一、首先配置ssh无秘钥登陆,
先使用这条命令:ssh-keygen,然后敲三下回车;
然后使用cd .ssh进入 .ssh这个隐藏文件夹;
再创建一个文件夹authorized_keys,使用命令touch authorized_keys;
然后使用cat id_rsa.pub > authorized_keys 即可;
最后使用 chmod 600 authorized_keys修改权限就完成了。
二、创建spark项目
idea创建spark项目的过程这里就略过了,具体可以看这里https://www.cnblogs.com/xxbbtt/p/8143441.html
三、在pom.xml加入相关的依赖包
在pom.xml文件中添加:
<properties> <spark.version>2.1.0</spark.version> <scala.version>2.11</scala.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.19</version> <configuration> <skip>true</skip> </configuration> </plugin> </plugins> </build>
然后等待就好了。。。
四、编写一个示范程序
创建一个scala类,并写以下代码,也可以是其他的,这里只是测试而已
object first { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("wordcount") val sc = new SparkContext(conf) val input = sc.textFile("/home/cjj/testfile/helloSpark.txt") val lines = input.flatMap(line => line.split(" ")) val count = lines.map(word => (word, 1)).reduceByKey { case (x, y) => x + y } val output = count.saveAsTextFile("/home/cjj/testfile/helloSparkRes") } }
这里使用了Spark实现的功能是,计算helloSpark.txt这个文件各个单词出现的次数,并保存在helloSparkRes文件夹中。
五、打包
file->Porject Structure->Artifacts->绿色的加号->JAR->from modules...
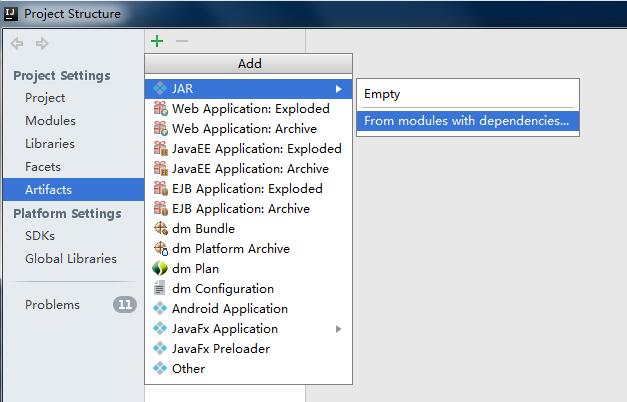
跳出以下对话框,选择要打包的类,然后选择copy to.....选项,这里的意思是只打包这一个类。
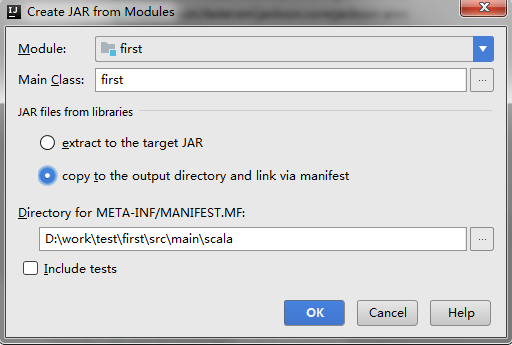
然后点击ok,然后ok。然后build->build Artifacts
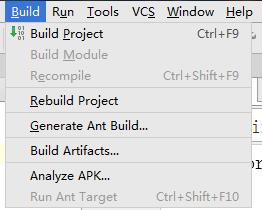
再然后点击build
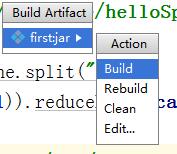
等待build完成。然后可以在项目的这个目录中找到刚刚打包的这个jar包
这里的first的我的项目名。
六、启动集群
先将刚才打包的jar包复制到虚拟机中,
helloSpark.txt是我将要操作的文件。接着就是启动集群,分为三步
- 启动master ./sbin/start-master.sh
- 启动worker ./bin/spark-class
- 提交作业 ./bin/spark-submit
首先进入spark-2.2.1-bin-hadoop2.7文件夹,然后运行命令./sbin/start-master.sh
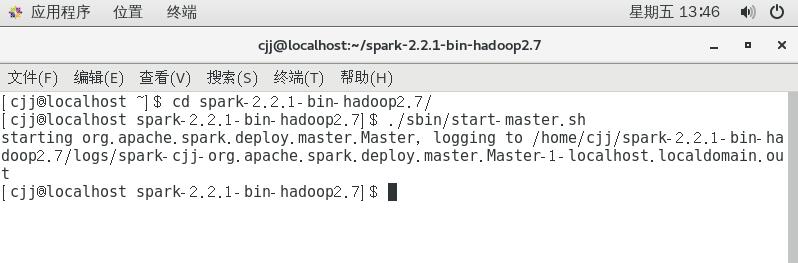
然后可以打开浏览器,进入localhost:8080,可以看到
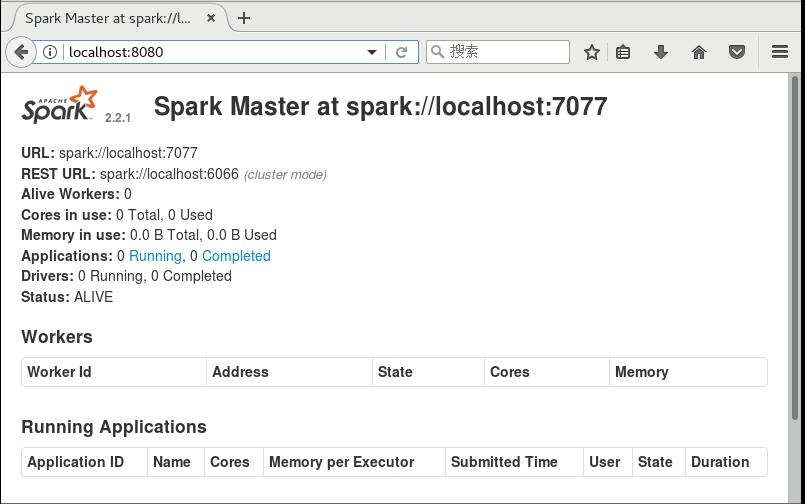
这里的URL spark://localhost:7077需要记下来下一步需要使用,下一步启动work,加上刚刚的URL,可以使用的命令是,
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
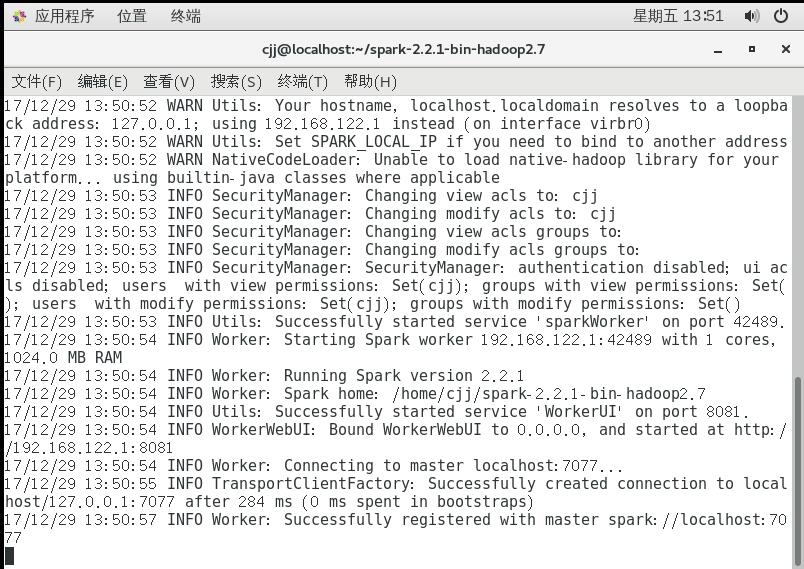
这时启动另一个窗口进行提交作业,同样需要先进入spark文件夹,然后运行命令
./bin/spark-submit --master spark://localhost:7077 --class first /home/cjj/testfile/first.jar
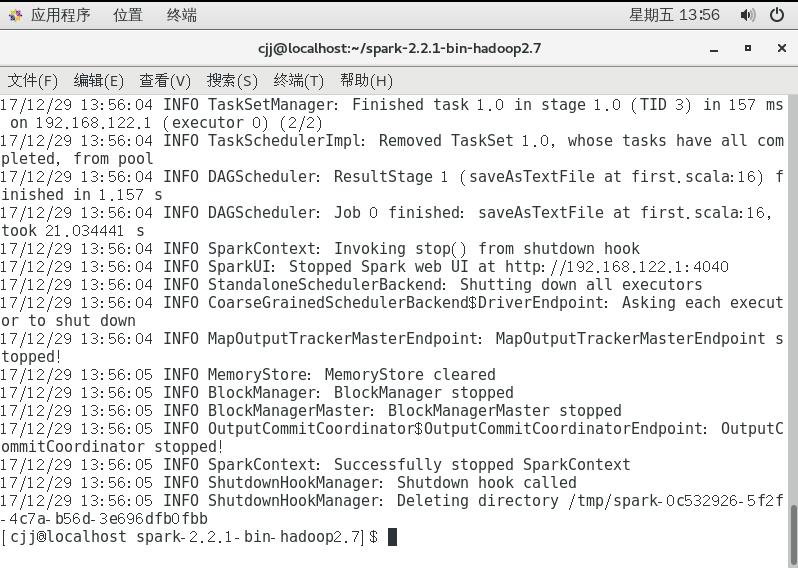
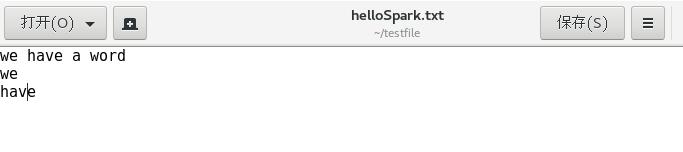
这样就算完成了,我们可以来看看结果,看结果之前需要先看一看helloSpark.txt的内容
结果保存在helloSparkRes中,下面是结果
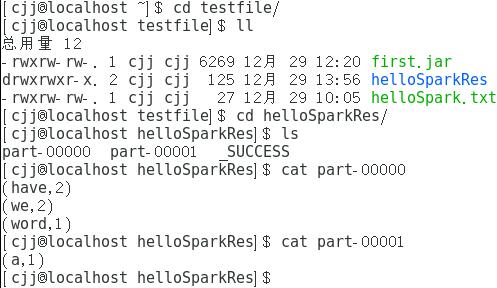
这里的结果告诉我们have和word的个数为2,word和a的个数为1。