torch.nn.utils.clip_grad_norm_(parameters, max_norm, norm_type=2)
1.(引用:【深度学习】RNN中梯度消失的解决方案(LSTM) )
梯度裁剪原理:既然在BP过程中会产生梯度消失(就是偏导无限接近0,导致长时记忆无法更新),那么最简单粗暴的方法,设定阈值,当梯度小于阈值时,更新的梯度为阈值,如下图所示:
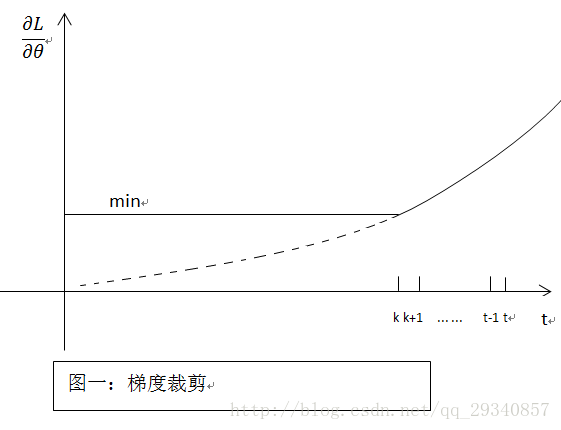
P.S.在原博中,评论中有提到,常用的梯度裁剪的方法是限制上限,针对梯度爆炸不收敛的情况,和作者写的相反。我理解的大概是“梯度裁剪解决的是梯度消失或爆炸的问题,即设定阈值”。
2. 函数定义:裁剪可迭代参数的渐变范数。范数是在所有梯度一起计算的,就好像它们被连接成单个矢量一样。渐变是就地修改的。
Parameters:
Returns:参数的总体范数(作为单个向量来看)(原文:Total norm of the parameters (viewed as a single vector).)