- 有时候我们start-dfs.sh启动了hadoop但是发现datanode进程不存在
一、原因
当我们使用hadoop namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件中dfs.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID,这样,datanode和namenode之间的ID不一致。
二、解决方法
-
第一种:如果dfs文件夹中没有重要的数据,那么删除dfs文件夹,再重新运行下列指令: (删除节点下的dfs文件夹,为自己配置文件中dfs.name.dir的路径)
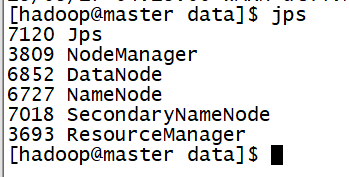
-
第二种:如果dfs文件中有重要的数据,那么在dfs/name目录下找到一个current/VERSION文件,记录clusterID并复制。然后dfs/data目录下找到一个current/VERSION文件,将其中clustreID的值替换成刚刚复制的clusterID的值即可;
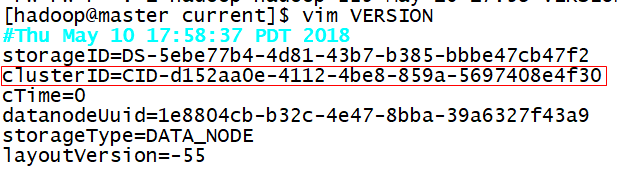
三、总结
其实,每次运行结束Hadoop后,都应该关闭Hadoop. stop-dfs.sh
下次想重新运行Hadoop,不用再格式化namenode,直接启动Hadoop即可 start-dfs.sh