用
1.已经是 TreeNode 走红黑树的添加或更新逻辑
2.是普通 Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值,走树化逻辑
5.返回前检查容量是否超过阈值,一旦超过进行扩容
2. 1.7 与 1.8 的区别
1. 表插入节点时,1.7是头插法,1.8是尾插法
2. 1.7是大于等于阈值且没有空位时才扩容,而1.8是大于阈值就扩容
3. 1.8在扩容计算Node索引时会优化
3. 扩容加载因子 (factor) 为何默认是0.75f
1. 在空间占用和查询时间之间取得比较好的权衡
2. 大于这个值,空间节省了,但是链表就会比较长,影响性能
3. 小于这个值,冲突减少了,但是扩容更频繁,空间占用更多
5.并发问题
1.扩容死链 (1.7会存在)
1.7 源码如下:
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } } }
-
-
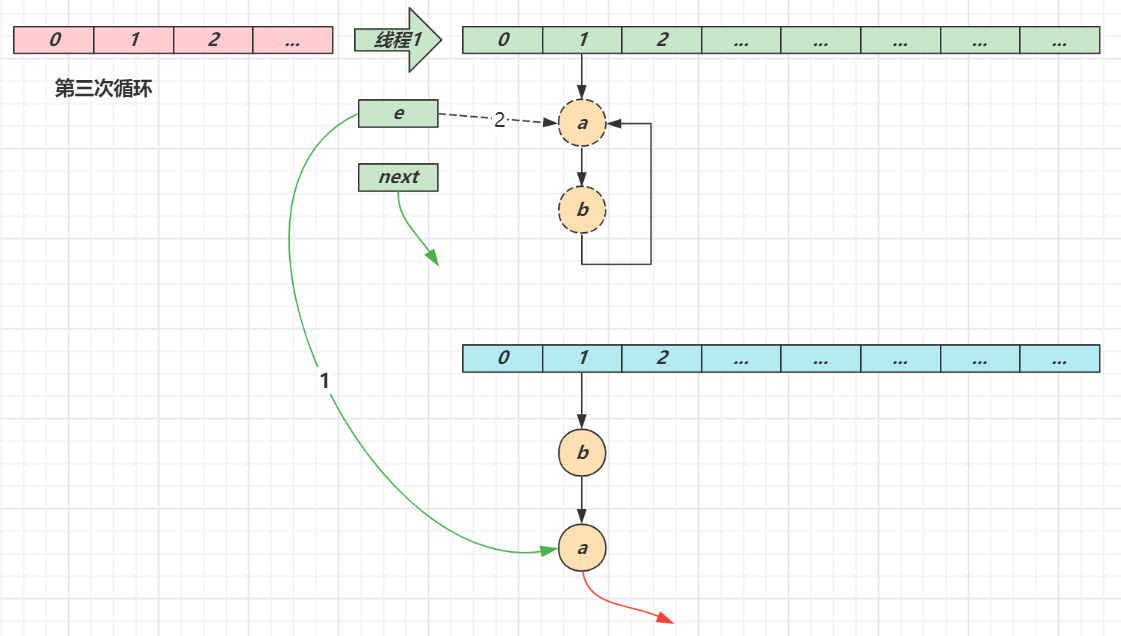
线程1(绿色)的临时变量 e 和 next 刚引用了这俩节点,还未来得及移动节点,发生了线程切换,由线程2(蓝色)完成扩容和迁移
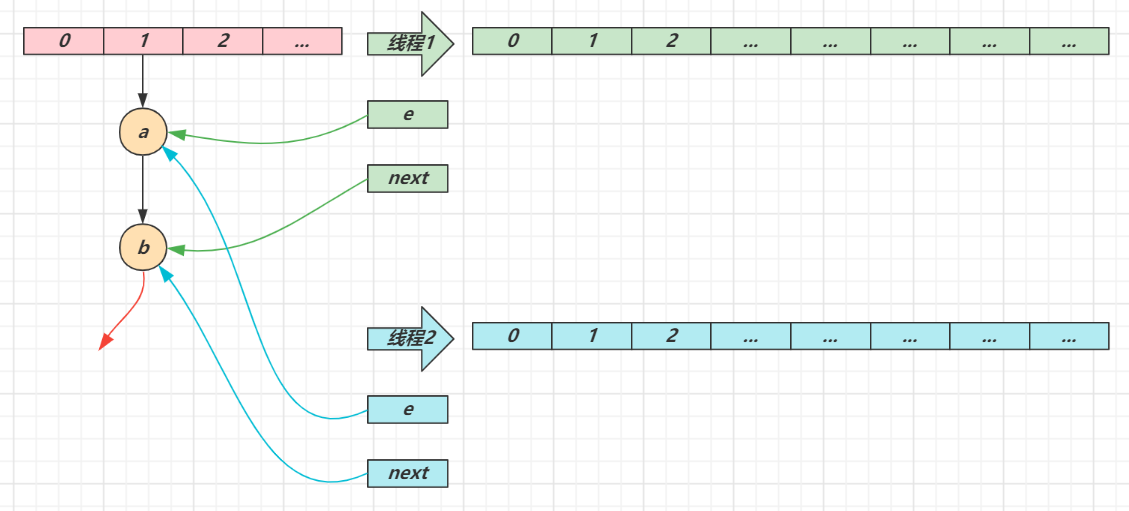
线程2 扩容完成,由于头插法,链表顺序颠倒。但线程1 的临时变量 e 和 next 还引用了这俩节点,还要再来一遍迁移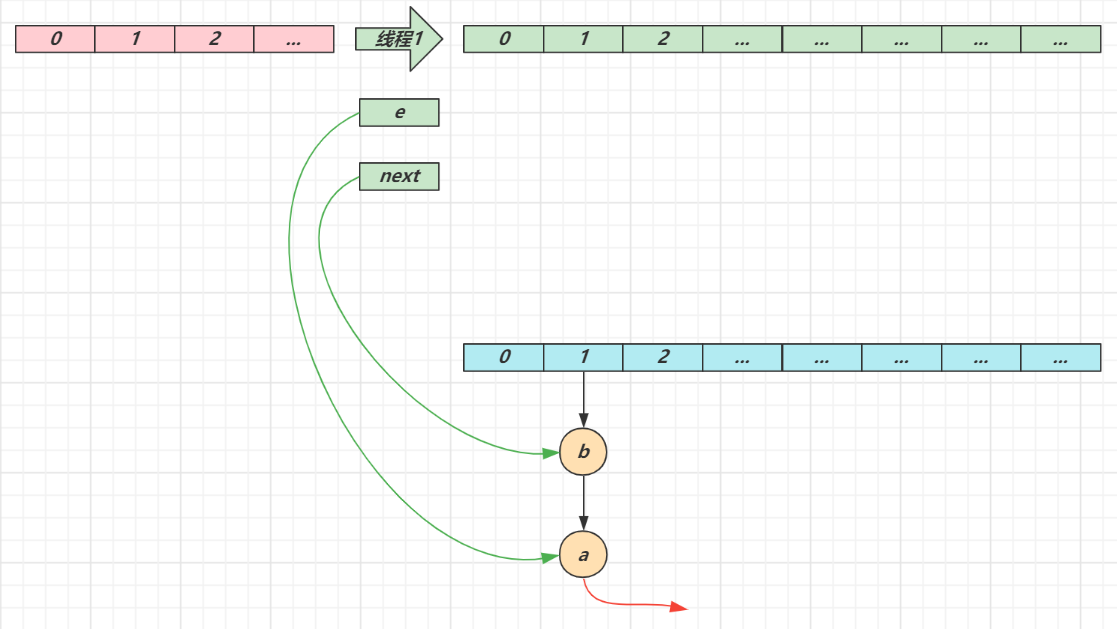
-
循环接着线程切换前运行,注意此时 e 指向的是节点 a,next 指向的是节点 b
-
e 头插 a 节点,注意图中画了两份 a 节点,但事实上只有一个(为了不让箭头特别乱画了两份)
-

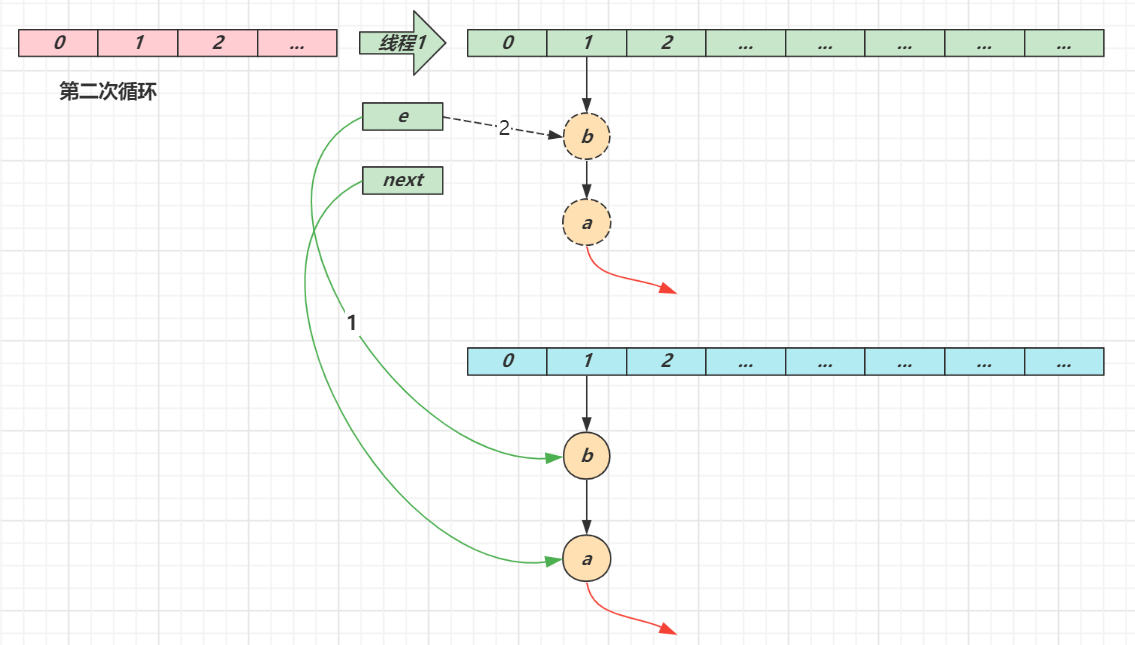
第二次循环
-
next 指向了节点 a
-
e 头插节点 b
-
当循环结束时,e 指向 next 也就是节点 a
-
-
next 指向了 null
-
e 头插节点 a,a 的 next 指向了 b(之前 a.next 一直是 null),b 的 next 指向 a,死链已成
-
-