一、介绍
哈希表是根据关键字(Key)而直接访问记录的数据结构。它通过把关键字映射到哈希表中的一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做哈希表。
散列函数:将记录的关键字映射到该记录在哈希表中的存储位置,即f(关键字) = 记录的存储位置
示例:以查新华字典为例,假设我们要查看“猪”的详细信息,我们一般会根据拼音“zhu”去查找拼音索引,通过拼音索引我们得到了“zhu”在字典中的页码数。其中,拼音索引就是散列函数,“zhu”就是关键字,查到的页码值就是哈希值,而“猪”的详细信息则是我们所要访问的记录。
二、哈希冲突
哈希冲突:当key1≠key2时,却有f(key1) = f(key2) 。
三、拉链法
当发生哈希冲突时,我们通过两个不同的关键字,将访问到同一个记录。既然它们在哈希表中的存储位置相同,那我们可以在该位置引出一个链表,将所有根据散列函数定位到该存储位置的记录都插入到该链表上。
这是哈希表最常用的一种实现方法,可以理解为“链表的数组”,其具有以下优点:
a.寻址容易(数组的特点)
b.插入和删除容易(链表的特点)
所以查找、插入、删除(有时包括删除)可以达到O(1)。
示例:现有一堆数据{1, 12, 26, 337, 353...},散列函数是H(key)=key mod 16。第一个数据1的哈希值f(1)=1,插入到1结点的后面;第二个数据12的哈希值f(12)=12,插入到12结点的后面;第三个数据26的哈希值f(26)=10,插入到10结点的后面;第4个数据337的哈希值f(key)=1,发生哈希冲突,插入到1结点对应的链表的末尾;同理,第5个数据353的哈希值f(key)=1,插入到1结点对应的链表的末尾。
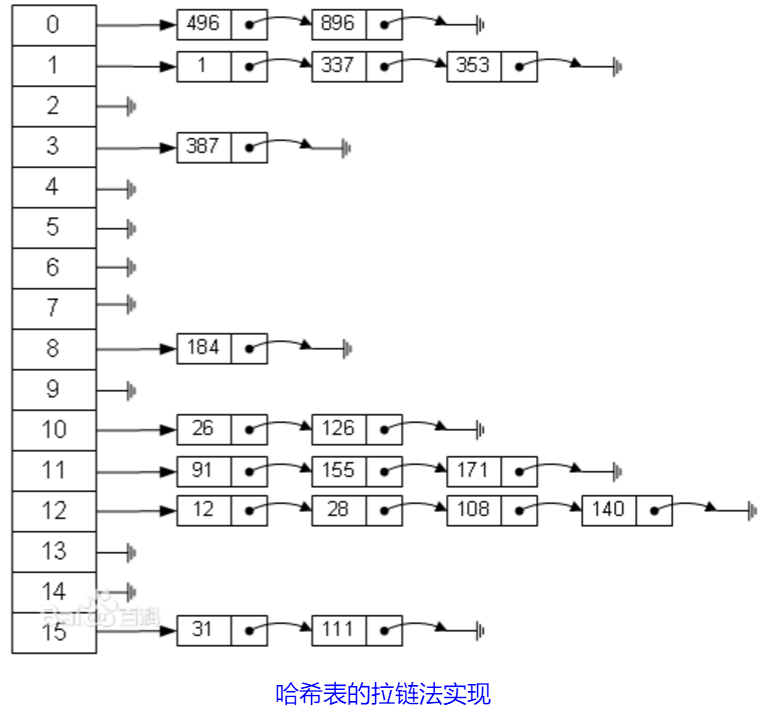
左边很明显是个数组,数组的每个成员含有一个指针,指向一个链表的头,当然这个链表可能为空,也可能有很多元素。
这种实现存在最坏的情况,就是散列值全都映射到同一个地址上,这样哈希表就会退化成链表,查找的时间复杂度变成O(n)。这就需要我们设计一个好的散列函数,不仅要计算简单,而且计算得到的散列值应分布均匀,从而避免退化成链表。
四、设计好的散列函数
散列函数可以将关键字(以下简称键)转化为数组的索引。如果我们有一个能保存M个键值对的数组,那么我们就需要一个能够将任意键转化为该数组范围内的索引([0, M-1]范围内的整数)的散列函数。
一个好的散列函数应该易于计算并且能够均匀分布所有的键,即对于任意键,0到M-1之间的每个整数都有相等的可能性与之对应(与键无关)。
散列函数和键的类型有关,严格地说,对于每种类型的键我们都需要一个与之对应的散列函数。
例如:如果键是一个数,比如身份证号,我们就可以直接使用这个数;如果键是一个字符串,比如一个人的名字,我们就需要将这个字符串转化为一个数;如果键含有多个部分,比如邮件地址,我们需要用某种方法将这些部分结合起来。
注:讨论多种数据类型的散列函数是有必要的,因为我们也需要为自己定义的类型实现散列函数。
1. 正整数——除留余数法
将正整数散列,我们可以选择大小为素数M的数组,对于任意正整数k,计算k除以M的余数。即f(k) = k % M。
评价:这个散列函数的计算非常容易并能够有效地将键散布在0到M-1的范围内。
为什么数组的大小M选用素数?
如果M不是素数,我们可能无法利用键中包含的所有信息,这可能导致我们无法均匀地散列散列值。
比如,如果键是十进制数而M为10k,那么我们只能利用键的后k位,这可能会产生一些问题。如M=100,而键的取值范围为{101, 201, 301, 302, 4002, 50013},这样得到的散列值为{1, 1, 1, 2, 2, 13},很显然,我们仅能利用键的后2位,并且散列值存在大量重复。此时,如果M为素数,则散列值的分布将更均匀。
2. 字符串
此种情况下仍可使用除留余数法。只要将字符串当作大整数即可。
我们可以这样计算它的散列值:for(int i = 0; i < s.length(); ++i) hash = (R * hash + s[i]) % M
只要R足够小不造成溢出,那么就可以得到一个0至M-1之间的散列值。
3. 组合键
当键的类型含有多个整型变量时,我们可以和string类型一样将它们混合起来。
如被查找的键的类型是Date,其中含有几个整型的域:day(两个数字表示), month(两个数字表示)和year(4个数字表示)。
于是可以这样计算它的散列值:int hash = (((day * R + month) % M ) * R + year) % M
只要R足够小不造成溢出,就可以得到一个0至M-1之间的散列值。
五、余音绕梁
1. 理解术语“哈希表”、“散列表”、“哈希函数”、“散列函数”、“哈希值”、“散列值”
哈希表 = 散列表;哈希函数 = 散列函数;哈希值 = 散列值。
2. 一句话阐明哈希表的存储与查找
当存储记录时,通过散列函数计算出记录的散列地址;
当查找记录时,我们通过同样的是散列函数计算记录的散列地址,并按此散列地址访问该记录。