fluentd-pilot简介
fluentd-pilot是阿里开源的docker日志收集工具,Github项目地址:https://github.com/AliyunContainerService/fluentd-pilot 。你可以在每台机器上部署一个fluentd-pilot实例,就可以收集机器上所有Docker应用日志。
fluentd-pilot 具有如下特性:
- 一个单独的 fluentd 进程收集机器上所有容器的日志。不需要为每个容器启动一个 fluentd 进程。
- 支持文件日志和 stdout。docker log dirver 亦或 logspout 只能处理 stdout,fluentd-pilot 不仅支持收集 stdout 日志,还可以收集文件日志。
- 声明式配置。当您的容器有日志要收集,只要通过 label 声明要收集的日志文件的路径,无需改动其他任何配置,fluentd-pilot 就会自动收集新容器的日志。
- 支持多种日志存储方式。无论是强大的阿里云日志服务,还是比较流行的 elasticsearch 组合,甚至是 graylog,fluentd-pilot 都能把日志投递到正确的地点。
rancher使用fluentd-pilot收集日志
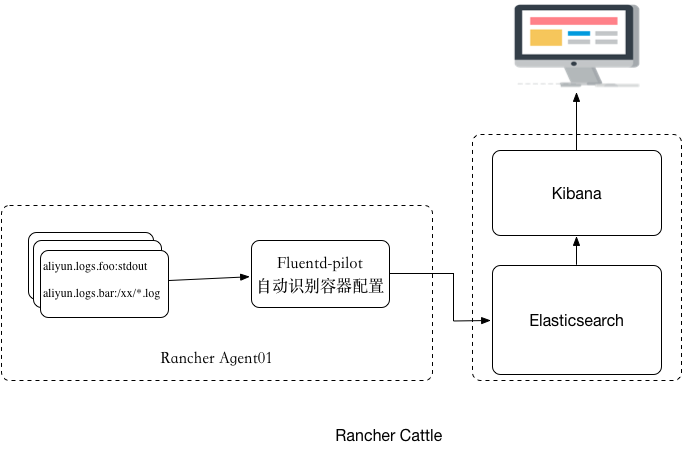
我们既然要用fluentd-pilot,就得先把它启动起来。还要有一个日志系统,日志要集中收集,必然要有一个中间服务去收集和存储,所以要先把这种东西准备好。Rancher中我们要如何做?如图,首先我们选择Rancher的应用商店中的Elasticsearch和Kibana。版本没有要求,下面使用Elasticsearch2.X和Kibana4。
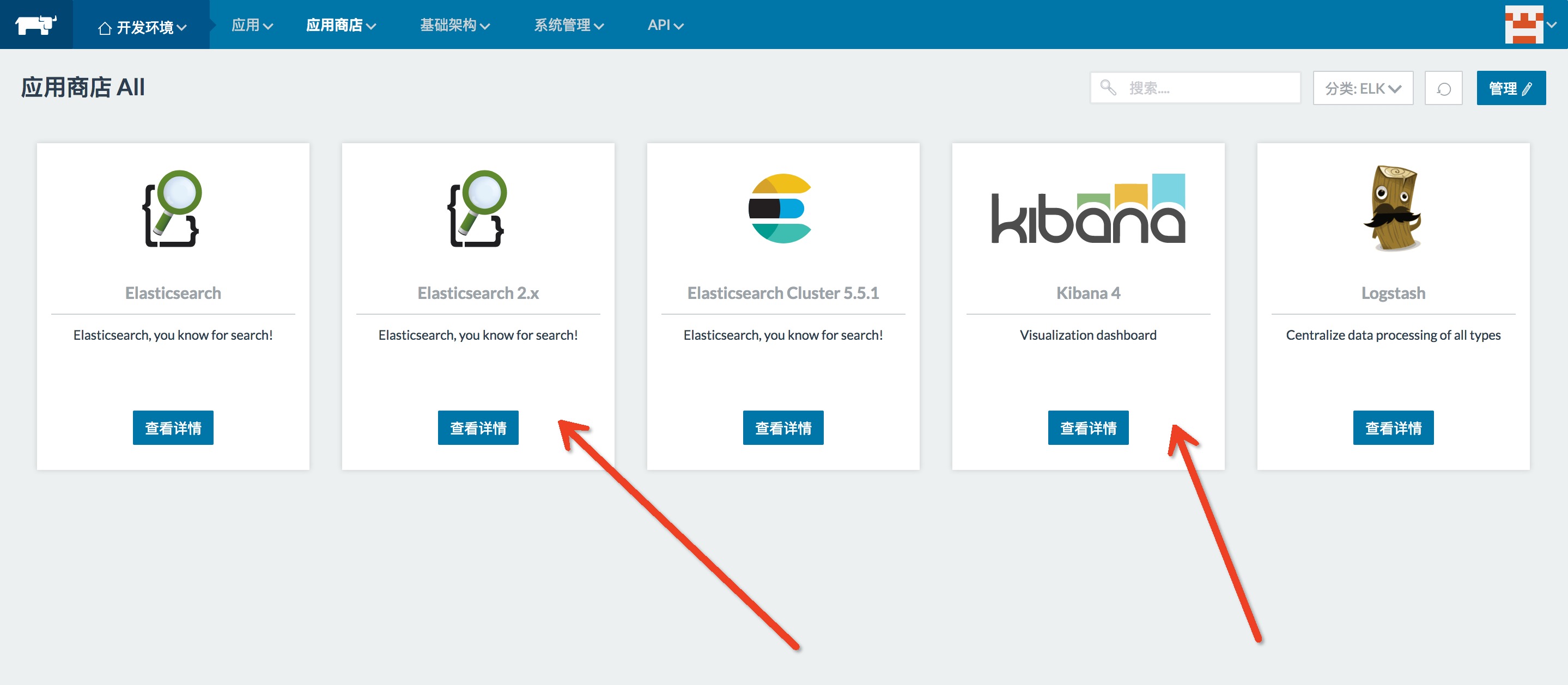
其次在RancherAgent主机上面部署一个fluentd-pilot容器,然后在容器里面启动的时候,我们要声明容器的日志信息,fluentd-pilot会自动感知所有容器的配置。每次启动容器或者删除容器的时候,它能够看得到,当看到容器有新容器产生之后,它就会自动给新容器按照你的配置生成对应的配置文件,然后去采集,最后采集回来的日志同样也会根据配置发送到后端存储里面去,这里面后端主要指的elasticsearch或者是SLS这样的系统,接下来你可以在这个系统上面用一些工具来查询等等。
可根据实际情况,在每台Agent定义主机标签,通过主机标签在每台RancherAgent主机上跑一个pilot容器。用这个命令来部署,其实现在它是一个标准的Docker镜像,内部支持一些后端存储,可以通过环境变量来指定日志放到哪儿去,这样的配置方式会把所有的收集到的日志全部都发送到elasticsearch里面去,当然两个挂载是需要的,因为它连接Docker,要感知到Docker里面所有容器的变化,它要通过这种方式来访问宿主机的一些信息。在Rancher环境下使用以下docker-compose.yml 应用---->添加应用,在可选docker-compose.yml中添加一下内容。
1 version: '2' 2 services: 3 pilot: 4 image: registry.cn-hangzhou.aliyuncs.com/acs-sample/fluentd-pilot:0.1 5 environment: 6 ELASTICSEARCH_HOST: elasticsearch 7 ELASTICSEARCH_PORT: '9200' 8 FLUENTD_OUTPUT: elasticsearch 9 external_links: 10 - es-cluster/es-master:elasticsearch 11 volumes: 12 - /var/run/docker.sock:/var/run/docker.sock 13 - /:/host 14 labels: 15 aliyun.global: 'true'
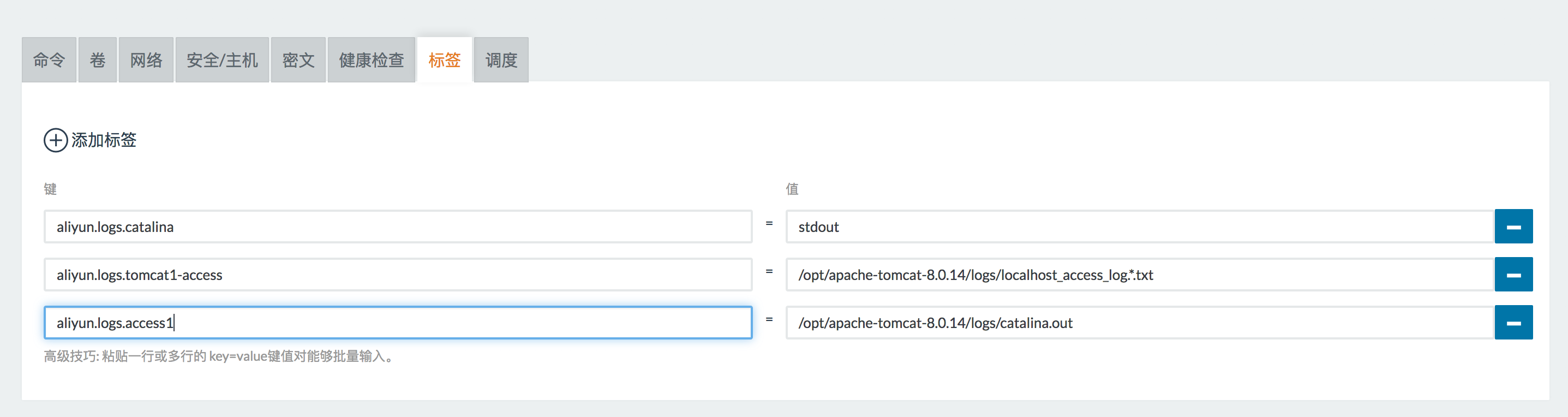
配置好之后启动自己的应用(例子:tomcat),我们看应用上面要收集的日志,我该在上面做什么样的声明?关键的配置有两个,一是label catalina,声明的是要收集容器的日志为什么格式(标准格式等,也可以是文件。),所有的名字都可以;二是声明access,这也是个名字,都可以用你喜欢的名字。这样一个路径的地址,当你通过这样的配置来去启动fluentd-pilot容器之后,它就能够感觉到这样一个容器的启动事件,它会去看容器的配置是什么,要收集这个目录下面的文件日志,然后告诉fluentd-pilot去中心配置并且去采集,这里还需要一个卷,实际上跟Logs目录是一致的,在容器外面实际上没有一种通用的方式能够获取到容器里面的文件,所有我们主动把目录从宿主机上挂载进来,这样就可以在宿主机上看到目录下面所有的东西。

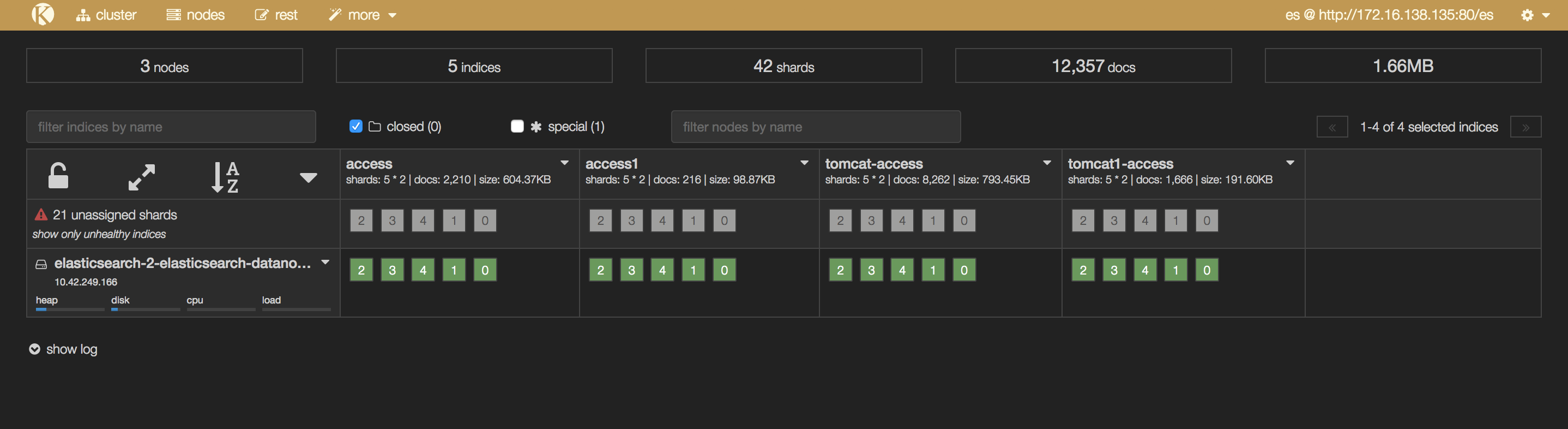
当你通过部署之后,他会自己在elasticsearch创建索引,就可以在elasticsearch的kopf上面看到会生成两个东西,都是自动创建好的,不用管一些配置,你唯一要做的事是什么呢?就可以在kibana上创建日志index pattern了。然后到日志搜索界面,可以看到从哪过来的,这条日志的内容是什么,这些信息都已经很快的出现了。
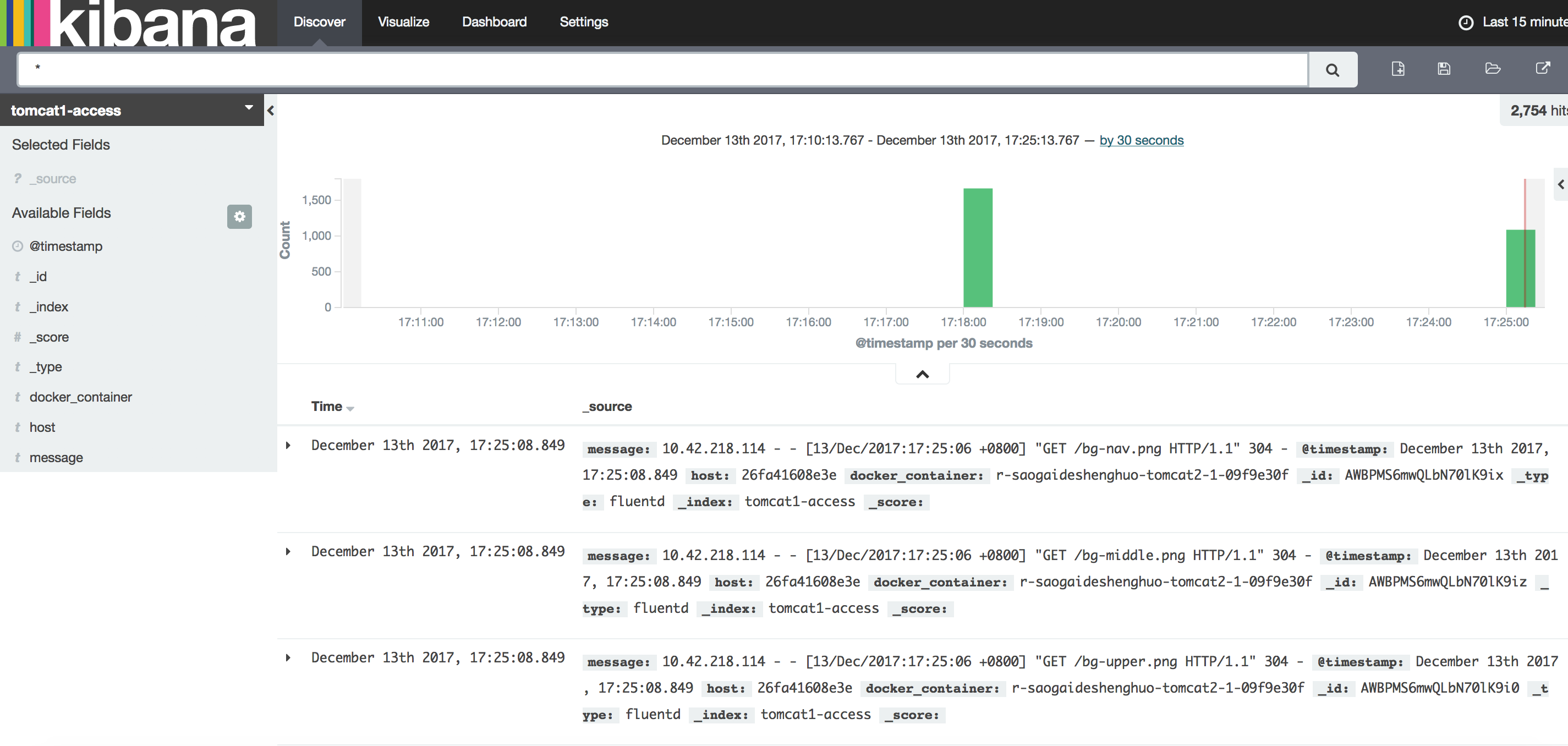
Lable说明
启动tomcat的时候,我们声明了这样下面两个,告诉fluentd-pilot这个容器的日志位置。
aliyun.logs.tomcat1-access /opt/apache-tomcat-8.0.14/logs/localhost_access_log.*.txt aliyun.logs.catalina stdout
你还可以在应用容器上添加更多的标签
aliyun.logs.$name = $path
- 变量name是日志名称,具体指随便是什么,你高兴就好。只能包含
0-9a-zA-Z_和- - 变量path是要收集的日志路径,必须具体到文件,不能只写目录。文件名部分可以使用通配符。
/var/log/he.log和/var/log/*.log都是正确的值,但/var/log不行,不能只写到目录。stdout是一个特殊值,表示标准输出
aliyun.logs.$name.format,日志格式,目前支持
- none 无格式纯文本
- json: json格式,每行一个完整的json字符串
- csv: csv格式
aliyun.logs.$name.tags: 上报日志的时候,额外增加的字段,格式为k1=v1,k2=v2,每个key-value之间使用逗号分隔,例如
aliyun.logs.access.tags="name=hello,stage=test",上报到存储的日志里就会出现name字段和stage字段- 如果使用elasticsearch作为日志存储,target这个tag具有特殊含义,表示elasticsearch里对应的index