1,BTREE是多叉树,多路径搜索树。有N棵子树的节点它包含N-1个关键字,例如,有3个子树的非叶子节点,那么就有2个关键字,每个关键字不保存数据,只用来存储索引(在索引存储数据时,将索引指向关键字的值也存储进来。最终实现key = &get; value结构)。所有的数据最终都要落在叶子节点,所有的叶子节点包括关键字信息以及指向这些关键字的指针,而且叶子节点是根据关键字大小、顺序链接的。所有的叶子节点都必须有个链表指针把数据串起来。所以,所有非叶子节点可以看成索引部分,包括子树中最大值或最小值关键字等信息。在btree索引下,获取数据时只需要从索引树的最小节点,一直不断的向右进行遍历就可以快速的得到想要的数据(这种遍历有指针把数据串起来),不需要回溯到根节点, 这样就可以理解为什么innodb的主键索引不能用离散的数据。
下图为2层btree结构:

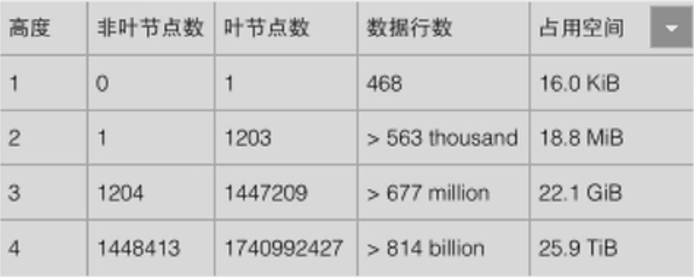
btree数据量分布情况:
2,哈希索引建立在哈希表的基础上,它对每个值采用精确查找。每一行都需要先计算哈希码,比较好的哈希算法算出比较低的重复的度,这样效率相对高一些。如果算出来的值是一样的,那么它需要再进行判断哪个值才是想要的值,所以说在表里面采用哈希索引,但是重复度又比较高,那么哈希索引效率就比较低,可以使用select crc32('xxx');计算出哈希码,利用这个哈希值指向具体的数据位置。
HASH索引PK BTREE索引:大量不同数据等值精确查询,HASH索引效率通常比BTREE高;HASH索引不支持联合索引的最左匹配规则(where a =? and b=? ,index(a,b,c)这样无法同时使用a,b,c,相当于是范围查询);HASH索引不支持排序;HASH索引不支持模糊查找;
下图为哈希索引:

3,聚集索引,其实就是索引的组织方式,整个表存储的逻辑顺序根聚集索引的顺序是一致的,也就是说聚集索引决定了整个表的物理的存储的逻辑顺序。mysql一个表只支持一个聚集索引。在innodb里面聚集索引就是整个表,表就是聚集索引,因为innodb的聚集索引后面是整行数据(如果主键由多列组成,btree优先按第一列顺序存储),在聚集索引btree里面每个叶子节点最终存储每行数据,这就是为什么在innodb里面没有任何条件count (*),它会优先选择普通索引来完成扫描,而不是采用主键索引,因为如果扫聚集索引,扫描的数据量更大,产生的IO更大,如果扫描普通辅助索引,那么它的数据结构通常来讲比主键索引小。另外,为了实现mvcc聚集索引还存储了rollback point和事物ID。
innodb的普通索引叶子节点里面存储着主键索引的键值。聚集索引决定了物理表的存储顺序,如果聚集索引频繁修改,可能会导致修改存储的顺序,那么这个行数据会产生位移,产生数据离散IO。如果新增的数据太过离散,也会导致聚集索引存储的位置相应的离散,也会导致随机IO.
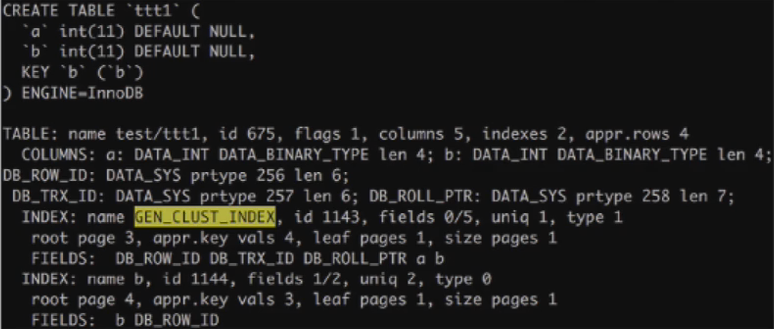
innodb的index extentions特性:mysql5.6.9版本以后,在innodb普通索引里面存储着主键键值,目的是根据普通索引扫描时能根据普通索引键值找到主键并找到对应的数据。如下图:#官方文档,https://dev.mysql.com/doc/refman/5.6/en/index-extensions.html
create table innodb_table_monitor
(id int)engine=innodb;#随便字段只要是innodb表,会把以下信息打印到日志,创建后10s左右生效。
SELECT * FROM INFORMATION_SCHEMA.INNODB_SYS_TABLESpaces WHERE NAME like '%t1%'; #5.7查看视图才可以
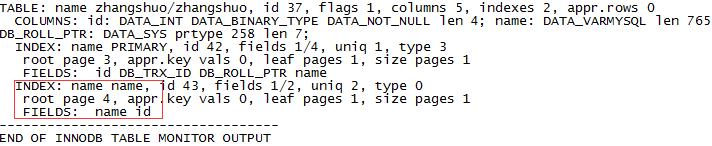
mysql> show create table zhangshuoG *************************** 1. row *************************** Table: zhangshuo Create Table: CREATE TABLE `zhangshuo` ( `id` int(11) NOT NULL DEFAULT '0', `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `name` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1 row in set (0.00 sec)
聚集索引的选择:
a,含有大量非重复值的列;
b,被连续(顺序)访问的列;
c,返回大量结果集的查询;
案例:
如果一个表很大,有1/3数据要删除,如果是随机删除,会产很多空洞,删完后产生的空洞不写入,没什么影响,但这种删除比较慢,因为需要对btree进行随机扫描。删完后索引树会进行自旋,如果它的page填充因子比较低,例如把2页合并成1页,在合并中进行写入会比较慢。 删完后可以执行alter table engine=innodb来整理碎片,但是会锁表(重建整张表)或者重新定义主键列。建议使用pt-osc来完成表空间回收。
innodb主键索引分布:
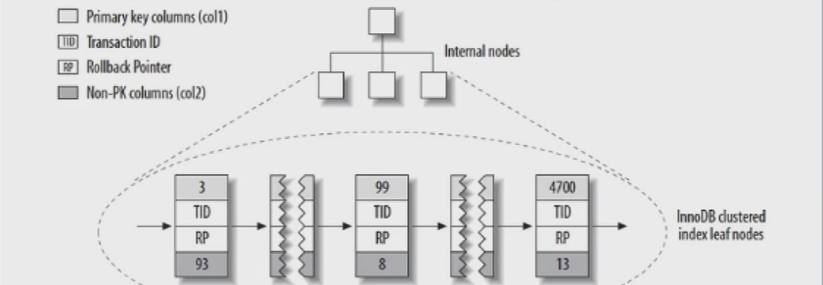
第一列:主键键值
第二列:事物ID
第三列:回滚指针
第四行:除了主键列以外其他列的值
innodb普通非唯一索引分布:
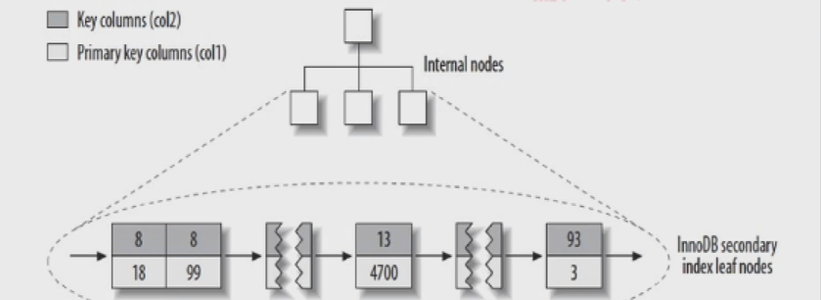
第一列是索引键值,因为是普通索引所以存在重复。
第二列是主键的列值。
innodb普通索引的key是本身列值,value对应的是主键的键值。这样做的目的是我们通过普通索引来扫描数据的时候我们可以快速的通过普通索引存储的主键的键值找到对应的记录。
innodb 主键索引特点:(这个表可以理解成6行3个列)
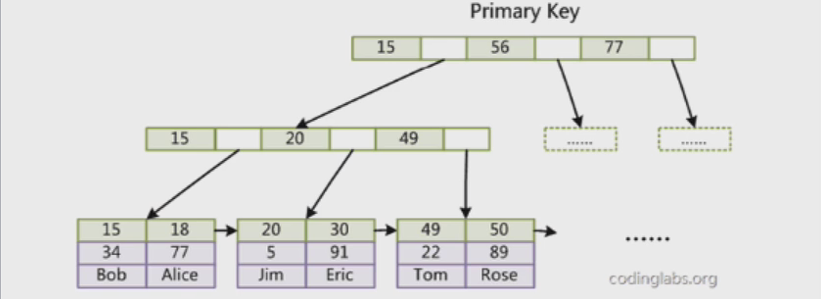
普通索引的value指向的是主键的列:

innodb聚集索引特点验证: