背景:昨晚11点40几分,终于各个集群组件都启动成功了,然后心满意足的去睡觉了,但是今早再起来再去启动的时候就出现了namenode的问题,然后就开始了查找原因的艰辛历程。
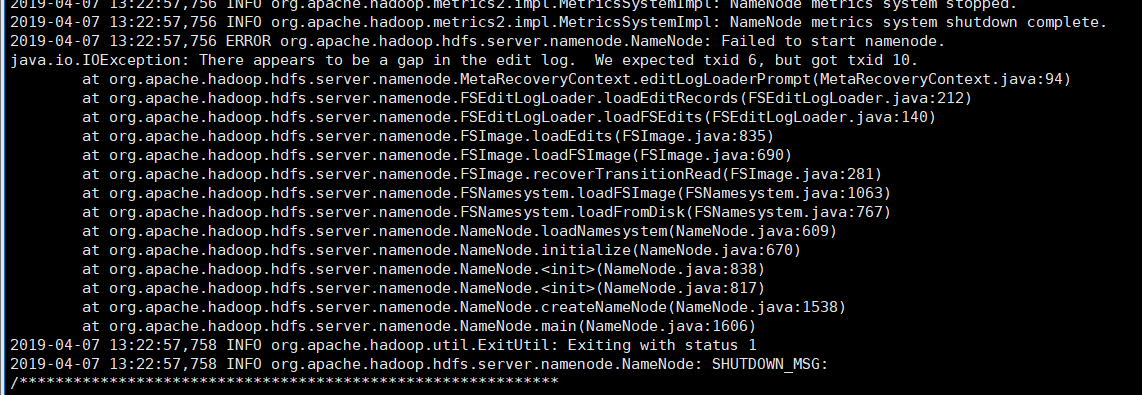
查看报错的log日志:
2019-04-07 13:22:57,746 WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Encountered exception loading fsimage
java.io.IOException: There appears to be a gap in the edit log. We expected txid 6, but got txid 10.
at org.apache.hadoop.hdfs.server.namenode.MetaRecoveryContext.editLogLoaderPrompt(MetaRecoveryContext.java:94)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.loadEditRecords(FSEditLogLoader.java:212)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.loadFSEdits(FSEditLogLoader.java:140)
at org.apache.hadoop.hdfs.server.namenode.FSImage.loadEdits(FSImage.java:835)
at org.apache.hadoop.hdfs.server.namenode.FSImage.loadFSImage(FSImage.java:690)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:281)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1063)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:767)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:609)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:670)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:838)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:817)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1538)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1606)
我把问题复制去网上搜,大多都是让修复:
原因:namenode元数据被破坏,需要修复
解决:恢复一下namenode
hadoop namenode -recover
我是第一次搭建集群所以没有数据丢失的风险,所以就执行了但是,在修复中还是报错了。
最终找到以下这篇文章,解决了我的问题非常感谢:以下是摘抄了几个重点
解决方法:这里基本上看不懂,跳过吧
namenode在启动的过程中,最重要的一个动作就是拼凑集群的元数据,有哪些文件和目录,分别存放在哪里等信息。这个重要的过程分两步:
(1) 读取fsimage和edits数据,拼凑出元数据。注意,这里的元数据是指,有哪些目录和文件,每个文件有多大这样的信息。
(2) 获取每个datanode的汇报信息,整合出完整的blockMap。这里就还包括文件和实际存储的映射关系,一个文件具体存放在那个节点。
以下是对日志的分析
查看日志中的报错信息,可以明显地看到,这个问题是发生在FSEditLogLoader.loadFSEdits这个方法中,也就是在获取edits文件时报错。这里要注意的一点是,在配置有ha的hadoop2.0集群中,namenode启动时的fsimage是直接从本地获取,而edits是从journalnode上获取的。 所以 “There appears to be a gap in the edit log. We expected txid 6, but got txid 10.. ” 这个问题肯定是发生在journalnode上,而不是namenode上的。(读懂这里基本上就知道原理,读不懂也没关系,继续往下看),英文的意思是日志有空白,我们期望得到txid为6,得到的确是10 。
网上有一种解决方法,说是把active namenode上的name文件夹拷贝到standby namenode上。我试了,而且拷贝过来的name目录中也有176531929这条Edits数据,但启动namenode时还是报同样的错,说找不到176531929这条edit数据。说明这个方法不可行! 因为Edits是要在启动时去journalnode上读取的。这个问题的根本原因是你的journalnode上存在Edits数据丢失的情况。这一句看懂就基本上找到原因了,也有方向了,在HA的解读中就有说明,
所以我去查看我的journalnode目录,果然发现journalnode/yarncluster/current下面没有176531929这一条Edits数据。所以,这就是这个错误出现的根本原因。然后解决办法很简单,从active namenode上拷贝这条Edits数据到所有journalnode中。重新启动,问题解决,没有数据丢失,也不需要recovery。
以上的蓝色字体都是摘抄别人博客,黑色和红色是自己的标记和理解。
我根据我自身的错误“我们期望得到txid为6,得到的确是10 。”本人在查看edit的时候并没有看见txid是6或者10 的情况,最后就抱着试一试的态度
把/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/jn/ruozeclusterg6/current中的所有的edit*的文件都删除,然后去active的nn的
/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/name/current目录下的所有的edit*文件复制到/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/dfs/jn/ruozeclusterg6/current中,重启成功啦!!!!,因为我jps的时候看见了namenode,但是当我第二次查看的时候,namenode竟然消失了,kao!!!好想哭!!!!!!
接着我又尝试恢复原数据的解决方式,第一次尝试因为中途出现了选项,我不知道改选什么,所以失败了,我又找到一篇文章,里边的信息是这样的
解决方法:恢复一下namenode
cd $HADOOP_HOME/bin
hadoop namenode -recover
一路选择c 进行元数据的恢复.这是重点
重新启动。到这里问题真正的结束了,好舒服。
参考博客:https://blog.csdn.net/amber_amber/article/details/46896719