【为什么要了解hive执行流程】
- .当我们写了一个sql,但是执行起来很慢,这时如果我们知道这个sql的底层执行流程是怎样的,就会比较容易去优化
- .如果我们在面试中被问及对hive的理解,如果说就是写sql会显得很片面,如果我们了解hive的执行流程,就会知道,虽然表面上是写sql,但是在从hive的sql,到最终出来执行结果,中间经历了MR流程,其中MR的map,combiner,shuffle,reduce具体是执行了hive的那个部分,这样就会比较全面。
【分析基于hadoop之上的SQL执行流程】
-
基本SQL框架
【例表:traffic_info】
| NAME | ID | TRAFFIC |
| YY | 1001 | 204 |
【例表:TV_info】
| ID | BOSS |
| 1001 | 若老 |
- select name,count(1) from traffic_info group by name;
- select a.name,a.id,a.traffic,b.boss from traffic_info a join TV_info b on a.id=b.id
- 解析:这两个简单的sql基本上涵盖了所有的大数据sql的框架,也就是说无论多磨复杂的大数据sql最终都会落到这两个简单的sql框架上,基本上不会有第三种,之所以我们会觉得sql千变万化,非常复杂,基本上都是业务的复杂度的原因
【图解sql执行流程】
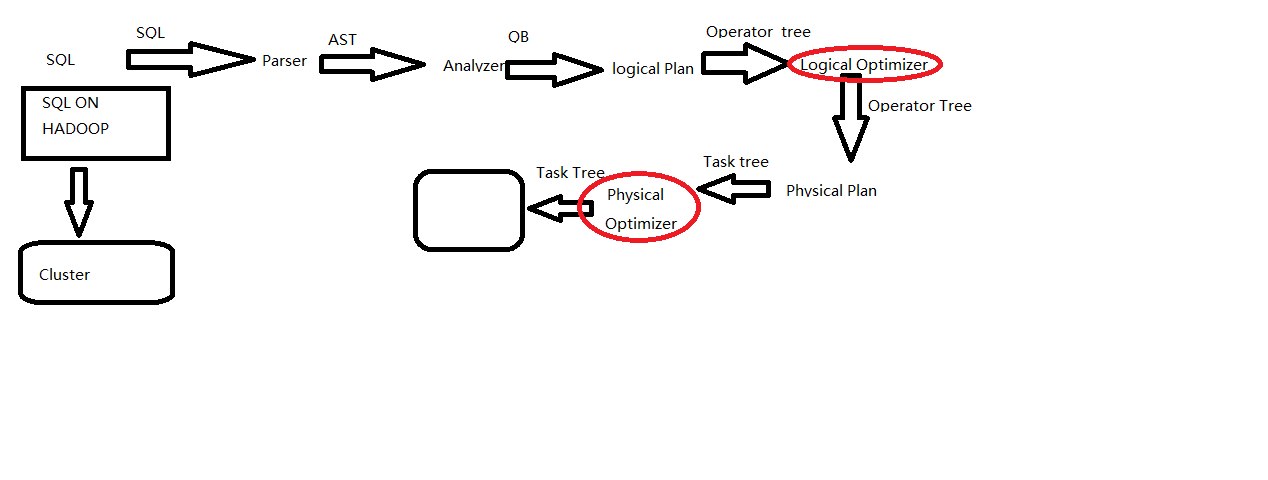
- sql写出来以后只是一些字符串的拼接,所以要经过一系列的解析处理,才能最终变成集群上的执行的作业
- Parser:将sql解析为AST(抽象语法树),会进行语法校验,AST本质还是字符串
- Analyzer:语法解析,生成QB(query block)
- Logicl Plan:逻辑执行计划解析,生成一堆Opertator Tree
- Logical optimizer:进行逻辑执行计划优化,生成一堆优化后的Opertator Tree
- Phsical plan:物理执行计划解析,生成tasktree
- Phsical Optimizer:进行物理执行计划优化,生成优化后的tasktree,该任务即是集群上的执行的作业
- 结论:经过以上的六步,普通的字符串sql被解析映射成了集群上的执行任务,最重要的两步是 逻辑执行计划优化和物理执行计划优化(图中红线圈画)
【SQL与MR流程之间的关系】
- 1.过滤类SQL与MR的关系
- 执行sql:select a.id,a,city, a.cate form access a where a.day=’20190414’ and a.cate= ‘大奔’

- 结论:过滤类的sql相当于ETL的数据清洗过程,并没有reduce过程,分区的过滤在读取数据的时候就已经进行了。map的个数是由分片数决定的。
- 聚合分组类SQL与MR的关系
- select city, count(1) form access a where a.day=’20190414’ and a.cate= ‘奔驰’ group by city
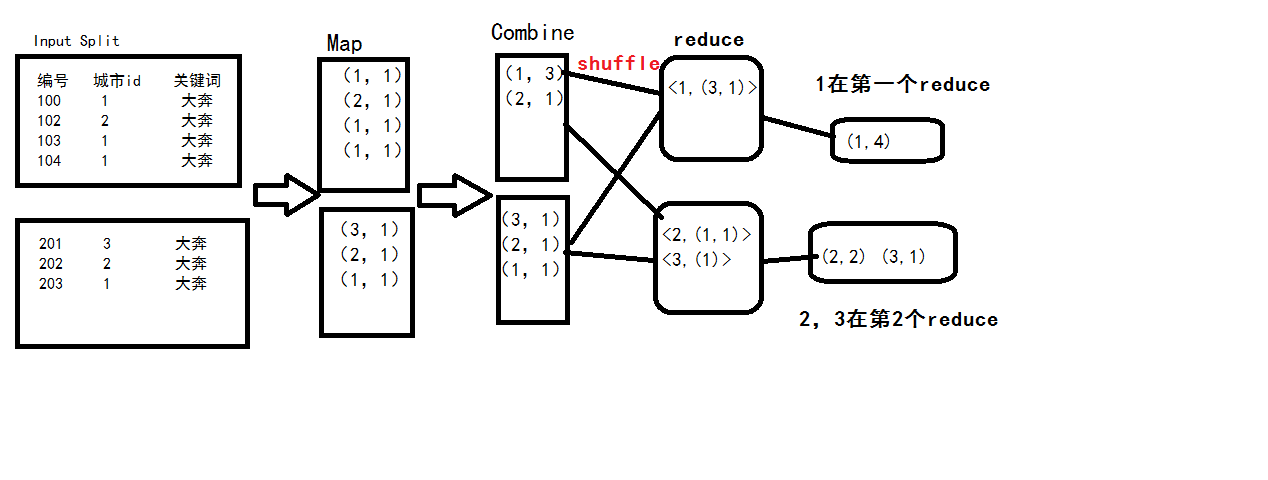 结论:
结论:
- .其实这个过成和WC是非常相似的,在各自的分片中,都是把数据分割以后每个值都对应一个1得到<key,1>,再经过本地reduce(combine过程)把key一样的value=1相加,得到新的<key,values>,再经过shuffle过程,把所有分片中的<key,values>,key一致的values相加,又得到最终的<key,values>。
- combiner其实是一个本地的reduce主要就是为了减轻reduce的负担,但并不是所有的场景都会发生combiner,例如求平均数。
【知识扩展】
- 扩展1:reducebykey和groupbykey的区别,前者会发生combiner 局部聚合,而后者不会,前者获得的是相同key对应的一个元素,后者是获取元素集合。reducebykey更加适合大数据,少用groupbykey(全数据shuffle)
- 扩展2:map task数是由数据文件分片数决定的分片数即是map任务数,程序员只能给个期望值
- 扩展3:reduce task数是由输入reduce的数据的分区(partitions)数决定的即分区数为map任务数,默认是1,程序员可直接设置reduce个数来改变reduce task数,reduce task数决定来 生成的文件数。
- 扩展4: MR数据shuffle确定数据发往哪一个reduce分区的规则是:取key的hashcode值对分区数模。
- 扩展5:explain sql ;查看某sql语句的执行计划
【知识拓展来自以下博客】
作者:qq_32641659
来源:CSDN
原文:https://blog.csdn.net/qq_32641659/article/details/89421655
版权声明:本文为博主原创文章,转载请附上博文链接!
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain