Ensemble
1、什么是集成学习
2、Bagging(决策树+随机森林)
3、Boosting
Adaboost、Gradient boost
4、Stacking
1、什么是集成学习
人多力量大!
- 世上没有一个分类器解决不了的分类问题
- 如果有,就多用几个!

集成学习分为两大类:Bagging和boosting
- Bagging(“人海战术”):很多个水平差不多的人做理综题。无顺序,适用于模型复杂容易过拟合的分类器(通过对数据重采样方式)
- Boosting(“逐个击破”):很多个偏科但有专长的人做理综题。有顺序(迭代),适用于模型简单的分类器(通过对数据更新权值方式)
2、Bagging(决策树+随机森林)
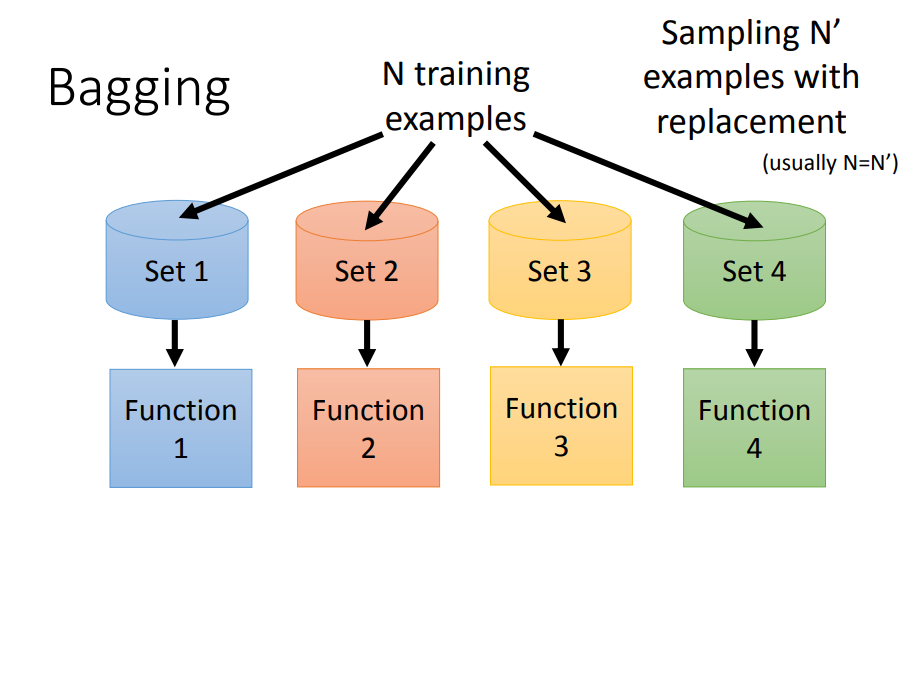
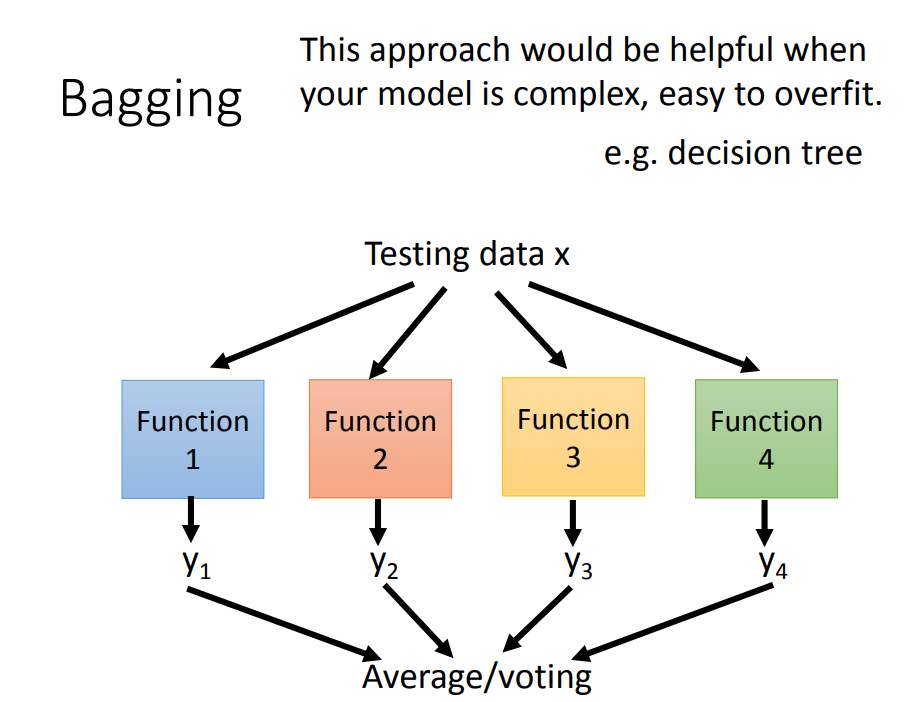
思想:在原始数据集上通过有放回抽样重新选出N个新数据集来训练分类器,将多个分类器的结果进行average(回归)或voting(分类)。
- 可以解决复杂模型(比如决策树)带来的过拟合问题,代表算法是随机森林
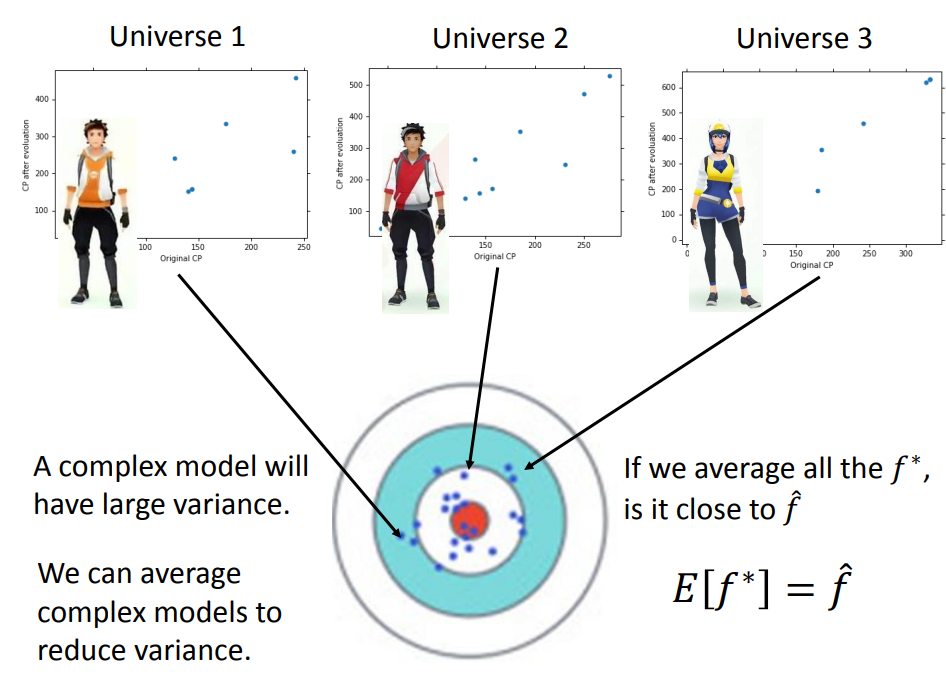
- 我们自己创造出不同的dataset,再用不同的dataset去训练一个复杂的模型,每个模型独自拿出来虽然方差很大,但是把不同的方差的模型集合起来,整个的方差就不会那么大,而且偏差也会很小。
决策树(decision tree):是一种基本的分类与回归方法,在分类中相比LR模型更复杂,所以更容易造成过拟合
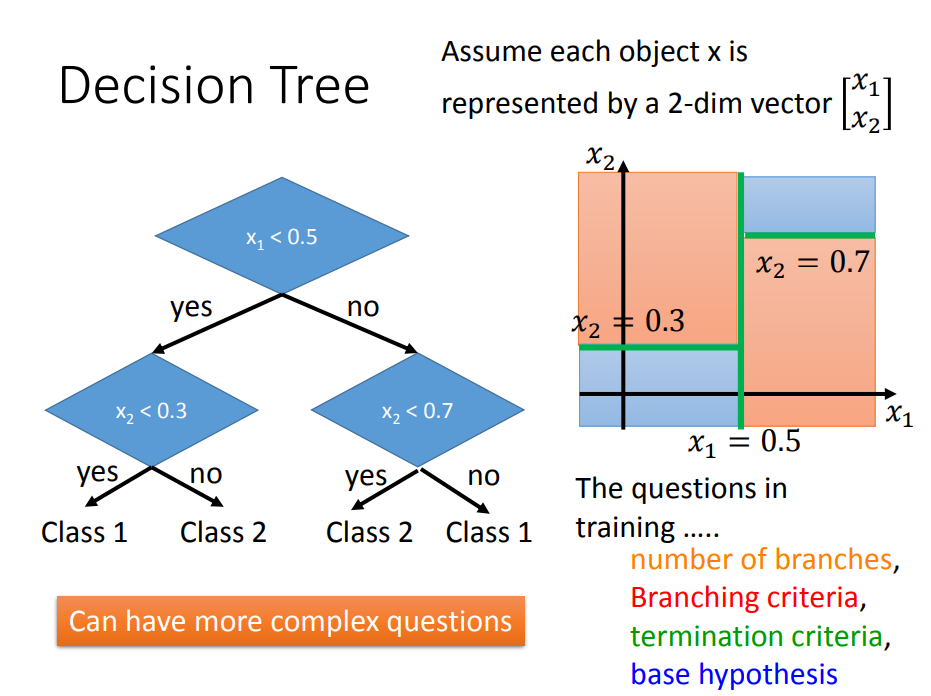

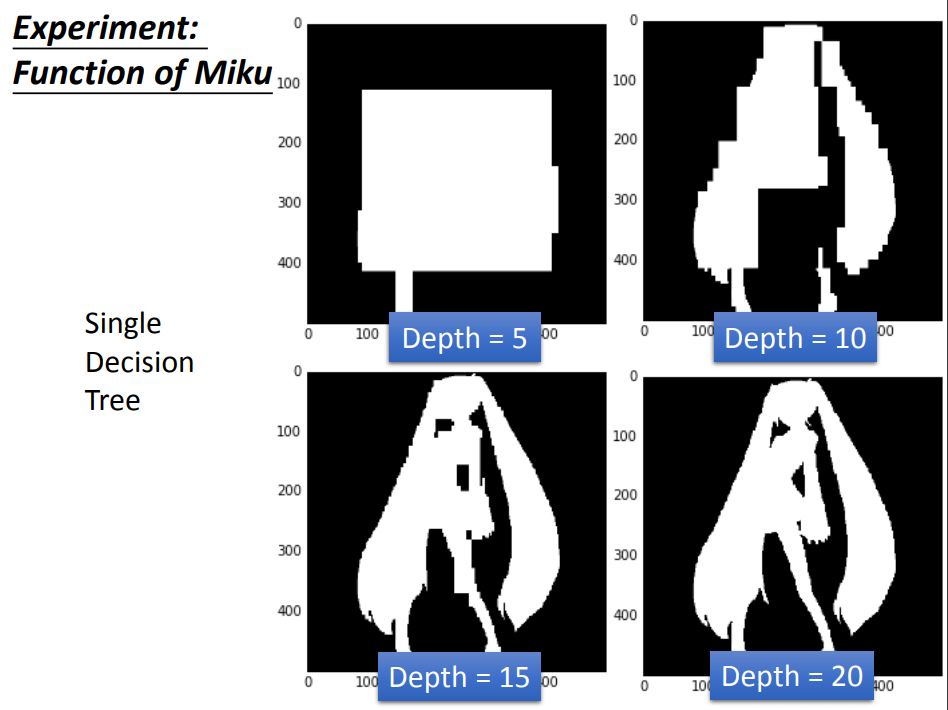
随机森林:决策树在bagging方法下的应用
- 传统的随机森林是通过之前的重采样的方法做,但是得到的结果是每棵树都差不多(效果并不好)
- 限制一些特征或者问题不能用,这样就能保证就算用同样的dataset,每次产生的决策树也会是不一样的,最后把所有的决策树的结果都集合起来,就会得到随机森林
- out-of-bag方法可以做验证
- 随机森林主要是解决过拟合问题


3、Boosting(Adaboost、Gradient boost)
- 同样是根据“集成学习”思想提出的算法,Boosting的核心原理与Bagging一样,对原始样本抽样来训练多个分类器,综合得到效果强大的最终模型
- 与Bagging不同的是,Boosting在每次抽取样本之前会对每一条观测数据赋予相应的权重,再根据带有权重的样本训练出新模型(AdaBoost)。通过这种方法来优化每一轮迭代所产生的基分类器。
- 如同每次模拟考试之后老师往往会给予成绩不理想的学生更多的关注一样


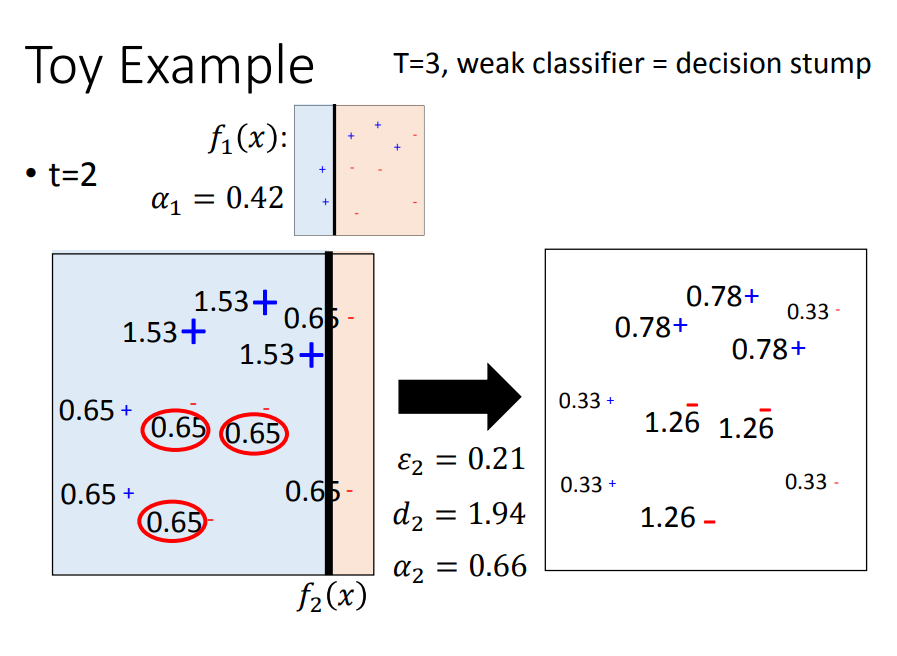
Adaboost(自动更新样本权值,再根据带有权值的新样本更新function)
- 思想:一、先训练好一个分类器F1,二、找一组新的training data,让F1在这组data上表现很差,三、用这组新的data训练处F2
- 那么,如何找到这组能让F1表现很差的data呢?那就要引出错误率,如果大于等于0.5,那就“烂掉”


- U2权值是如何更新的呢(具体流程)
- 思路:证明d1>1(略)。



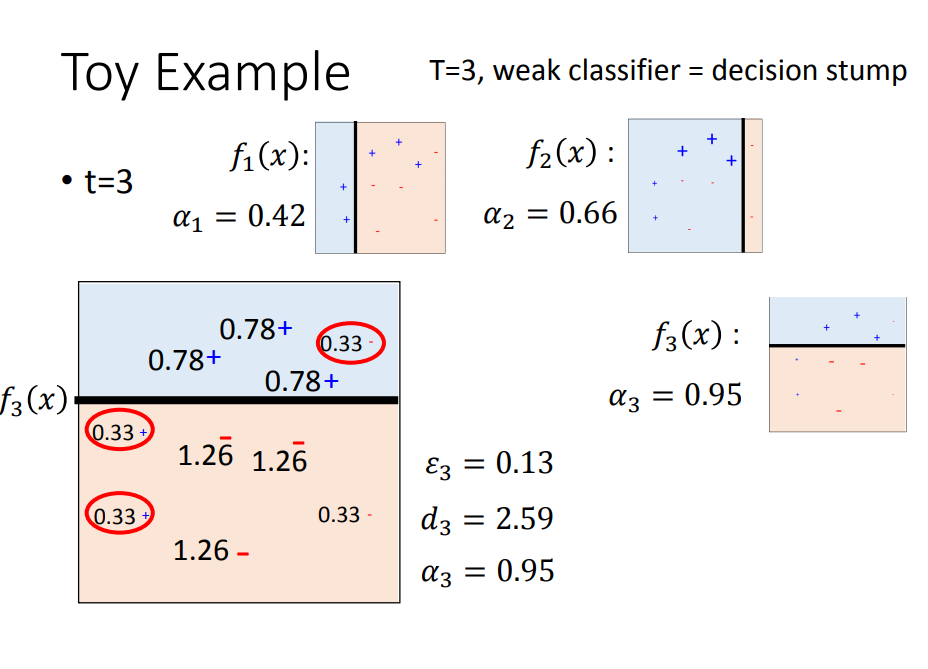
AdaBoost总结:
- 为了用一个式子去表达两种情况,我们把dt变为at
- 我们更新完得到很多的f,要把所有的f累加然后看正负号判断是Class1还是Class2


用一个简单的例子演示效果:

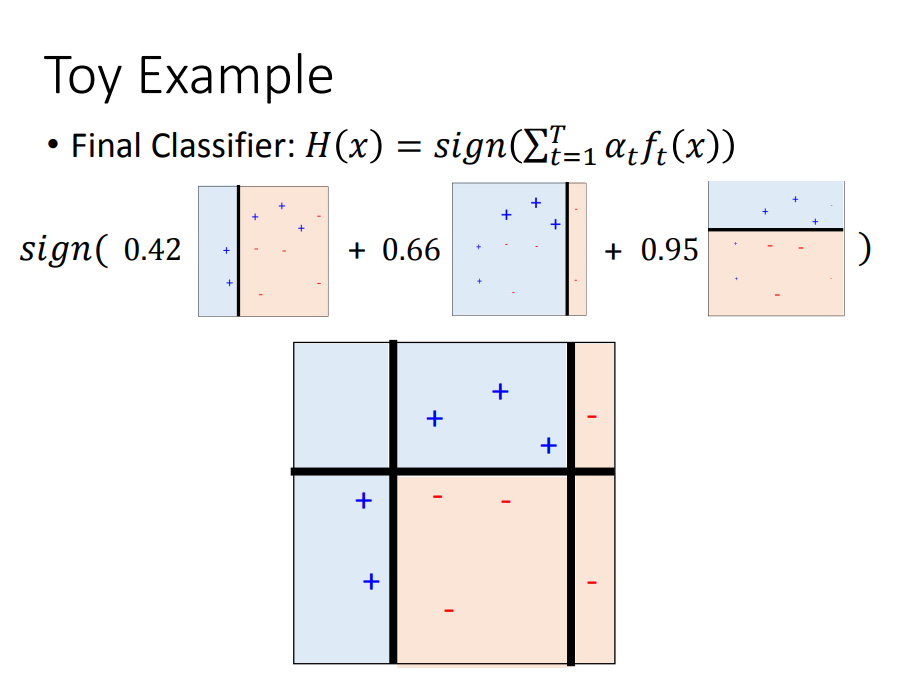
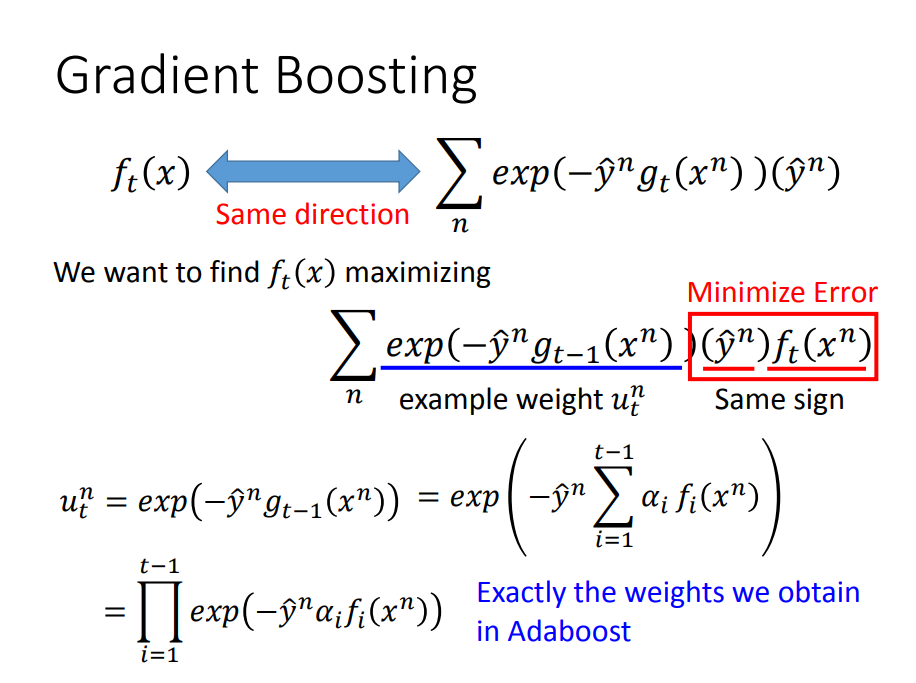
Gradient boost(并不是更新样本的权值,而是直接更新function的权值)
- Gradient boost是一种更为一般的boost的方法
- L(g)的形式表明,希望g(x)与y^同号,这样相乘就越大,L就越小
- GradientBoost其实可以想象成在做梯度下降,只是这个梯度是一个函数
f(x)与a是怎么来的


Gradient boost具体步骤:
- 一、f(x)是怎么来的——训练数据,是下面式子最大化
- 二、a是怎么来的——固定住f(x),最小化L(g),就得到了a,会发现此时的a与Adaboost里面的是一样的
- 三、g(x)根据f与a就求得了
- 总结:Gradient Boost的优点是可以任意更改目标函数(f(x)),这样就可以创造出很多新的方法。