一、scrapy 实验 爬中国人寿新闻,保存为xml
如需转发,请注明出处:小婷儿的python https://www.cnblogs.com/xxtalhr/p/10517297.html
链接:https://pan.baidu.com/s/1HeIbBuAWjk8uNRl7ZIXh-A
提取码:z3hh
1.1 代码结构
scrapy框架具体内容,请参考
1、scrapy(一)scrapy 安装问题 https://www.cnblogs.com/xxtalhr/p/9170437.html
2、Scrapy 框架(二)数据的持久化 https://www.cnblogs.com/xxtalhr/p/9164186.html
3、scrapy (三)各部分意义及框架示意图详解 https://www.cnblogs.com/xxtalhr/p/9170343.html
4、scrapy (四)基本配置 https://www.cnblogs.com/xxtalhr/p/9169484.html
5、scrapy shell https://www.cnblogs.com/xxtalhr/p/9158651.html

1.2 书写 spiders
1 # -*- coding: utf-8 -*- 2 import scrapy 3 import json 4 5 6 class RrSpider(scrapy.Spider): 7 name = 'rr' 8 allowed_domains = ['www.chinalife.com.cn'] 9 start_urls = ['https://www.chinalife.com.cn/chinalife/xwzx/gsxw/7934bcc5-%d.html' % (i) for i in range(1, 12)] 10 11 def parse(self, response): 12 news = response.xpath('//div[@class="easysite-article-content"]/ul/li') 13 print('========================================', len(news)) 14 items = [] 15 fp = open('./xml-4.xml', 'a', encoding='utf-8')#打开文件,不用手动创建 16 for new in news: 17 new_date = new.xpath('./span/text()').extract()[0] 18 new_title = new.xpath('.//div/span/a/@title').extract_first() 19 new_info = new.xpath('.//div/a/span/text()').extract_first() 20 new_link = 'https://www.chinalife.com.cn/' + new.xpath('.//div/span/a/@href').extract_first() 21 item = {} 22 item['date'] = new_date 23 item['title'] = new_title 24 item['info'] = new_info 25 item['link'] = new_link 26 27 28 29 fp.write(json.dumps(item))#写入文件 30 31 items.append(item) 32 print('+++++++++++++++++++++++++++++++', new_date, new_info, new_link, new_title,) 33 fp.close() 34 return items
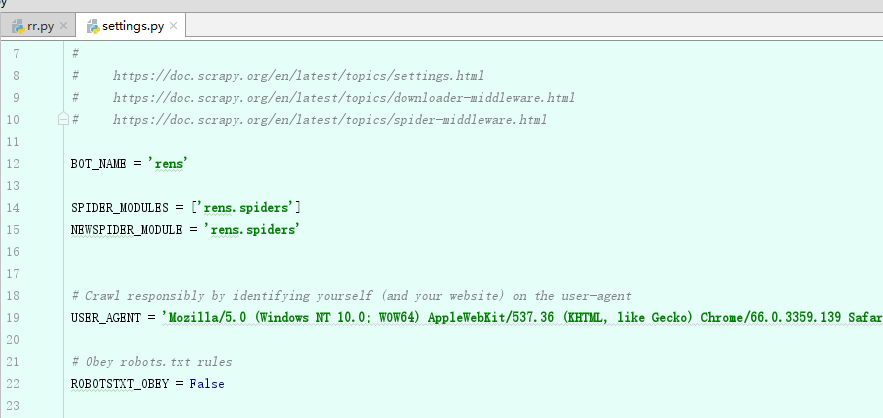
二、修改 setting中 USER_AGENT 和 ROBOTSTXT_OBEY
三、 终端 执行命令
1 scrapy crawl rr -o renshou.xml
# ('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')

欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加作者微信:tinghai87605025 或 QQ :87605025
python QQ交流群:py_data 483766429
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事多做几遍。。。。。。

