1. MapReduce使用
MapReduce是Hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现
一个强大的海量数据并发处理程序
2. 运行Hadoop自带的MapReduce程序(word count单词统计功能)
1.在HDFS中创建层级目录,并且上传文件到指定目录:hadoop fs -mkdir -p /wordcount/input

2.上传文件到HDFS指定目录:hadoop fs -put a.txt b.txt /wordcount/input

3.运行MapReduce程序的自带jar包:cd /usr/local/src/hadoop-2.6.4/share/hadoop/mapreduce/
运行:hadoop jar hadoop-mapreduce-examples-2.6.4.jar wordcount /wordcount/input /wordcount/output
wordcount:jar包中需要运行的主类
/wordcount/input:wordcount主类需要的参数,指定数据文件目录,统计里面的数据文件
/wordcount/output:统计文件后的结果保存目录,必须要求改目录不存在
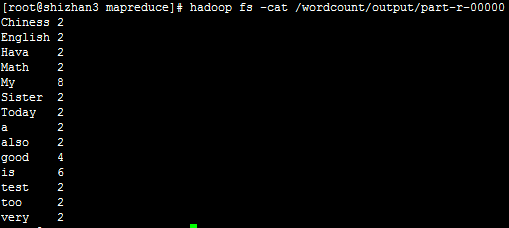
4.查看输出文件统计结果:hadoop fs -cat /wordcount/output/part-r-00000
自己写MapReduce程序可参考这篇用MapReduce计算Pi的文章http://blog.csdn.net/mrbcy/article/details/61455917