一、何为扩展
预先设定
- 字符串S,长度为n
- 字符串T,长度为m
- 下标i从0开始
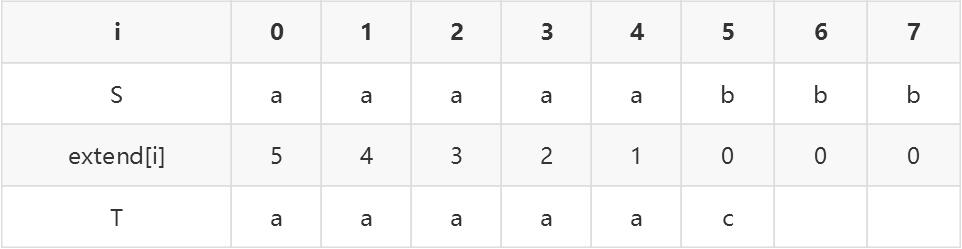
extend[i]表示:S[i]...S[n-1]与 T 的最长相同前缀的长度- 问题:求出所有的extend[i]
具体示例如下表所示:
KMP 算法的功能
- 如果在 S 的某个位置 i 有
extend[i]等于 m,则可知在 S 中找到了匹配串 T,并且匹配的首位置是 i; - 扩展 KMP 算法可以找到 S 中所有 T 的匹配。
二、扩展KMP算法
【算法流程】
1.
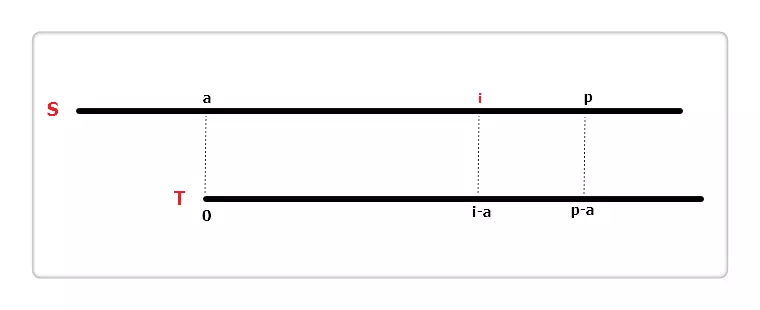
如上图,假设当前遍历到 S 串位置 i,即extend[0]...extend[i - 1]这 i 个位置的值已经计算得到。设置两个变量,a 和 p。p 代表以 a 为起始位置的字符匹配成功的最右边界,也就是 “p = 最后一个匹配成功位置 + 1”。相较于字符串 T 得出,S[a...p) 等于 T[0...p-a)。
再定义一个辅助数组int next[],其中next[i]含义为:T[i]...T[m - 1]与 T 的最长相同前缀长度,m 为串 T 的长度。
举个例子:

2.

椭圆的长度为next[i - a],对比 S 和 T,很容易发现,三个椭圆完全相同。如上图,此时i + next[i - a] < p,根据 next 数组的定义,此时extend[i] = next[i - a]。
3.
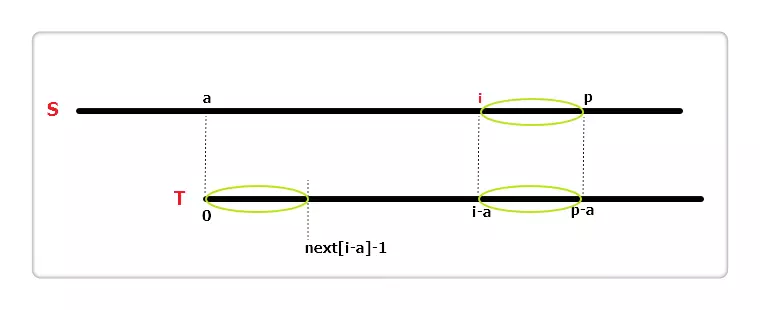
如果i + next[i - a] == p呢?如上图,三个椭圆都是完全相同的,此时我们可以直接从S[p]与T[p - i]开始往后匹配,加快了速度。
4.

如果i + next[i - a] > p呢?那说明S[i...p)与T[i-a...p-a)相同,这和i + next[i - a] == p的情况一样,我们直接从S[p]与T[p - i]开始往后匹配。(在以 a 为始的匹配中,S[p]与T[p-a]已经失配)
(5)最后,就是求解 next 数组。我们再来看下next[i]与extend[i]的定义:
next[i]: T[i]...T[m - 1]与 T 的最长相同前缀长度;
extend[i]: S[i]...S[n - 1]与 T 的最长相同前缀长度。
恍然大悟,求解next[i]的过程不就是 T 自己和自己的一个匹配过程嘛,下面直接看代码。
【代码】
#include<iostream>
#include<string>
using namespace std;
/* 求解 T 中 next[],注释参考 GetExtend() */
void GetNext(string & T, int & m, int next[])
{
int a = 0, p = 0;
next[0] = m;
for (int i = 1; i < m; i++)
{
if (i >= p || i + next[i - a] >= p)
{
if (i >= p)
p = i;
while (p < m && T[p] == T[p - i])
p++;
next[i] = p - i;
a = i;
}
else
next[i] = next[i - a];
}
}
/* 求解 extend[] */
void GetExtend(string & S, int & n, string & T, int & m, int extend[], int next[])
{
int a = 0, p = 0;
GetNext(T, m, next);
for (int i = 0; i < n; i++)
{
if (i >= p || i + next[i - a] >= p) // i >= p 的作用:举个典型例子,S 和 T 无一字符相同
{
if (i >= p)
p = i;
while (p < n && p - i < m && S[p] == T[p - i])
p++;
extend[i] = p - i;
a = i;
}
else
extend[i] = next[i - a];
}
}
int main()
{
int next[100];
int extend[100];
string S, T;
int n, m;
while (cin >> S >> T)
{
n = S.size();
m = T.size();
GetExtend(S, n, T, m, extend, next);
// 打印 next 和 extend
cout << "next: ";
for (int i = 0; i < m; i++)
cout << next[i] << " ";
cout << "
extend: ";
for (int i = 0; i < n; i++)
cout << extend[i] << " ";
cout << endl << endl;
}
return 0;
}
测试数据如下:
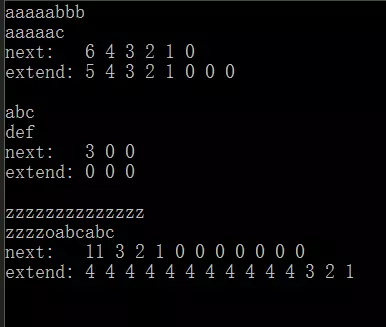
时间复杂度:对比 KMP 算法,很容易发现时间复杂度为 Θ(n+m)。